溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Node.js多進程模型中怎么實現共享內存,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
Node.js 由于其單線程模型的設計,導致一個Node進程(的主線程)只能利用一個CPU核心,然而現在的機器基本上都是多核的,這造成了嚴重的性能浪費。通常來說,想要利用到多個核心一般有以下的方法:
編寫Node的C++插件擴充線程池,并在JS代碼中將CPU耗時任務委托給其它線程處理。
使用worker_threads模塊提供的多線程模型(尚在實驗階段)。
使用child_process 或者 cluster模塊提供的多進程模型,每個進程都是一個獨立的Node.js進程。
從易用、代碼入侵性、穩定性的角度來說,多進程模型通常是首要的選擇。【推薦學習:《nodejs 教程》】
Node.js cluster 多進程模型存在的問題
在cluster模塊提供的多進程模型中,每個Node進程都是一個獨立且完整的應用進程,有自己的內存空間,其它進程無法訪問。因此雖然在項目啟動時,所有Worker進程具有一致的狀態和行為,但在之后的運行中無法保證其狀態維持一致。
例如,項目啟動時有兩個Worker進程,進程A和進程B,兩個進程都聲明了變量a=1。但之后項目接收到一個請求,Master進程將其分派給進程A來處理,這個請求將a的值變更為了2,那么此時進程A的內存空間中a=2,但是進程B的內存空間中a依舊是1。此時如果有個請求讀取a的值,Master進程將這個請求分派給進程A和進程B時讀取到的結果是不一致的,這就出現了一致性問題。
cluster模塊在設計時并沒有給出解決方案,而是要求Worker進程是無狀態的,即程序員在寫代碼時不應該允許在處理請求時修改內存中的值,以此來保障所有Worker進程的一致性。然而在實踐中總會有各種各樣的情況需要寫內存,比如記錄用戶的登錄狀態等,在許多企業的實踐中,通常會把這些狀態數據記錄在外部,例如數據庫、redis、消息隊列、文件系統等,每次處理有狀態請求時會讀寫外部存儲空間。
這不失為一種有效的做法,然而這需要額外引入一個外部存儲空間,同時還要自行處理多進程并發訪問下的一致性問題,自行維護數據的生命周期(因為Node進程和維護在外部的數據并不是同步創建和銷毀的),以及在高并發訪問情況下的IO性能瓶頸(如果是存儲在數據庫等非內存環境中)。其實本質上來說,我們只是需要一個可供多個進程共享訪問的空間罷了,并不需要持久化存儲,這段空間的生命周期最好與Node進程強綁定,這樣在使用時能省去不少麻煩。因此跨進程的共享內存就成了最適合在這種場景使用的方式。
Node.js 的共享內存
很遺憾Node本身并未提供共享內存的實現,因此我們可以看看npm倉庫中第三方庫的實現。這些庫有些是通過C++插件擴充Node的函數實現的,有些是通過Node提供的IPC機制實現的,但很遺憾它們的實現都很簡單,并未提供互斥訪問、對象監聽等功能,這使得使用者必須自己小心維護這段共享內存,否則就會導致時序問題。
轉了一圈下來沒找到我想要的。。。那就算了,我自己寫一個。
首先我們必須理清楚到底需要個什么樣的共享內存,我是根據我自身的需求出發(為了在項目中用它來存儲跨進程訪問的狀態數據),同時兼顧通用性,因此會首先考慮以下幾點:
以JS對象為基本單位進行讀寫訪問。
能夠進程間互斥訪問,一個進程訪問時,其它進程被阻塞。
能夠監聽共享內存中的對象,當對象發生變化的時候監聽的進程能被通知到。
在滿足上述條件的前提下,實現方式盡可能簡單。
可以發現,其實我們并不需要操作系統層面的共享內存,只需要能夠多個Node進程能訪問同一個對象就行了,那么就可以在Node本身提供的機制上實現。可以使用Master進程的一段內存空間作為共享內存空間,Worker進程通過IPC將讀寫請求委托給Master進程,由Master進程進行讀寫,然后再通過IPC將結果返回給Worker進程。
