溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Java的內存模型講解”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Java的內存模型講解”吧!
Java 內存模型定義如下:
內存模型限制的是共享變量,也就是存儲在堆內存中的變量,在 Java 語言中,所有的實例變量、靜態變量和數組元素都存儲在堆內存之中。而方法參數、異常處理參數這些局部變量存儲在方法棧幀之中,因此不會在線程之間共享,不會受到內存模型影響,也不存在內存可見性問題。
通常,在線程之間的通訊方式有共享內存和消息傳遞兩種,很明顯,Java 采用的是第一種即共享的內存模型,在共享的內存模型里,多線程之間共享程序的公共狀態,通過讀-寫內存的方式來進行隱式通訊。
從抽象的角度來看,JMM 其實是定義了線程和主內存之間的關系,首先,多個線程之間的共享變量存儲在主內存之中,同時每個線程都有一個自己私有的本地內存,本地內存中存儲著該線程讀或寫共享變量的副本(注意:本地內存是 JMM 定義的抽象概念,實際上并不存在)。抽象模型如下圖所示:
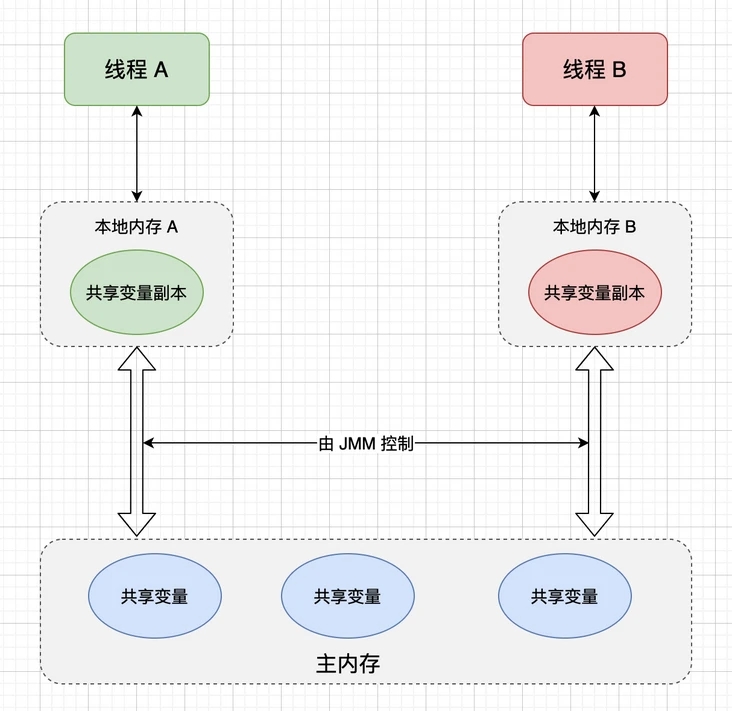
在這個抽象的內存模型中,在兩個線程之間的通信(共享變量狀態變更)時,會進行如下兩個步驟:
線程 A 把在本地內存更新后的共享變量副本的值,刷新到主內存中。
線程 B 在使用到該共享變量時,到主內存中去讀取線程 A 更新后的共享變量的值,并更新線程 B 本地內存的值。
JMM 本質上是在硬件(處理器)內存模型之上又做了一層抽象,使得應用開發人員只需要了解 JMM 就可以編寫出正確的并發代碼,而無需過多了解硬件層面的內存模型。
在日常的程序開發中,為一些共享變量賦值的場景會經常碰到,假設一個線程為整型共享變量 count 做賦值操作(count = 9527;),此時就會有一個問題,其它讀取該共享變量的線程在什么情況下獲取到的變量值為 9527 呢?如果缺少同步的話,會有很多因素導致其它讀取該變量的線程無法立即甚至是永遠都無法看到該變量的最新值。
比如緩存就可能會改變寫入共享變量副本提交到主內存的次序,保存在本地緩存的值,對于其它線程是不可見的;編譯器為了優化性能,有時候會改變程序中語句執行的先后順序,這些因素都有可能會導致其它線程無法看到共享變量的最新值。
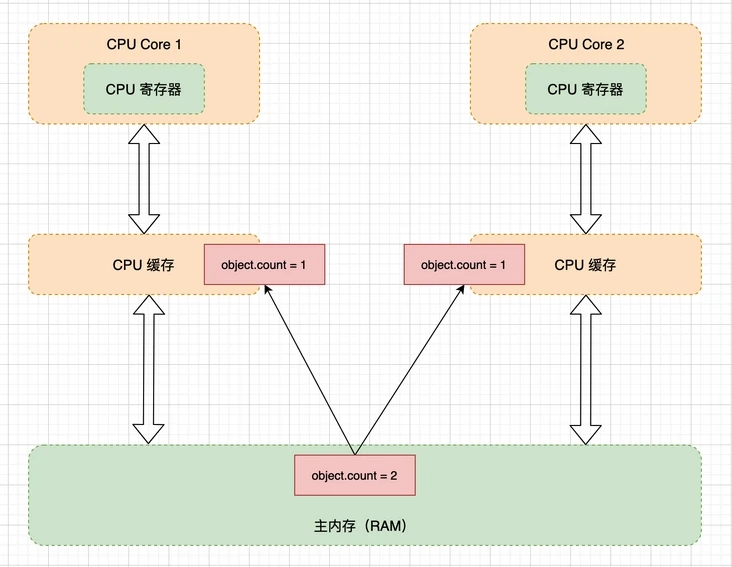
