溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關如何調用HashMap原理以及put方法和get方法,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
HashMap的數據結構為數組+鏈表,以key,value的形式存值,通過調用put與get方法來存值與取值。
它內部維護了一個Entry數組,得到key的hashCode值將其移位按位與運算,然后再通過跟數組的長度-1作邏輯與運算得到一個index值來確定數據存儲在Entry數組當中的位置,通過鏈表來解決hash沖突問題。
當發生碰撞了,對象將會儲存在鏈表的下一個節點中。
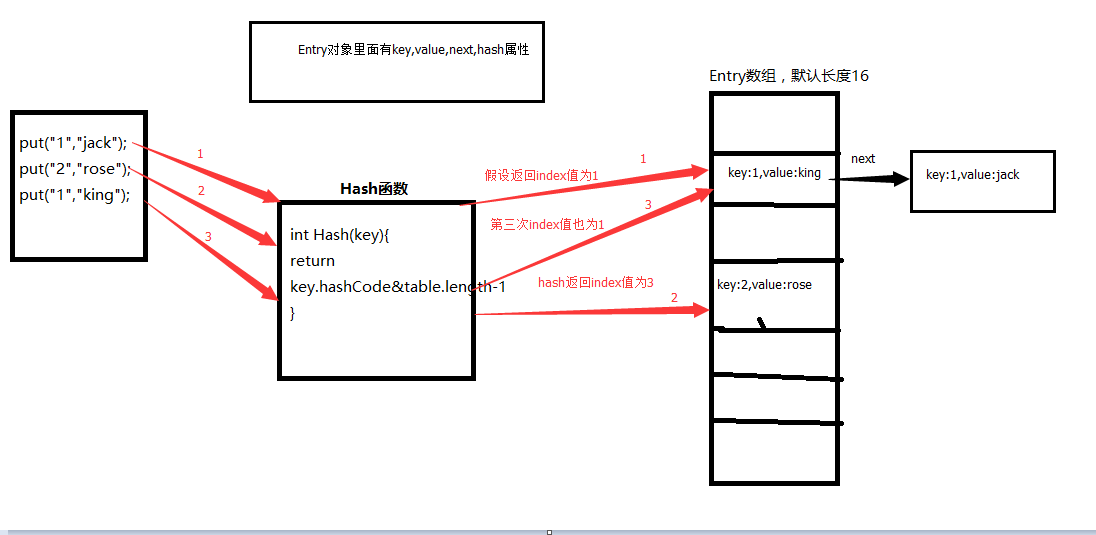
接觸過HashMap的小伙伴都會經常使用put和get這些方法,那接下來就對HashMap的內部存儲進行詳解.(以初學者的角度進行分析)-(小白篇)
當程序試圖將多個 key-value 放入 HashMap 中時,以如下代 碼片段為例:

上面代碼,創建了一個HashMap對象,并且指定了容量(capacity)和負載因子(loadFactor),然后put,以鍵值對的方式儲存值. 容量咱們很容易理解(默認16容量),也就是給它一個初始化的長度,那么負載因子又是個啥?