為了讓共享內存的使用方式在Master進程和Worker進程中一致,我們可以將對共享內存的操作抽離成一個接口,在Master進程和Worker進程中各自實現這個接口。類圖如下圖所示,用一個SharedMemory類作為抽象接口,在server.js入口文件中聲明該對象。其在Master進程中實例化為Manager對象,在Worker進程中實例化為Worker對象。Manager對象來維護共享內存,并處理對共享內存的讀寫請求,而Worker對象則將讀寫請求發送到Master進程。
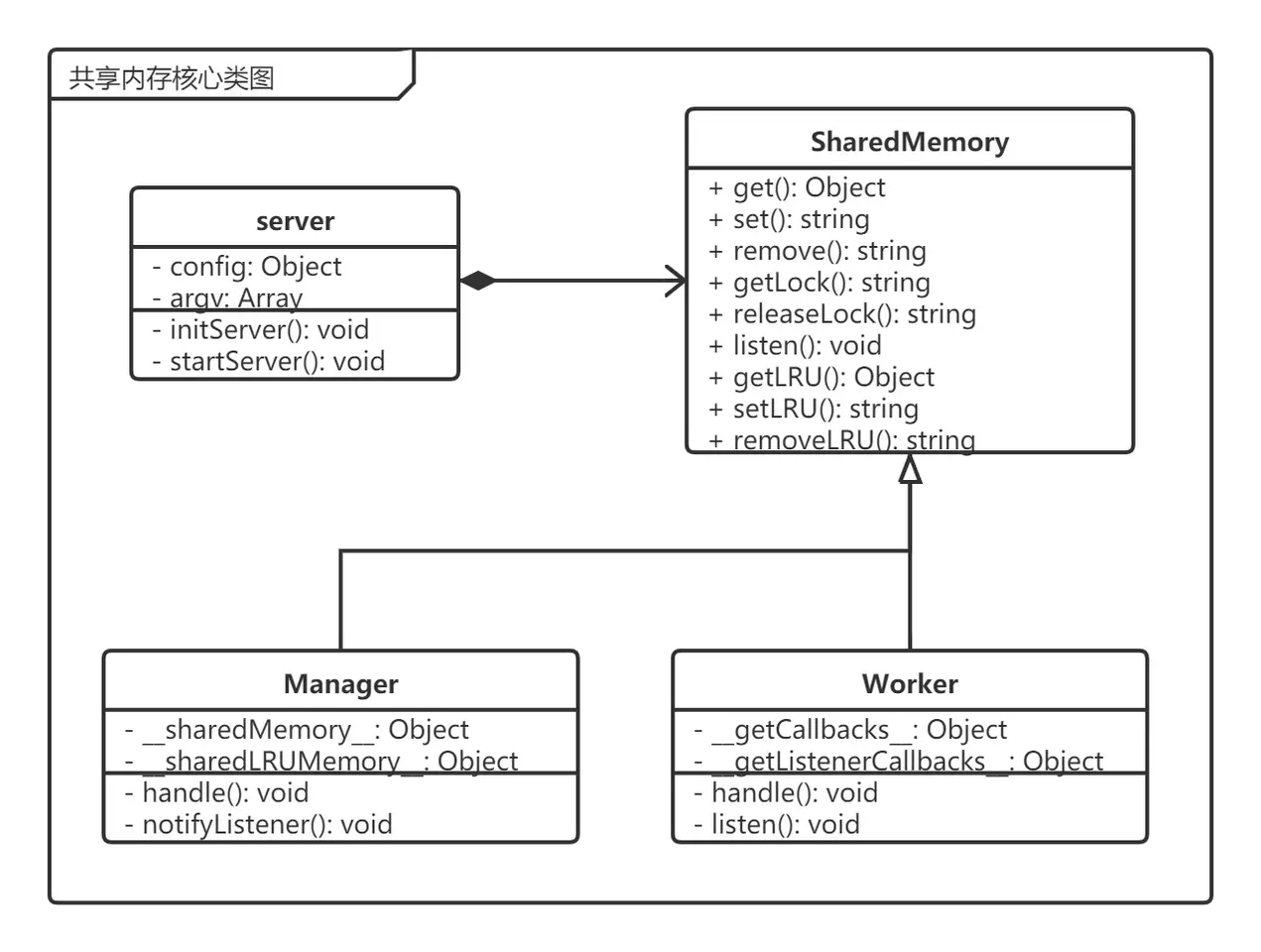
可以使用Manager類中的一個屬性作為共享內存對象,訪問該對象的方式與訪問普通JS對象的方式一致,然后再做一層封裝,只暴露get、set、remove等基本操作,避免該屬性直接被修改。
由于Master進程會優先于所有Worker進程創建,因此,可以在Master進程中聲明共享內存空間之后再創建Worker進程,以此來保證每個Worker進程創建后都可以立即訪問共享內存。
為了使用簡單,我們可以將SharedMemory設計成單例,這樣每個進程中就只有一個實例,并可以在import了SharedMemory之后直接使用。
讀寫控制與IPC通信
首先實現對外接口SharedMemory類,這里沒有使用讓Manager和Worker繼承SharedMemory的方式,而是讓SharedMemory在實例化的時候返回一個Manager或Worker的實例,從而實現自動選擇子類。
在Node 16中
isPrimary替代了isMaster,這里為了兼容使用了兩種寫法。
// shared-memory.js
class SharedMemory {
constructor() {
if (cluster.isMaster || cluster.isPrimary) {
return new Manager();
} else {
return new Worker();
}
}
}Manager負責管理共享內存空間,我們直接在Manager對象中增加__sharedMemory__屬性,由于其本身也是JS對象,會被納入JS的垃圾回收管理中,因此我們不需要進行內存清理、數據遷移等操作,使得實現上非常簡潔。之后在__sharedMemory__之中定義set、get、remove等標準操作來提供訪問方式。
我們通過cluster.on('online', callback)來監聽worker進程的創建事件,并在創建后立即用worker.on('message', callback)來監聽來自worker進程的IPC通信,并把通信消息交給handle函數處理。
handle函數的職責是區分worker進程是想進行哪種操作,并取出操作的參數委托給對應的set、get、remove函數(注意不是__sharedMemory__中的set、get、remove)進行處理,并將處理后的結果返還給worker進程。
// manager.js
const cluster = require('cluster');
class Manager {
constructor() {
this.__sharedMemory__ = {
set(key, value) {
this.memory[key] = value;
},
get(key) {
return this.memory[key];
},
remove(key) {
delete this.memory[key];
},
memory: {},
};
// Listen the messages from worker processes.
cluster.on('online', (worker) => {
worker.on('message', (data) => {
