溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Redis中怎么實現億級數據統計功能,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
通常情況下,我們面臨的用戶數量以及訪問量都是巨大的,比如百萬、千萬級別的用戶數量,或者千萬級別、甚至億級別的訪問信息。
所以,我們必須要選擇能夠非常高效地統計大量數據(例如億級)的集合類型。
如何選擇合適的數據集合,我們首先要了解常用的統計模式,并運用合理的數據了性來解決實際問題。
四種統計類型:
二值狀態統計;
聚合統計;
排序統計;
基數統計。
本文將用到 String、Set、Zset、List、hash 以外的拓展數據類型 Bitmap、HyperLogLog 來實現。
文章涉及到的指令可以通過在線 Redis 客戶端運行調試,地址:try.redis.io/,超方便的說。
寄語
多分享多付出,前期多給別人創造價值并且不計回報,從長遠來看,這些付出都會成倍的回報你。
特別是剛開始跟別人合作的時候,不要去計較短期的回報,沒有太大意義,更多的是鍛煉自己的視野、視角以及解決問題的能力。
碼哥,什么是二值狀態統計呀?
也就是集合中的元素的值只有 0 和 1 兩種,在簽到打卡和用戶是否登陸的場景中,只需記錄簽到(1)或 未簽到(0),已登錄(1)或未登陸(0)。
假如我們在判斷用戶是否登陸的場景中使用 Redis 的 String 類型實現(key -> userId,value -> 0 表示下線,1 - 登陸),假如存儲 100 萬個用戶的登陸狀態,如果以字符串的形式存儲,就需要存儲 100 萬個字符串了,內存開銷太大。
對于二值狀態場景,我們就可以利用 Bitmap 來實現。比如登陸狀態我們用一個 bit 位表示,一億個用戶也只占用 一億 個 bit 位內存 ≈ (100000000 / 8/ 1024/1024)12 MB。
大概的空間占用計算公式是:($offset/8/1024/1024) MB
什么是 Bitmap 呢?
Bitmap 的底層數據結構用的是 String 類型的 SDS 數據結構來保存位數組,Redis 把每個字節數組的 8 個 bit 位利用起來,每個 bit 位 表示一個元素的二值狀態(不是 0 就是 1)。
可以將 Bitmap 看成是一個 bit 為單位的數組,數組的每個單元只能存儲 0 或者 1,數組的下標在 Bitmap 中叫做 offset 偏移量。
為了直觀展示,我們可以理解成 buf 數組的每個字節用一行表示,每一行有 8 個 bit 位,8 個格子分別表示這個字節中的 8 個 bit 位,如下圖所示:
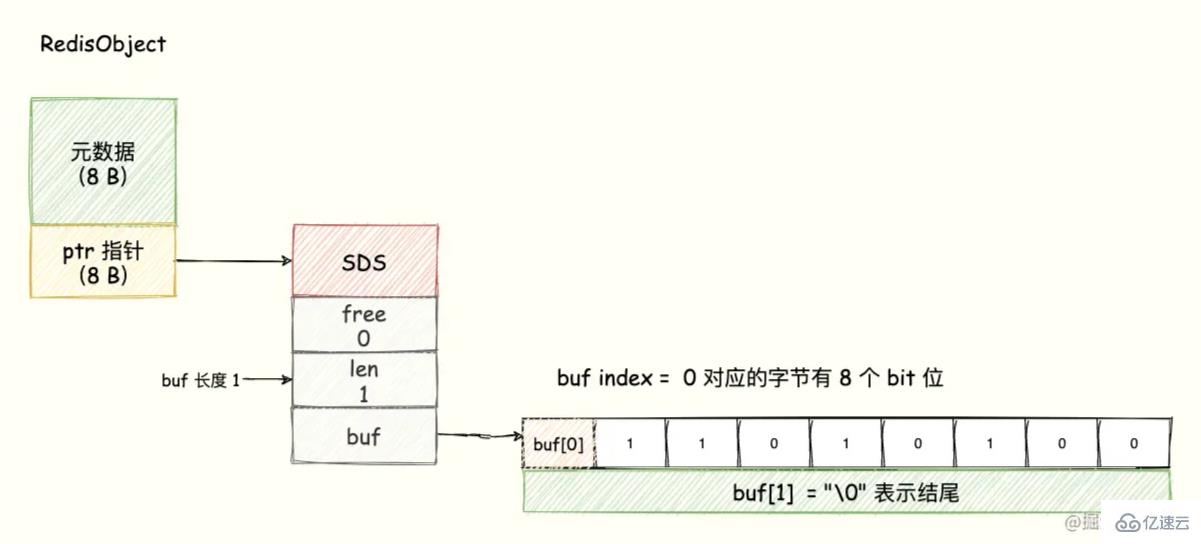
8 個 bit 組成一個 Byte,所以 Bitmap 會極大地節省存儲空間。 這就是 Bitmap 的優勢。
判斷用戶登陸態
怎么用 Bitmap 來判斷海量用戶中某個用戶是否在線呢?