負載因子 : 表示HashMap滿的程度,默認值為0.75f,也就是說默認情況下,當HashMap中元素個數達到了容量的3/4的時候就會進行自動擴容.(這里我把負載因子設置到0.9f,這么做的原因是想讓"效果"更明顯,啥效果,后面講解.) 具體擴容多少,源碼有這樣一段代碼如下:
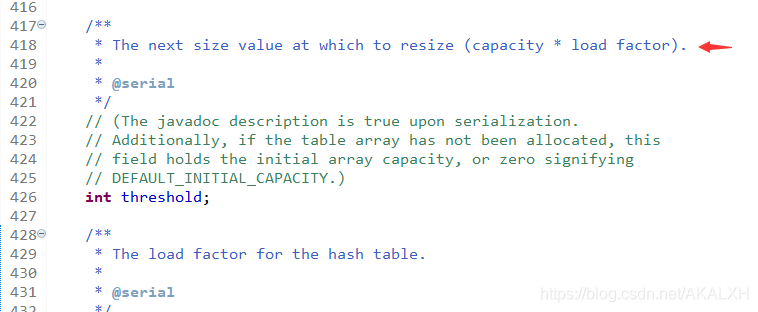
我們從這里可以知道閾(yu)值的計算公式:
閾值(threshold) = 負載因子(loadFactor) * 容量(capacity)
來,上源碼 如下:
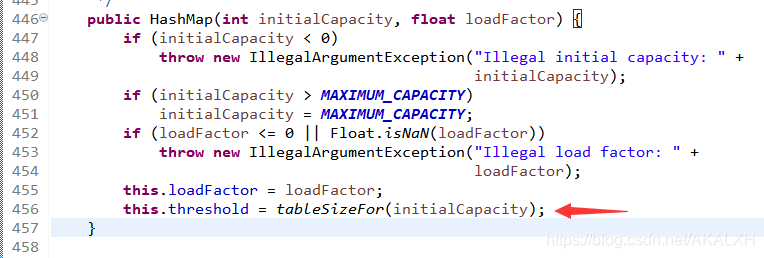
這是源碼的構造函數,來看看最后一行代碼用 tableSizeFor(initialCapacity) 方法來計算出閾值,
查看此方法源碼 如下:
 cap
cap
參數也就是給的初始容量,這段算法會給出一個距離參數cap 最近的并且沒有變小的 2 的冪次方數,比如傳入10 返回 16,就是這么神奇!
以上我們了解了HashMap的擴容機制,也知道了創建一個HashMap對象的內部活動. 下面我們對put添加一個鍵值對的方法進行解析.
我們知道HashMap是以key-value的形式保存的,取用get()方法查找key來獲取相對應的value. 我們可以調試put值時看出HashMap底層是用數組構成的,并且存放的位置是散列無序的,這點不像數組按存放的先后順序來排列.如下圖:
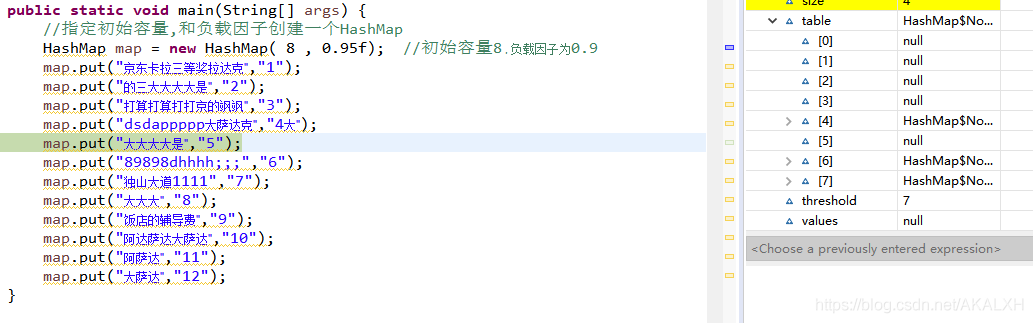
當put完第4個值時發現只顯示了3個元素,之后一個個點開元素后發現,第4個元素出現在next這個屬性中. 如下圖:
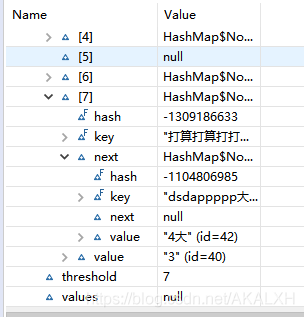
然后繼續put完全部值,在看,一共存放了12個值,但是table中只有9個元素,還發現閾(yu)[ threshold ]值從最初的7增加到了15,容量(capacity)也從原來給的8變成了16,說明觸發了擴容機制(從源代碼可看到容量擴充至原來的二倍),在一個我們剛剛發現了有些值跑到了另一些值的next屬性里去了.我們點開元素的next屬性看看,是不是跑到這里頭了.如下圖:
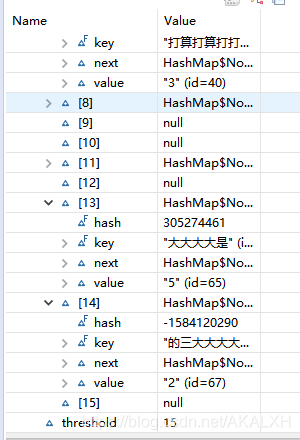
果然,這三倆跑人家的底盤來了.在下標 7,13,14中的Next的屬性中找到了"遺失"的三個元素.