this.handle(data, worker);
return false;
});
});
}
handle(data, target) {
const args = data.value ? [data.key, data.value] : [data.key];
this[data.method](...args).then((value) => {
const msg = {
id: data.id, // workerId
uuid: data.uuid, // communicationID
value,
};
target.send(msg);
});
}
set(key, value) {
return new Promise((resolve) => {
this.__sharedMemory__.set(key, value);
resolve('OK');
});
}
get(key) {
return new Promise((resolve) => {
resolve(this.__sharedMemory__.get(key));
});
}
remove(key) {
return new Promise((resolve) => {
this.__sharedMemory__.remove(key);
resolve('OK');
});
}
}Worker自對象創建開始就使用process.on監聽來自Master進程的返回消息(畢竟不能等消息發送出去以后再監聽吧,那就來不及了)。至于__getCallbacks__對象的作用一會兒再說。此時Worker對象便創建完成。
之后項目運行到某個地方的時候,如果要訪問共享內存,就會調用Worker的set、get、remove函數,它們又會調用handle函數將消息通過process.send發送到master進程,同時,將得到返回結果時要進行的操作記錄在__getCallbacks__中。當結果返回時,會被之前在process.on中的函數監聽到,并從__getCallbacks__中取出對應的回調函數,并執行。
因為訪問共享內存的過程中會經過IPC,所以必定是異步操作,所以需要記錄回調函數,不能實現成同步的方式,不然會阻塞原本的任務。
// worker.js
const cluster = require('cluster');
const { v4: uuid4 } = require('uuid');
class Worker {
constructor() {
this.__getCallbacks__ = {};
process.on('message', (data) => {
const callback = this.__getCallbacks__[data.uuid];
if (callback && typeof callback === 'function') {
callback(data.value);
}
delete this.__getCallbacks__[data.uuid];
});
}
set(key, value) {
return new Promise((resolve) => {
this.handle('set', key, value, () => {
resolve();
});
});
}
get(key) {
return new Promise((resolve) => {
this.handle('get', key, null, (value) => {
resolve(value);
});
});
}
remove(key) {
return new Promise((resolve) => {
this.handle('remove', key, null, () => {
resolve();
});
});
}
handle(method, key, value, callback) {