Bitmap 提供了 GETBIT、SETBIT 操作,通過一個偏移值 offset 對 bit 數組的 offset 位置的 bit 位進行讀寫操作,需要注意的是 offset 從 0 開始。
只需要一個 key = login_status 表示存儲用戶登陸狀態集合數據, 將用戶 ID 作為 offset,在線就設置為 1,下線設置 0。通過 GETBIT判斷對應的用戶是否在線。 50000 萬 用戶只需要 6 MB 的空間。
SETBIT 命令
SETBIT <key> <offset> <value>
設置或者清空 key 的 value 在 offset 處的 bit 值(只能是 0 或者 1)。
GETBIT 命令
GETBIT <key> <offset>
獲取 key 的 value 在 offset 處的 bit 位的值,當 key 不存在時,返回 0。
假如我們要判斷 ID = 10086 的用戶的登陸情況:
第一步,執行以下指令,表示用戶已登錄。
SETBIT login_status 10086 1
第二步,檢查該用戶是否登陸,返回值 1 表示已登錄。
GETBIT login_status 10086
第三步,登出,將 offset 對應的 value 設置成 0。
SETBIT login_status 10086 0
用戶每個月的簽到情況
在簽到統計中,每個用戶每天的簽到用 1 個 bit 位表示,一年的簽到只需要 365 個 bit 位。一個月最多只有 31 天,只需要 31 個 bit 位即可。
比如統計編號 89757 的用戶在 2021 年 5 月份的打卡情況要如何進行?
key 可以設計成 uid:sign:{userId}:{yyyyMM},月份的每一天的值 - 1 可以作為 offset(因為 offset 從 0 開始,所以 offset = 日期 - 1)。
第一步,執行下面指令表示記錄用戶在 2021 年 5 月 16 號打卡。
SETBIT uid:sign:89757:202105 15 1
第二步,判斷編號 89757 用戶在 2021 年 5 月 16 號是否打卡。
GETBIT uid:sign:89757:202105 15
第三步,統計該用戶在 5 月份的打卡次數,使用 BITCOUNT 指令。該指令用于統計給定的 bit 數組中,值 = 1 的 bit 位的數量。
BITCOUNT uid:sign:89757:202105
這樣我們就可以實現用戶每個月的打卡情況了,是不是很贊。
如何統計這個月首次打卡時間呢?
Redis 提供了 BITPOS key bitValue [start] [end]指令,返回數據表示 Bitmap 中第一個值為 bitValue 的 offset 位置。
在默認情況下, 命令將檢測整個位圖, 用戶可以通過可選的 start 參數和 end 參數指定要檢測的范圍。
所以我們可以通過執行以下指令來獲取 userID = 89757 在 2021 年 5 月份首次打卡日期:
BITPOS uid:sign:89757:202105 1
需要注意的是,我們需要將返回的 value + 1 表示首次打卡的天,因為 offset 從 0 開始。
連續簽到用戶總數
在記錄了一個億的用戶連續 7 天的打卡數據,如何統計出這連續 7 天連續打卡用戶總數呢?
