溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“python beautiful soup庫的詳細安裝教程”,在日常操作中,相信很多人在python beautiful soup庫的詳細安裝教程問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”python beautiful soup庫的詳細安裝教程”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
beautiful soup庫的安裝
beautiful soup庫的理解
beautiful soup庫的引用
BeautifulSoup類
回顧demo.html
Tag標簽
Tag的attrs(屬性)
Tag的NavigableString
HTML基本格式
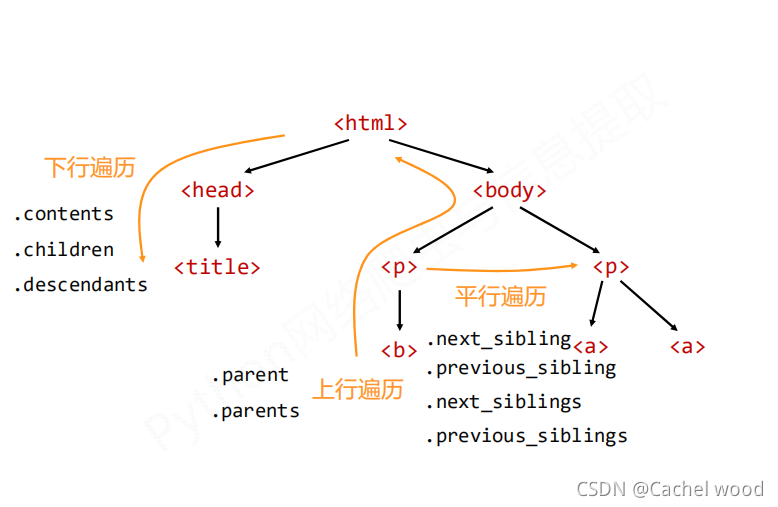
標簽樹的下行遍歷
標簽樹的上行遍歷
標簽的平行遍歷
bs庫的prettify()方法
bs4庫的編碼
pip install beautifulsoup4
beautiful soup庫是解析、遍歷、維護“標簽樹”的功能庫
from bs4 import BeautifulSoup import bs4
BeautifulSoup對應一個HTML/XML文檔的全部內容
import requests
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
print(demo)<html><head><title>This is a python demo page</title></head> <body> <p class="title"><b>The demo python introduces several python courses.</b></p> <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p> </body></html>
| 基本元素 | 說明 |
|---|---|
| Tag | 標簽,最基本的信息組織單元,分別用<>和</>標明開頭和結尾 |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.title)
tag = soup.a
print(tag)<title>This is a python demo page</title> <a href="http://www.icourse163.org/course/BIT-268001" >Basic Python</a>
任何存在于HTML語法中的標簽都可以用soup.訪問獲得。當HTML文檔中存在多個相同對應內容時,soup.返回第一個
| 基本元素 | 說明 |
|---|---|
| Name | 標簽的名字, … 的名字是'p',格式:.name |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.a.name)
print(soup.a.parent.name)
print(soup.a.parent.parent.name)a p body
| 基本元素 | 說明 |
|---|---|
| Attributes | 標簽的屬性,字典形式組織,格式:.attrs |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
tag = soup.a
print(tag.attrs)
print(tag.attrs['class'])
print(tag.attrs['href'])
print(type(tag.attrs))
print(type(tag)){'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
['py1']
http://www.icourse163.org/course/BIT-268001
<class 'dict'>
<class 'bs4.element.Tag'>Tag的NavigableString
| 基本元素 | 說明 |
|---|---|
| NavigableString | 標簽內非屬性字符串,<>…</>中字符串,格式:.string |
Tag的Comment
| 基本元素 | 說明 |
|---|---|
| Comment | 標簽內字符串的注釋部分,一種特殊的Comment類型 |
import requests
from bs4 import BeautifulSoup
newsoup = BeautifulSoup("<b><!--This is a comment--></b><p>This is not a comment</p>","html.parser")
print(newsoup.b.string)
print(type(newsoup.b.string))
print(newsoup.p.string)
print(type(newsoup.p.string))This is a comment <class 'bs4.element.Comment'> This is not a comment <class 'bs4.element.NavigableString'>
| 屬性 | 說明 |
|---|---|
| .contents | 子節點的列表,將所有兒子結點存入列表 |
| .children | 子節點的迭代類型,與.contents類似,用于循環遍歷兒子結點 |
| .descendents | 子孫節點的迭代類型,包含所有子孫節點,用于循環遍歷 |
BeautifulSoup類型是標簽樹的根節點
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.head)
print(soup.head.contents)
print(soup.body.contents)
print(len(soup.body.contents))
print(soup.body.contents[1])<head><title>This is a python demo page</title></head> [<title>This is a python demo page</title>] ['\n', <p ><b>The demo python introduces several python courses.</b></p>, '\n', <p >Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a href="http://www.icourse163.org/course/BIT-268001" >Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" >Advanced Python</a>.</p>, '\n'] 5 <p ><b>The demo python introduces several python courses.</b></p>
for child in soup.body.children: print(child) #遍歷兒子結點 for child in soup.body.descendants: print(child) #遍歷子孫節點
| 屬性 | 說明 |
|---|---|
| .parent | 節點的父親標簽 |
| .parents | 節點先輩標簽的迭代類型,用于循環遍歷先輩節點 |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.title.parent)
print(soup.html.parent)<head><title>This is a python demo page</title></head> <html><head><title>This is a python demo page</title></head> <body> <p ><b>The demo python introduces several python courses.</b></p> <p >Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a href="http://www.icourse163.org/course/BIT-268001" >Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" >Advanced Python</a>.</p> </body></html>
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)p body html [document]
| 屬性 | 說明 |
|---|---|
| .next_sibling | 返回按照HTML文本順序的下一個平行節點標簽 |
| .previous.sibling | 返回按照HTML文本順序的上一個平行節點標簽 |
| .next_siblings | 迭代類型,返回按照HTML文本順序的后續所有平行節點標簽 |
| .previous.siblings | 迭代類型,返回按照HTML文本順序的前續所有平行節點標簽 |
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.a.next_sibling)
print(soup.a.next_sibling.next_sibling)
print(soup.a.previous_sibling)
print(soup.a.previous_sibling.previous_sibling)
print(soup.a.parent)and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a> Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: None <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
for sibling in soup.a.next_sibling: print(sibling) #遍歷后續節點 for sibling in soup.a.previous_sibling: print(sibling) #遍歷前續節點
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.prettify())<html> <head> <title> This is a python demo page </title> </head> <body> <p class="title"> <b> The demo python introduces several python courses. </b> </p> <p class="course"> Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: Basic Python </a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2"> Advanced Python </a> . </p> </body> </html>
.prettify()為HTML文本<>及其內容增加更加'\n'
.prettify()可用于標簽,方法:.prettify()
bs4庫將任何HTML輸入都變成utf-8編碼
python 3.x默認支持編碼是utf-8,解析無障礙
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>中文</p>","html.parser")
print(soup.p.string)
print(soup.p.prettify())中文 <p> 中文 </p>
到此,關于“python beautiful soup庫的詳細安裝教程”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