const uuid = uuid4(); // 每次通信的uuid
process.send({
id: cluster.worker.id,
method,
uuid,
key,
value,
});
this.__getCallbacks__[uuid] = callback;
}
}一次共享內存訪問的完整流程是:調用Worker的set/get/remove函數 -> 調用Worker的handle函數,向master進程通信并將回調函數記錄在__getCallbacks__ -> master進程監聽到來自worker進程的消息 -> 調用Manager的handle函數 -> 調用Manager的set/get/remove函數 -> 調用__sharedMemory__的set/get/remove函數 -> 操作完成返回Manager的set/get/remove函數 -> 操作完成返回handle函數 -> 向worker進程發送通信消息 -> worker進程監聽到來自master進程的消息 -> 從__getCallbacks__中取出回調函數并執行。
互斥訪問
到目前為止,我們已經實現了讀寫共享內存,但還沒有結束,目前的共享內存是存在嚴重安全問題的。因為這個共享內存是可以所有進程同時訪問的,然而我們并沒有考慮并發訪問時的時序問題。我們來看下面這個例子:
| 時間 | 進程A | 進程B | 共享內存中變量x的值 |
|---|---|---|---|
| t0 | 0 | ||
| t1 | 讀取x(x=0) | 0 | |
| t2 | x1=x+1(x1=1) | 讀取x(x=0) | 0 |
| t3 | 將x1的值寫回x | x2=x+1(x2=1) | 1 |
| t4 | 將x2的值寫回x | 1 |
進程A和進程B的目的都是將x的值加1,理想情況下最后x的值應該是2,可是最后的結果卻是1。這是因為進程B在t3時刻給x的值加1的時候,使用的是t2時刻讀取出來的x的值,但此時從全局角度來看,這個值已經過期了,因為t3時刻x最新的值已經被進程A寫為了1,可是進程B無法知道進程外部的變化,所以導致了t4時刻最后寫回的值又覆蓋掉了進程A寫回的值,等于是進程A的行為被覆蓋掉了。
在多線程、多進程和分布式中并發情況下的數據一致性問題是老大難問題了,這里不再展開討論。
為了解決上述問題,我們必須實現進程間互斥訪問某個對象,來避免同時操作一個對象,從而使進程可以進行原子操作,所謂原子操作就是不可被打斷的一小段連續操作,為此需要引入鎖的概念。由于讀寫均以對象為基本單位,因此鎖的粒度設置為對象級別。在某一個進程(的某一任務)獲取了某個對象的鎖之后,其它要獲取鎖的進程(的任務)會被阻塞,直到鎖被歸還。而要進行寫操作,則必須要先獲取對象的鎖。這樣在獲取到鎖直到鎖被釋放的這段時間里,該對象在共享內存中的值不會被其它進程修改,從而導致錯誤。
在Manager的__sharedMemory__中加入locks屬性,用來記錄哪個對象的鎖被拿走了,lockRequestQueues屬性用來記錄被阻塞的任務(正在等待鎖的任務)。并增加getLock函數和releaseLock函數,用來申請和歸還鎖,以及handleLockRequest函數,用來使被阻塞的任務獲得鎖。在申請鎖時,會先將回調函數記錄到lockRequestQueues隊尾(因為此時該對象的鎖可能已被拿走),然后再調用handleLockRequest檢查當前鎖是否被拿走,若鎖還在,則讓隊首的任務獲得鎖。歸還鎖時,先將__sharedMemory__.locks中對應的記錄刪掉,然后再調用handleLockRequest讓隊首的任務獲得鎖。
// manager.js
const { v4: uuid4 } = require('uuid');
class Manager {
constructor() {
this.__sharedMemory__ = {
...