我們把每天的日期作為 Bitmap 的 key,userId 作為 offset,若是打卡則將 offset 位置的 bit 設置成 1。
key 對應的集合的每個 bit 位的數據則是一個用戶在該日期的打卡記錄。
一共有 7 個這樣的 Bitmap,如果我們能對這 7 個 Bitmap 的對應的 bit 位做 『與』運算。
同樣的 UserID offset 都是一樣的,當一個 userID 在 7 個 Bitmap 對應對應的 offset 位置的 bit = 1 就說明該用戶 7 天連續打卡。
結果保存到一個新 Bitmap 中,我們再通過 BITCOUNT 統計 bit = 1 的個數便得到了連續打卡 7 天的用戶總數了。
Redis 提供了 BITOP operation destkey key [key ...]這個指令用于對一個或者多個 鍵 = key 的 Bitmap 進行位元操作。
opration 可以是 and、OR、NOT、XOR。當 BITOP 處理不同長度的字符串時,較短的那個字符串所缺少的部分會被當做 0 。
空的 key 也被看作是包含 0 的字符串序列。
便于理解,如下圖所示:
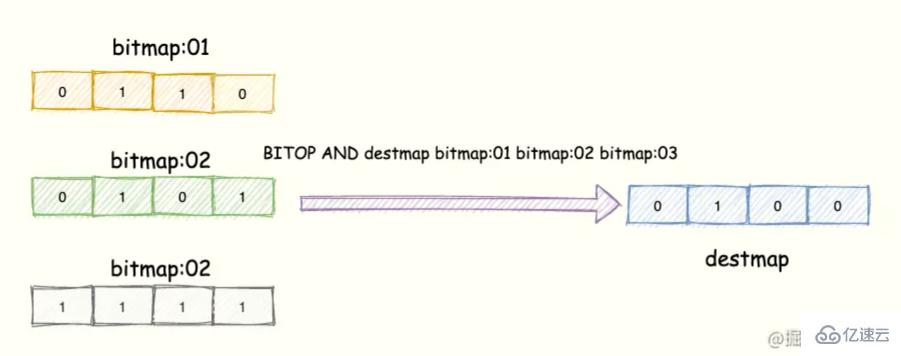
3 個 Bitmap,對應的 bit 位做「與」操作,結果保存到新的 Bitmap 中。
操作指令表示將 三個 bitmap 進行 AND 操作,并將結果保存到 destmap 中。接著對 destmap 執行 BITCOUNT 統計。
// 與操作 BITOP AND destmap bitmap:01 bitmap:02 bitmap:03 // 統計 bit 位 = 1 的個數 BITCOUNT destmap
簡單計算下 一個一億個位的 Bitmap占用的內存開銷,大約占 12 MB 的內存(10^8/8/1024/1024),7 天的 Bitmap 的內存開銷約為 84 MB。同時我們最好給 Bitmap 設置過期時間,讓 Redis 刪除過期的打卡數據,節省內存。
小結
思路才是最重要,當我們遇到的統計場景只需要統計數據的二值狀態,比如用戶是否存在、 ip 是否是黑名單、以及簽到打卡統計等場景就可以考慮使用 Bitmap。
只需要一個 bit 位就能表示 0 和 1,在統計海量數據的時候將大大減少內存占用。
基數統計:統計一個集合中不重復元素的個數,常見于計算獨立用戶數(UV)。
實現基數統計最直接的方法,就是采用集合(Set)這種數據結構,當一個元素從未出現過時,便在集合中增加一個元素;如果出現過,那么集合仍保持不變。
當頁面訪問量巨大,就需要一個超大的 Set 集合來統計,將會浪費大量空間。
另外,這樣的數據也不需要很精確,到底有沒有更好的方案呢?
這個問題問得好,Redis 提供了 HyperLogLog 數據結構就是用來解決種種場景的統計問題。
HyperLogLog 是一種不精確的去重基數方案,它的統計規則是基于概率實現的,標準誤差 0.81%,這樣的精度足以滿足 UV 統計需求了。
關于 HyperLogLog 的原理過于復雜,如果想要了解的請移步:
https://www.zhihu.com/question/53416615
https://en.wikipedia.org/wiki/HyperLogLog
網站的 UV
通過 Set 實現
一個用戶一天內多次訪問一個網站只能算作一次,所以很容易就想到通過 Redis 的 Set 集合來實現。
用戶編號 89757 訪問 「Redis 為什么這么快 」時,我們將這個信息放到 Set 中。
SADD Redis為什么這么快:uv 89757
當用戶編號 89757 多次訪問「Redis 為什么這么快」頁面,Set 的去重功能能保證不會重復記錄同一個用戶 ID。
通過 SCARD 命令,統計「Redis 為什么這么快」頁面 UV。指令返回一個集合的元素個數(也就是用戶 ID)。
SCARD Redis為什么這么快:uv
通過 Hash 實現
碼老濕,還可以利用 Hash 類型實現,將用戶 ID 作為 Hash 集合的 key,訪問頁面則執行 HSET 命令將 value 設置成 1。
即使用戶重復訪問,重復執行命令,也只會把這個 userId 的值設置成 “1"。
最后,利用 HLEN 命令統計 Hash 集合中的元素個數就是 UV。
如下:
HSET redis集群:uv userId:89757 1 // 統計 UV HLEN redis集群
HyperLogLog 王者方案
碼老濕,Set 雖好,如果文章非常火爆達到千萬級別,一個 Set 就保存了千萬個用戶的 ID,頁面多了消耗的內存也太大了。同理,Hash數據類型也是如此。咋辦呢?