在文章開頭,提到了 JMM 主要是為了解決可見性和有序性問題,那么首先就要先搞清楚,導致可見性和有序性問題發生的本質原因是什么?現在的服務絕大部分都是運行在多核 CPU 的服務器上,每顆 CPU 都有自己的緩存,這時 CPU 緩存與內存的數據就會有一致性問題了,當一個線程對共享變量的修改,另外一個線程無法立刻看到。導致可見性問題的本質原因是緩存。
有序性是指代碼實際的執行順序和代碼定義的順序一致,編譯器為了優化性能,雖然會遵守 as-if-serial 語義(不管怎么重排序,在單線程下的執行結果不能改變),不過有時候編譯器及解釋器的優化也可能引發一些問題。比如:雙重檢查來創建單實例對象。下面是使用雙重檢查來實現延遲創建單例對象的代碼:
/**
* @author mghio
* @since 2021-08-22
*/
public class DoubleCheckedInstance {
private static DoubleCheckedInstance instance;
public static DoubleCheckedInstance getInstance() {
if (instance == null) {
synchronized (DoubleCheckedInstance.class) {
if (instance == null) {
instance = new DoubleCheckedInstance();
}
}
}
return instance;
}
}這里的 instance = new DoubleCheckedInstance();,看起來 Java 代碼只有一行,應該是無法就行重排序的,實際上其編譯后的實際指令是如下三步:
分配對象的內存空間
初始化對象
設置 instance 指向剛剛已經分配的內存地址
上面的第 2 步和第 3 步如果改變執行順序也不會改變單線程的執行結果,也就是說可能會發生重排序,下圖是一種多線程并發執行的場景:
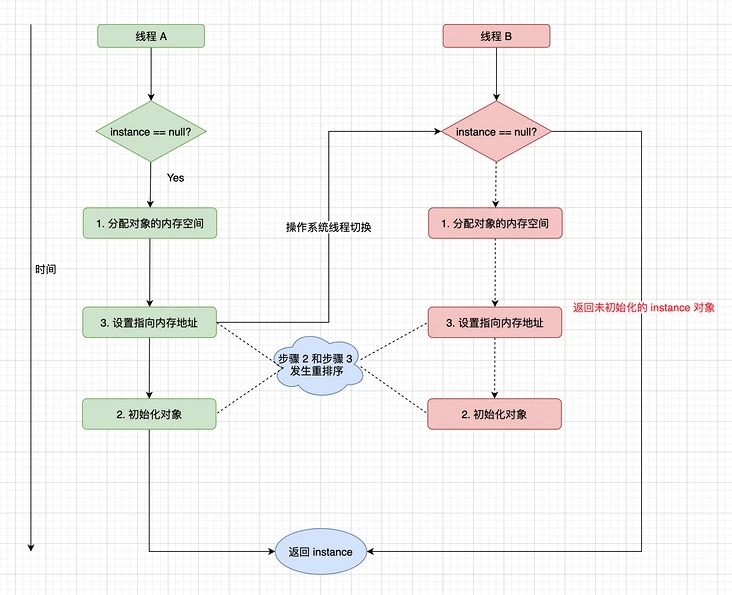
此時線程 B 獲取到的 instance 是沒有初始化過的,如果此來訪問 instance 的成員變量就可能觸發空指針異常。導致有序性問題的本質原因是編譯器優化。那你可能會想既然緩存和編譯器優化是導致可見性問題和有序性問題的原因,那直接禁用掉不就可以徹底解決這些問題了嗎,但是如果這么做了的話,程序的性能可能就會受到比較大的影響了。