locks: {},
lockRequestQueues: {},
};
}
getLock(key) {
return new Promise((resolve) => {
this.__sharedMemory__.lockRequestQueues[key] =
this.__sharedMemory__.lockRequestQueues[key] ?? [];
this.__sharedMemory__.lockRequestQueues[key].push(resolve);
this.handleLockRequest(key);
});
}
releaseLock(key, lockId) {
return new Promise((resolve) => {
if (lockId === this.__sharedMemory__.locks[key]) {
delete this.__sharedMemory__.locks[key];
this.handleLockRequest(key);
}
resolve('OK');
});
}
handleLockRequest(key) {
return new Promise((resolve) => {
if (
!this.__sharedMemory__.locks[key] &&
this.__sharedMemory__.lockRequestQueues[key]?.length > 0
) {
const callback = this.__sharedMemory__.lockRequestQueues[key].shift();
const lockId = uuid4();
this.__sharedMemory__.locks[key] = lockId;
callback(lockId);
}
resolve();
});
}
...
}在Worker中,則是增加getLock和releaseLock兩個函數,行為與get、set類似,都是調用handle函數。
// worker.js
class Worker {
getLock(key) {
return new Promise((resolve) => {
this.handle('getLock', key, null, (value) => {
resolve(value);
});
});
}
releaseLock(key, lockId) {
return new Promise((resolve) => {
this.handle('releaseLock', key, lockId, (value) => {
resolve(value);
});
});
}
...
}監聽對象
有時候我們需要監聽某個對象值的變化,在單進程Node應用中這很容易做到,只需要重寫對象的set屬性就可以了,然而在多進程共享內存中,對象和監聽者都不在一個進程中,這只能依賴Manager的實現。這里,我們選擇了經典的觀察者模式來實現監聽共享內存中的對象。
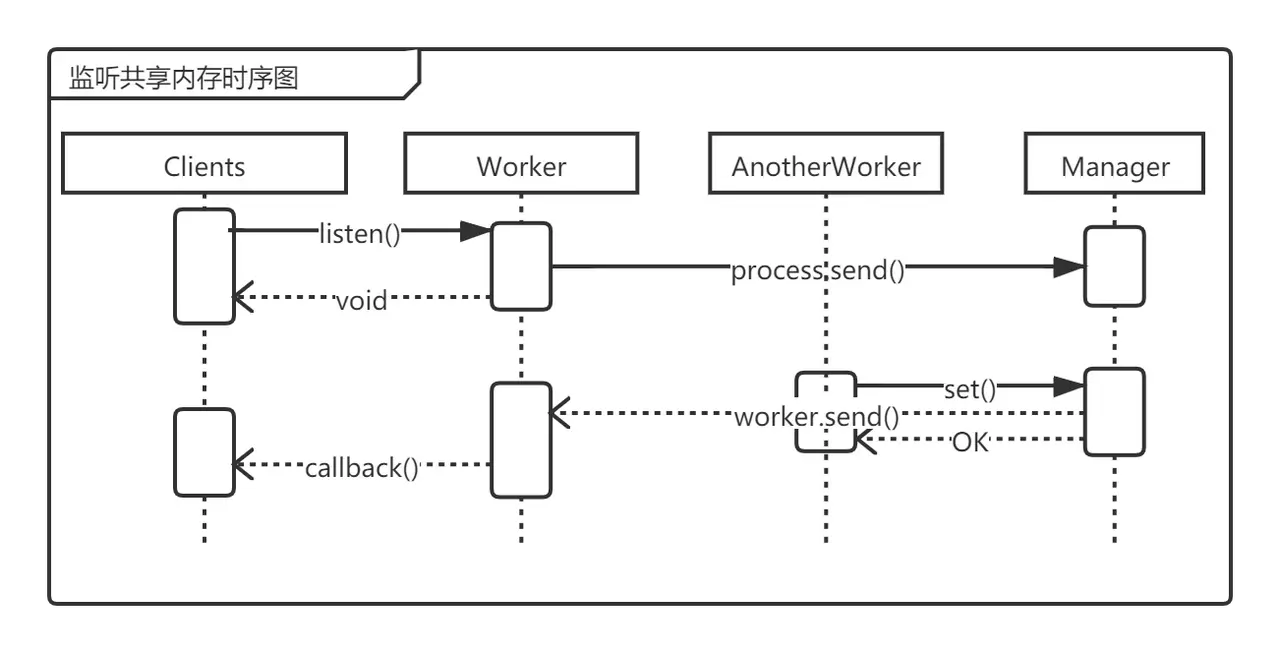
為此,我們先在__sharedMemory__中加入listeners屬性,用來記錄在對象值發生變化時監聽者注冊的回調函數。然后增加listen函數,其將監聽回調函數記錄到__sharedMemory__.listeners中,這個監聽回調函數會將變化的值發送給對應的worker進程。最后,在set和remove函數返回前調用notifyListener,將所有記錄在__sharedMemory__.listeners中監聽該對象的所有函數取出并調用。
// manager.js
class Manager {
constructor() {
this.__sharedMemory__ = {
...
listeners: {},
};
}
handle(data, target) {
if (data.method === 'listen') {