利用 Redis 提供的 HyperLogLog 高級數據結構(不要只知道 Redis 的五種基礎數據類型了)。這是一種用于基數統計的數據集合類型,即使數據量很大,計算基數需要的空間也是固定的。
每個 HyperLogLog 最多只需要花費 12KB 內存就可以計算 2 的 64 次方個元素的基數。
Redis 對 HyperLogLog 的存儲進行了優化,在計數比較小的時候,存儲空間采用系數矩陣,占用空間很小。
只有在計數很大,稀疏矩陣占用的空間超過了閾值才會轉變成稠密矩陣,占用 12KB 空間。
PFADD
將訪問頁面的每個用戶 ID 添加到 HyperLogLog 中。
PFADD Redis主從同步原理:uv userID1 userID 2 useID3
PFCOUNT
利用 PFCOUNT 獲取 「Redis主從同步原理」頁面的 UV值。
PFCOUNT Redis主從同步原理:uv
PFMERGE 使用場景
HyperLogLog 除了上面的 PFADD 和 PFCOIUNT 外,還提供了 PFMERGE ,將多個 HyperLogLog 合并在一起形成一個新的 HyperLogLog 值。
語法
PFMERGE destkey sourcekey [sourcekey ...]
使用場景
比如在網站中我們有兩個內容差不多的頁面,運營說需要這兩個頁面的數據進行合并。
其中頁面的 UV 訪問量也需要合并,那這個時候 PFMERGE 就可以派上用場了,也就是同樣的用戶訪問這兩個頁面則只算做一次。
如下所示:Redis、MySQL 兩個 Bitmap 集合分別保存了兩個頁面用戶訪問數據。
PFADD Redis數據 user1 user2 user3 PFADD MySQL數據 user1 user2 user4 PFMERGE 數據庫 Redis數據 MySQL數據 PFCOUNT 數據庫 // 返回值 = 4
將多個 HyperLogLog 合并(merge)為一個 HyperLogLog , 合并后的 HyperLogLog 的基數接近于所有輸入 HyperLogLog 的可見集合(observed set)的并集。
user1、user2 都訪問了 Redis 和 MySQL,只算訪問了一次。
Redis 的 4 個集合類型中(List、Set、Hash、Sorted Set),List 和 Sorted Set 就是有序的。
List:按照元素插入 List 的順序排序,使用場景通常可以作為 消息隊列、最新列表、排行榜;
Sorted Set:根據元素的 score 權重排序,我們可以自己決定每個元素的權重值。使用場景(排行榜,比如按照播放量、點贊數)。
最新評論列表
碼老濕,我可以利用 List 插入的順序排序實現評論列表
比如微信公眾號的后臺回復列表(不要杠,舉例子),每一公眾號對應一個 List,這個 List 保存該公眾號的所有的用戶評論。
每當一個用戶評論,則利用 LPUSH key value [value ...] 插入到 List 隊頭。
LPUSH 碼哥字節 1 2 3 4 5 6
接著再用 LRANGE key star stop 獲取列表指定區間內的元素。
> LRANGE 碼哥字節 0 4 1) "6" 2) "5" 3) "4" 4) "3" 5) "2"
注意,并不是所有最新列表都能用 List 實現,對于因為對于頻繁更新的列表,list類型的分頁可能導致列表元素重復或漏掉。
比如當前評論列表 List ={A, B, C, D},左邊表示最新的評論,D 是最早的評論。
LPUSH 碼哥字節 D C B A
展示第一頁最新 2 個評論,獲取到 A、B:
LRANGE 碼哥字節 0 1 1) "A" 2) "B"
按照我們想要的邏輯來說,第二頁可通過 LRANGE 碼哥字節 2 3 獲取 C,D。
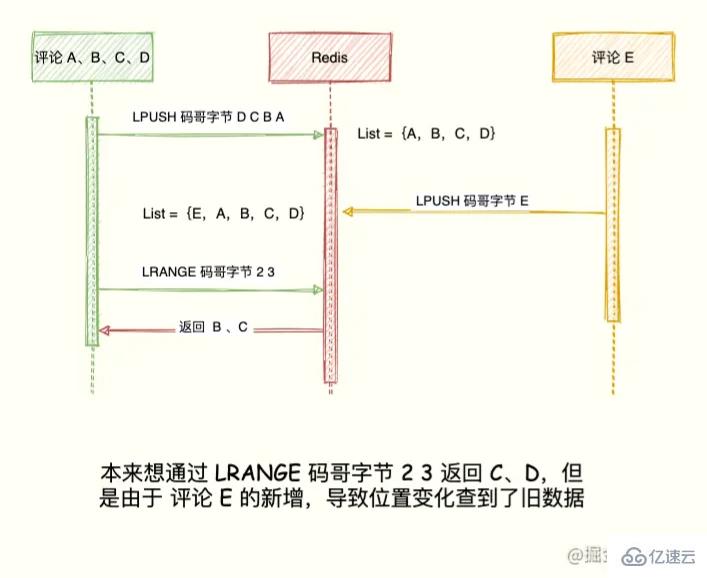
如果在展示第二頁之前,產生新評論 E,評論 E 通過 LPUSH 碼哥字節 E 插入到 List 隊頭,List = {E, A, B, C, D }。
現在執行 LRANGE 碼哥字節 2 3 獲取第二頁評論發現, B 又出現了。
LRANGE 碼哥字節 2 3 1) "B" 2) "C"
出現這種情況的原因在于 List 是利用元素所在的位置排序,一旦有新元素插入,List = {E,A,B,C,D}。
原先的數據在 List 的位置都往后移動一位,導致讀取都舊元素。
小結
只有不需要分頁(比如每次都只取列表的前 5 個元素)或者更新頻率低(比如每天凌晨統計更新一次)的列表才適合用 List 類型實現。
對于需要分頁并且會頻繁更新的列表,需用使用有序集合 Sorted Set 類型實現。
另外,需要通過時間范圍查找的最新列表,List 類型也實現不了,需要通過有序集合 Sorted Set 類型實現,如以成交時間范圍作為條件來查詢的訂單列表。
排行榜
碼老濕,對于最新列表的場景,List 和 Sorted Set 都能實現,為啥還用 List 呢?直接使用 Sorted Set 不是更好,它還能設置 score 權重排序更加靈活。
原因是 Sorted Set 類型占用的內存容量是 List 類型的數倍之多,對于列表數量不多的情況,可以用 Sorted Set 類型來實現。
比如要一周音樂榜單,我們需要實時更新播放量,并且需要分頁展示。
除此以外,排序是根據播放量來決定的,這個時候 List 就無法滿足了。
我們可以將音樂 ID 保存到 Sorted Set 集合中,score 設置成每首歌的播放量,該音樂每播放一次則設置 score = score +1。
ZADD
比如我們將《青花瓷》和《花田錯》播放量添加到 musicTop 集合中:
ZADD musicTop 100000000 青花瓷 8999999 花田錯
ZINCRBY
《青花瓷》每播放一次就通過 ZINCRBY指令將 score + 1。
> ZINCRBY musicTop 1 青花瓷 100000001
ZRANGEBYSCORE
最后我們需要獲取 musicTop 前十播放量音樂榜單,目前最大播放量是 N ,可通過如下指令獲取:
ZRANGEBYSCORE musicTop N-9 N WITHSCORES
65哥:可是這個 N 我們怎么獲取呀?
ZREVRANGE
可通過 ZREVRANGE key start stop [WITHSCORES]指令。
其中元素的排序按 score 值遞減(從大到小)來排列。
具有相同 score 值的成員按字典序的逆序(reverse lexicographical order)排列。
> ZREVRANGE musicTop 0 0 WITHSCORES 1) "青花瓷" 2) 100000000
小結
即使集合中的元素頻繁更新,Sorted Set 也能通過 ZRANGEBYSCORE 命令準確地獲取到按序排列的數據。
在面對需要展示最新列表、排行榜等場景時,如果數據更新頻繁或者需要分頁顯示,建議優先考慮使用 Sorted Set。
指的就是統計多個集合元素的聚合結果,比如說:
統計多個元素的共有數據(交集);
統計兩個集合其中的一個獨有元素(差集統計);
統計多個集合的所有元素(并集統計)。
碼老濕,什么樣的場景會用到交集、差集、并集呢?