其實可以換一種思路,能不能把這些禁用緩存和編譯器優化的權利交給編碼的工程師來處理,他們肯定最清楚什么時候需要禁用,這樣就只需要提供按需禁用緩存和編譯優化的方法即可,使用比較靈活。因此Java 內存模型就誕生了,它規范了 JVM 如何提供按需禁用緩存和編譯優化的方法,規定了 JVM 必須遵守一組最小的保證,這個最小保證規定了線程對共享變量的寫入操作何時對其它線程可見。
順序一致性模型是一個理想化后的理論參考模型,處理器和編程語言的內存模型的設計都是參考的順序一致性模型理論。其有如下兩大特性:
一個線程中的所有操作必須按照程序的順序來執行
所有的線程都只能看到一個單一的執行操作順序,不管程序是否同步
在工程師視角下的順序一致性模型如下:
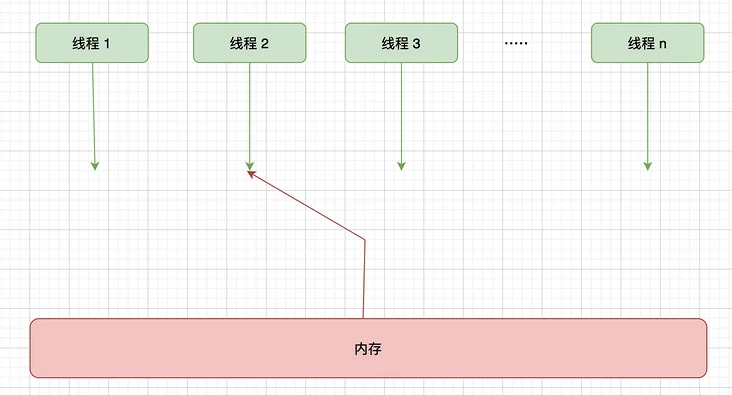
順序一致性模型有一個單一的全局內存,這個全局內存可以通過左右搖擺的開關可以連接到任意一個線程,每個線程都必須按照程序的順序來執行內存的讀和寫操作。該理想模型下,任務時刻都只能有一個線程可以連接到內存,當多個線程并發執行時,就可以通過開關就可以把多個線程的讀和寫操作串行化。
順序一致性模型中,所有操操作完全按照順序串行執行,但是在 JMM 中就沒有這個保證了,未同步的程序在 JMM 中不僅程序的執行順序是無序的,而且由于本地內存的存在,所有線程看到的操作順序也可能會不一致,比如一個線程把寫共享變量保存在本地內存中,在還沒有刷新到主內存前,其它線程是不可見的,只有更新到主內存后,其它線程才有可能看到。
JMM 對在正確同步的程序做了順序一致性的保證,也就是程序的執行結果和該程序在順序一致性內存模型中的執行結果相同。
Happens-Before 規則是 JMM 中的核心概念,Happens-Before 概念最開始在 這篇論文 提出,其在論文中使用 Happens-Before 來定義分布式系統之間的偏序關系。在 JSR-133 中使用 Happens-Before 來指定兩個操作之間的執行順序。
JMM 正是通過這個規則來保證跨線程的內存可見性,Happens-Before 的含義是前面一個對共享變量的操作結果對該變量的后續操作是可見的,約束了編譯器的優化行為,雖然允許編譯器優化,但是優化后的代碼必須要滿足 Happens-Before 規則,這個規則給工程師做了這個保證:同步的多線程程序是按照 Happens-Before 指定的順序來執行的。目的就是為了在不改變程序(單線程或者正確同步的多線程程序)執行結果的前提下,盡最大可能的提高程序執行的效率。