在看如下圖:
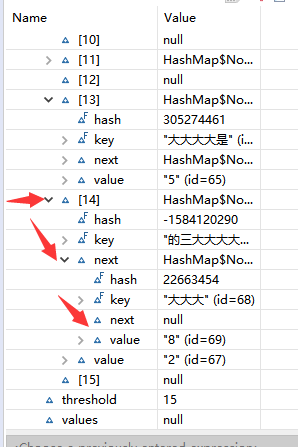
仔細瞅瞅,發現每個元素都有這么一個next的屬性,有些為空,有些不為空,不為空的則是元素存放在此next中,有沒有感覺元素被next屬性組成了一條鏈子.來上圖(形象又生動):
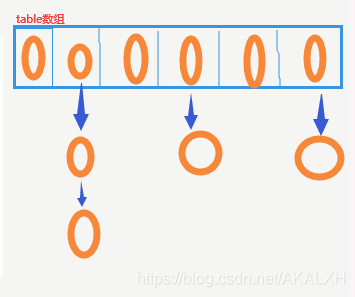
此圖模擬了內部的結構方式,在同一下標中同時存在多個元素,產生了鏈表結構圖中的箭頭也就表示著每個元素中的next屬性,看到這會發現許多詭異所思的問題, 為啥它存儲是無序的呢? , 為啥存著存著都跑到一塊去了,成了鏈表結構呢?,等一些問題.咱們下面通過源碼來看看.(源碼如下):
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}既然叫HashMap,當然得和Hash扯點關系啦.
HashMap 采用一種所謂的“Hash 算法”來決定每個元素的存儲位置。當程序執行 map.put(String,Obect)方法 時,系統將調用String的 hashCode() 方法得到其 hashCode 值——每個 Java 對象都有 hashCode() 方法,都可通過該方法獲得它的 hashCode 值。得到這個對象的 hashCode 值之后,系統會根據該 hashCode 值來決定該元素的存儲位置。小伙伴可以試試調用hashCode()方法看看經過此算法會得出怎樣的結果.
咱們現在知道為啥是無序存放的了,key通過哈希算法的值來決定它存儲的位置,那出現的重疊現象表明,不同的key經過哈希算法得出的值會出現相等的可能(這樣的現狀稱為碰撞/沖突),所以一個下標會出現多個元素,形成鏈表結構.至于為什么采用鏈表,是為了節省空間,鏈表在內存中并不是連續存儲,所以我們可以更充分地使用內存。
(下面我們將每個下標統稱為Entry(桶),也就是一個 key-value 對)
有沒有覺得這樣會降低查詢的效率(鏈表),進行查詢時,先查找到Entry,在通過鏈的遍歷.想著都覺得麻煩,雖然這樣解決了碰撞這樣的沖突,但是引來了一個大毛病(查找效率降低),這得不行啊,人家HashMap同志就是以快出名啊,所以在jdk8中進行了優化, 引入了樹結構,在鏈表長度大于8的時候,將后面的數據存在紅黑樹中,以加快檢索速度,,來優化 鏈 過長所帶來的性能低化的問題.
來上碼,繼續查看putVal(hash(key), key, value, false, true); 的源碼:
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}咱們看完注釋應該了解它的大概了,繼續查看treeifyBin()將鏈表改為紅黑樹 (jdk8新特性)方法碼:
/**
* Replaces all linked nodes in bin at index for given hash unless
* table is too small, in which case resizes instead.
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 如果數組等于null 或 數組長度小于 64
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
// 重新散列,使得鏈表變短
resize();
// 如果hash沖突,且數組長度大于 64,則只能使用紅黑樹結構
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
// 返回新的紅黑樹
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}以上介紹了MashMap對存儲數據的機制進行簡短的介紹.我們已經知道產生碰撞會導致查詢效率打折扣,那么如何能有效的避免哈希碰撞呢?
咱們先反向思維一下,你認為什么情況會導致HashMap的哈希碰撞比較多?