Redis 的 Set 類型支持集合內的增刪改查,底層使用了 Hash 數據結構,無論是 add、remove 都是 O(1) 時間復雜度。
并且支持多個集合間的交集、并集、差集操作,利用這些集合操作,解決上邊提到的統計問題。
交集-共同好友
比如 QQ 中的共同好友正是聚合統計中的交集。我們將賬號作為 Key,該賬號的好友作為 Set 集合的 value。
模擬兩個用戶的好友集合:
SADD user:碼哥字節 R大 Linux大神 PHP之父 SADD user:大佬 Linux大神 Python大神 C++菜雞
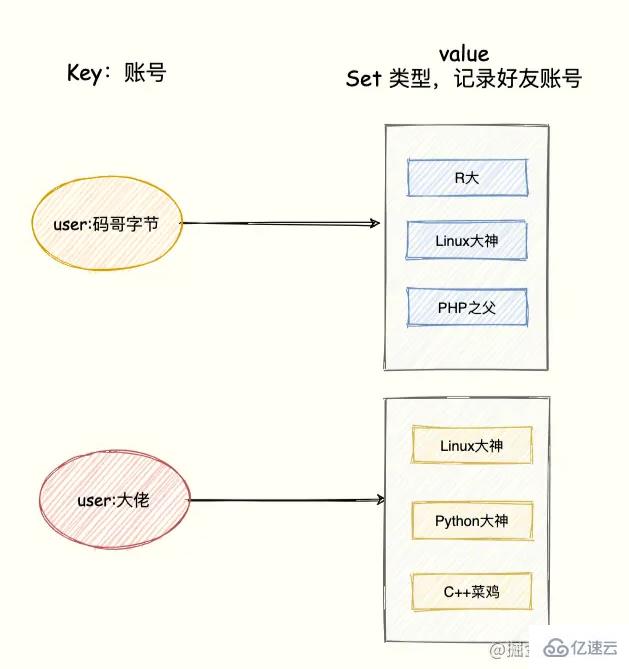
統計兩個用戶的共同好友只需要兩個 Set 集合的交集,如下命令:
SINTERSTORE user:共同好友 user:碼哥字節 user:大佬
命令的執行后,「user:碼哥字節」、「user:大佬」兩個集合的交集數據存儲到 user:共同好友這個集合中。
差集-每日新增好友數
比如,統計某個 App 每日新增注冊用戶量,只需要對近兩天的總注冊用戶量集合取差集即可。
比如,2021-06-01 的總注冊用戶量存放在 key = user:20210601 set 集合中,2021-06-02 的總用戶量存放在 key = user:20210602 的集合中。
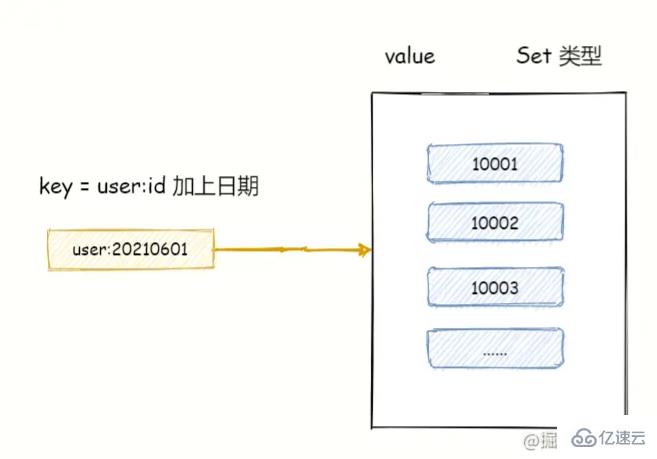
如下指令,執行差集計算并將結果存放到 user:new 集合中。
SDIFFSTORE user:new user:20210602 user:20210601
執行完畢,此時的 user:new 集合將是 2021/06/02 日新增用戶量。
除此之外,QQ 上有個可能認識的人功能,也可以使用差集實現,就是把你朋友的好友集合減去你們共同的好友即是可能認識的人。
并集-總共新增好友
還是差集的例子,統計 2021/06/01 和 2021/06/02 兩天總共新增的用戶量,只需要對兩個集合執行并集。
SUNIONSTORE userid:new user:20210602 user:20210601
看完上述內容,你們對Redis中怎么實現億級數據統計功能有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