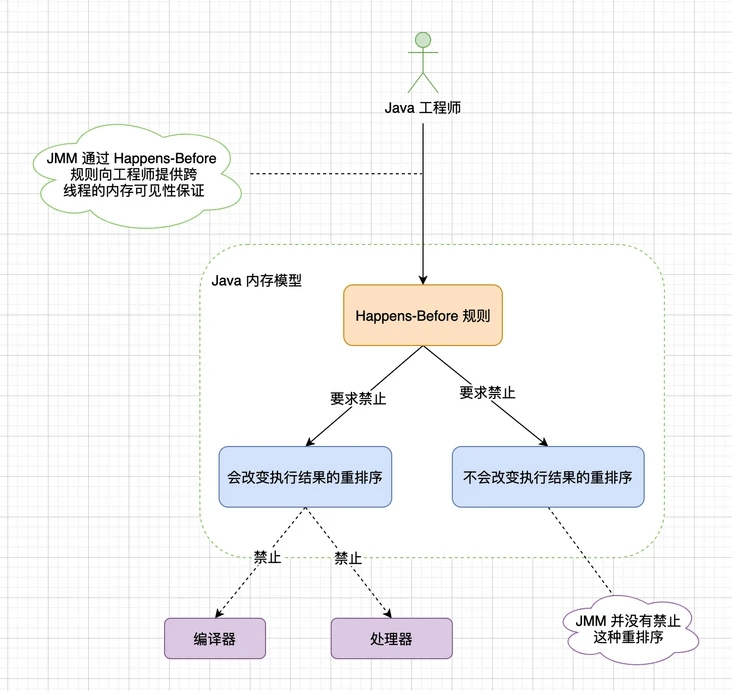
JSR-133 規范中定了如下 6 項 Happens-Before 規則:
程序順序規則:一個線程中的每個操作,Happens-Before 該線程中的任意后續操作
監視器鎖規則:對一個鎖的解鎖操作,Happens-Before 于后面對這個鎖的加鎖操作
volatile 規則:對一個 volatile 類型的變量的寫操作,Happens-Before 與任意后面對這個 volatile 變量的讀操作
傳遞性規則:如果操作 A Happens-Before 于操作 B,并且操作 B Happens-Before 于操作 C,則操作 A Happens-Before 于操作 C
start() 規則:如果一個線程 A 執行操作 threadB.start() 啟動線程 B,那么線程 A 的 start() 操作 Happens-Before 于線程 B 的任意操作
join() 規則:如果線程 A 執行操作 threadB.join() 并成功返回,那么線程 B 中的任意操作 Happens-Before 于線程 A 從 threadB.join() 操作成功返回
JMM 的一個基本原則是:只要不改變單線程和正確同步的多線程的執行結果,編譯器和處理器隨便怎么優化都可以,實際上對于應用開發人員對于兩個操作是否真的被重排序并不關心,真正關心的是執行結果不能被修改。因此 Happens-Before 本質上和 sa-if-serial 的語義是一致的,只是 sa-if-serial 只是保證在單線程下的執行結果不被改變。
總結:
本文主要介紹了內存模型的相關基礎知識和相關概念,JMM 屏蔽了不同處理器內存模型之間的差異,在不同的處理器平臺上給應用開發人員抽象出了統一的 Java 內存模型(JMM)。常見的處理器內存模型比 JMM 的要弱,因此 JVM 會在生成字節碼指令時在適當的位置插入內存屏障(內存屏障的類型會因處理器平臺而有所不同)來限制部分重排序。
感謝各位的閱讀,以上就是“Java的內存模型講解”的內容了,經過本文的學習后,相信大家對Java的內存模型講解這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