this.listen(data.key, (value) => {
const msg = {
isNotified: true,
id: data.id,
uuid: data.uuid,
value,
};
target.send(msg);
});
} else {
...
}
}
notifyListener(key) {
const listeners = this.__sharedMemory__.listeners[key];
if (listeners?.length > 0) {
Promise.all(
listeners.map(
(callback) =>
new Promise((resolve) => {
callback(this.__sharedMemory__.get(key));
resolve();
})
)
);
}
}
set(key, value) {
return new Promise((resolve) => {
this.__sharedMemory__.set(key, value);
this.notifyListener(key);
resolve('OK');
});
}
remove(key) {
return new Promise((resolve) => {
this.__sharedMemory__.remove(key);
this.notifyListener(key);
resolve('OK');
});
}
listen(key, callback) {
if (typeof callback === 'function') {
this.__sharedMemory__.listeners[key] =
this.__sharedMemory__.listeners[key] ?? [];
this.__sharedMemory__.listeners[key].push(callback);
} else {
throw new Error('a listener must have a callback.');
}
}
...
}在Worker中由于監聽操作與其它操作不一樣,它是一次注冊監聽回調函數之后對象的值每次變化都會被通知,因此需要在增加一個__getListenerCallbacks__屬性用來記錄監聽操作的回調函數,與__getCallbacks__不同,它里面的函數在收到master的回信之后不會刪除。
// worker.js
class Worker {
constructor() {
...
this.__getListenerCallbacks__ = {};
process.on('message', (data) => {
if (data.isNotified) {
const callback = this.__getListenerCallbacks__[data.uuid];
if (callback && typeof callback === 'function') {
callback(data.value);
}
} else {
...
}
});
}
handle(method, key, value, callback) {
...
if (method === 'listen') {
this.__getListenerCallbacks__[uuid] = callback;
} else {
this.__getCallbacks__[uuid] = callback;
}
}
listen(key, callback) {
if (typeof callback === 'function') {
this.handle('listen', key, null, callback);
} else {
throw new Error('a listener must have a callback.');
}
}
...