無外乎兩種情況:
1、容量太小。容量小,碰撞的概率就高了。狼多肉少,就會發生爭強。
2、hash算法不夠好。算法不合理,就可能都分到同一個或幾個桶中。分配不均,也會發生爭搶。
所以,解決HashMap中的哈希碰撞也是從這兩方面入手。
這兩點在HashMap中都有很好的提現。兩種方法相結合,在合適的時候擴大數組容量,再通過一個合適的hash算法計算元素分配到哪個數組中,就可以大大的減少沖突的概率。但數據量大時,碰撞也會成正比的增長,所以引入紅黑樹的結構,就能避免查詢效率低下的問題。
咱們再來看看負載因子這個影響性能的平衡點有啥規律.上文已經對啥是負載因子進行了解釋.
它Hsah表中元素的填滿的程度.
若:加載因子越大,填滿的元素越多,好處是,空間利用率高了,但:沖突的機會加大了.鏈表長度會越來越長,查找效率降低。
反之,加載因子越小,填滿的元素越少,好處是:沖突的機會減小了,但:空間浪費多了.表中的數據將過于稀疏(很多空間還沒用,就開始擴容了)
沖突的機會越大,則查找的成本越高.
因此,必須在 "沖突的機會"與"空間利用率"之間尋找一種平衡與折衷. 這種平衡與折衷本質上是數據結構中有名的"時-空"矛盾的平衡與折衷.
這里寫了段測試代碼 如下:
public class HashTest {
public static void main(String[] args) {
// 對"負載因子的大小對程序的影響規律"進行測試
// threshold=capacity * loadFactor ---- 閾值 = 容量 x 負載因子
// 源代碼擴容后容量是擴容前的二倍
int n1 = 10; // 對照組
int n2 = 1000000; // put/get多少組
long t0 = 0; //總耗時
float lf = 0.9f; //負載因子
int capacity = 100; //初始容量
HashMap map = null;
//對照組循環
for (int j = 1; j <= n1; j++) {
map = new HashMap(capacity, lf);
List<String> list = new ArrayList<String>();
// 利用循環進行put
for (int i = 0; i < n2; i++) {
String temp = HashTest.randomString();
map.put(temp, i);
list.add(temp);
}
long time = 0; // 總耗費時間
// 利用循環get
for (int i = 0; i < n2; i++) {
String temp = list.get(i);
long t1 = System.currentTimeMillis();
map.get(temp);
long t2 = System.currentTimeMillis();
long t3 = t2 - t1;// 花費時間
time += t3;
}
System.out.println("組"+j+"花費時間(ms)=" + time);
t0 += time;
map = null;
}
System.out.println("get出 "+n2+" 對鍵值對中,"+n1+"組數據得出:");
System.out.println("---------------------------------");
System.out.println("每get"+n2+"對鍵值對 平均花費時間(毫秒):"+(t0/n1));
}
/**
* 產生隨機字符串方法
* @return
*/
public static String randomString() {
// 最終產生的字符串
StringBuffer sb = new StringBuffer();
// 字符串樣本
String str = "回到家卡薩恒大帝景阿薩德節快樂就看見了困窘企業無辜的鄙視你別這么想按一個預告的哈上東國際按時大大伽伽匯頂科技啊啥看的撒打算大的歐亞報出去qwertyuiopasdfghjklzxvcbnm,.;p[']/\1234567890zxcvbnmaksjhfgdlpoiuytrewq阿斯加德克拉斯近段時間的書上方法更符合輔導費的冠福股份極樂空間流口水";
// System.out.println("樣本字符串長度:"+str.length());
// 產生一個1到30的數字
int num = (int) (Math.random() * 30 + 1);
// System.out.println("num="+num);
// 用for循環從樣本字符串中提取出字符進行組合
for (int i = 0; i < num; i++) {
int num1 = (int) (Math.random() * str.length()); // 產生一個0到字符串樣本的數字
// 根據索引值獲取對應的字符
char charAt = str.charAt(num1);
sb.append(charAt);
}
// System.out.println("產生一個長度為"+num+"的字符串");
return sb.toString();
}小伙伴可以調節負載因子的大小來測試,時間上的差異.
以上就是如何調用HashMap原理以及put方法和get方法,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