}LRU緩存
有時候我們需要用用內存作為緩存,但多進程中各進程的內存空間獨立,不能共享,因此也需要用到共享內存。但是如果用共享內存中的一個對象作為緩存的話,由于每次IPC都需要傳輸整個緩存對象,會導致緩存對象不能太大(否則序列化和反序列化耗時太長),而且由于寫緩存對象的操作需要加鎖,進一步影響了性能,而原本我們使用緩存就是為了加快訪問速度。其實在使用緩存的時候通常不會做復雜操作,大多數時候也不需要保障一致性,因此我們可以在Manager再增加一個共享內存__sharedLRUMemory__,其為一個lru-cache實例,并增加getLRU、setLRU、removeLRU函數,與set、get、remove函數類似。
// manager.js
const LRU = require('lru-cache');
class Manager {
constructor() {
...
this.defaultLRUOptions = { max: 10000, maxAge: 1000 * 60 * 5 };
this.__sharedLRUMemory__ = new LRU(this.defaultLRUOptions);
}
getLRU(key) {
return new Promise((resolve) => {
resolve(this.__sharedLRUMemory__.get(key));
});
}
setLRU(key, value) {
return new Promise((resolve) => {
this.__sharedLRUMemory__.set(key, value);
resolve('OK');
});
}
removeLRU(key) {
return new Promise((resolve) => {
this.__sharedLRUMemory__.del(key);
resolve('OK');
});
}
...
}Worker中也增加getLRU、setLRU、removeLRU函數。
// worker.js
class Worker {
getLRU(key) {
return new Promise((resolve) => {
this.handle('getLRU', key, null, (value) => {
resolve(value);
});
});
}
setLRU(key, value) {
return new Promise((resolve) => {
this.handle('setLRU', key, value, () => {
resolve();
});
});
}
removeLRU(key) {
return new Promise((resolve) => {
this.handle('removeLRU', key, null, () => {
resolve();
});
});
}
...
}目前共享內存的實現已發到npm倉庫(文檔和源代碼在Github倉庫,歡迎pull request和報bug),可以直接通過npm安裝:
npm i cluster-shared-memory
下面的示例包含了基本使用方法:
const cluster = require('cluster');
// 引入模塊時會根據當前進程 master 進程還是 worker 進程自動創建對應的 SharedMemory 對象
require('cluster-shared-memory');
if (cluster.isMaster) {
// 在 master 進程中 fork 子進程
for (let i = 0; i < 2; i++) {
cluster.fork();
}
} else {
const sharedMemoryController = require('./src/shared-memory');
const obj = {
name: 'Tom',
age: 10,
};
// 寫對象
await sharedMemoryController.set('myObj', obj);
// 讀對象
const myObj = await sharedMemoryController.get('myObj');
// 互斥訪問對象,首先獲得對象的鎖
const lockId = await sharedMemoryController.getLock('myObj');
const newObj = await sharedMemoryController.get('myObj');
newObj.age = newObj.age + 1;
await sharedMemoryController.set('myObj', newObj);
// 操作完之后釋放鎖
await sharedMemoryController.releaseLock('requestTimes', lockId);
// 或者使用 mutex 函數自動獲取和釋放鎖
await sharedMemoryController.mutex('myObj', async () => {
const newObjM = await sharedMemoryController.get('myObj');
newObjM.age = newObjM.age + 1;
await sharedMemoryController.set('myObj', newObjM);
});
// 監聽對象
sharedMemoryController.listen('myObj', (value) => {
console.log(`myObj: ${value}`);
});
//寫LRU緩存
await sharedMemoryController.setLRU('cacheItem', {user: 'Tom'});
// 讀對象
const cacheItem = await sharedMemoryController.getLRU('cacheItem');
}這種實現目前尚有幾個缺點:
不能使用PM2的自動創建worker進程的功能。
由于PM2會使用自己的
cluster模塊的master進程的實現,而我們的共享內存模塊需要在master進程維護一個內存空間,則不能使用PM2的實現,因此不能使用PM2的自動創建worker進程的功能。
傳輸的對象必須可序列化,且不能太大。
如果使用者在獲取鎖之后忘記釋放,會導致其它進程一直被阻塞,這要求程序員有良好的代碼習慣。
上述內容就是Node.js多進程模型中怎么實現共享內存,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





