溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“hashmap查詢時間復雜度為O(1)的原因是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Hashmap是java里面一種類字典式數據結構類,能達到O(1)級別的查詢復雜度,那么到底是什么保證了這一特性呢,這個就要從hashmap的底層存儲結構說起
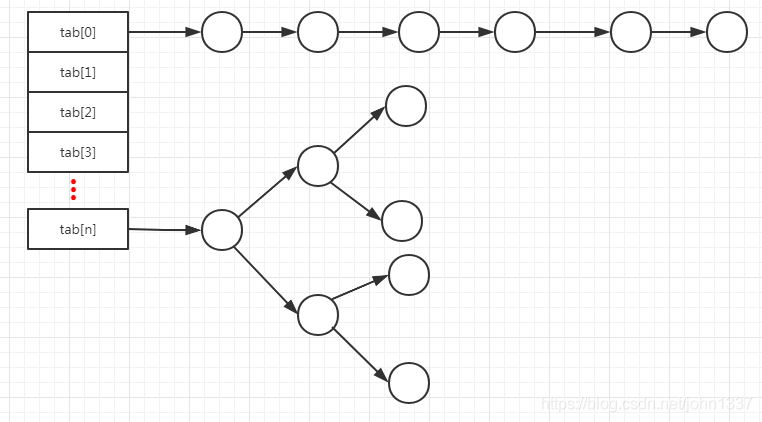
上面就是hashmap的底層存儲示意圖,要想查看一個鍵值對應的值,首先根據該鍵值的hash值找到該鍵的hash桶位置,即是tab[2]還是tab[1]等,計算某個鍵對應的哈希桶位置很簡單,就是
int pos = (n - 1) & hash,也就是hash%n,因為位運算效率高所以在hashmap實現時使用的是位運算這種方式,需要注意的是哈希桶的數量必須是2^n,所以hashmap一旦擴容必定是哈希桶數量翻番。
通過上面的描述,我們可以知道,根據鍵值找到哈希桶的位置時間復雜度為O(1),使用的就是數組的高效查詢。但是僅僅有這個是無法滿足整個hashmap查詢時間復雜度為O(1)的。hashmap在處理哈希沖突的方式如上圖所示的拉鏈法,在沖突數據沒有達到8個以前該哈希桶內部存儲使用的是鏈表的方式,當某個哈希桶的數據超過8個的情況下,
1、哈希桶的數量是沒有超過64個,那么此時哈希桶數量double,然后數據遷移
2、哈希桶的數量超過了64個,將該哈希桶內部數據進行紅黑樹化處理
所以我們可以看到如果所有哈希桶內部數據都是鏈表存儲的,那么每個哈希桶的數據量不會超過8個,這樣當定位到某個哈希桶時,在該哈希桶繼續查找也可以在O(1)時間內完成,下面看一種極端情況,所有的數據都在同一個桶里面(這種情況只在所有鍵值hash值相同的情況下,這種情況下查詢的時間復雜度為O(lgn),比如下面給出的一個類,所有我們在設置hashmap的鍵值時需要特別注意),在hashmap的文檔里面有這么一段描述,每個哈希桶中元素數量是成泊松分布的,
listSize = (exp(-0.5) * pow(0.5, k) / * factorial(k)),
不同數量出現的概率如下:
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
大于8: <千萬分之1
通過上面的統計來看,hashmap的鍵值正常(不同對象的hash值不同的情況),哈希桶數量超過8個概率低于千萬分之一,所以我們通常認為hashmap的查詢時間復雜度為O(1)
PS:
1、哈希沖突百分百的類
/**
測試哈希沖突的類,所有的對象都返回同樣的hash值
**/
public static class Student{
private String name;
Student(String name){
this.name = name;
}
@Override
public int hashCode(){
return 1;
}
@Override
public boolean equals(Object obj){
if(this == obj){
return true;
}
if(obj == null){
return false;
}
return this.name.equals(((Student)obj).name);
}
}2、我們在實際使用hashmap時需要確保實現hashcode方法以及equals方法,否則不能作為hashmap的鍵值
3、在設置hashmap的鍵值hashcode方法時盡量保證較好的離散型
4、hashmap的鍵值需保證equals方法返回true時,hashcode必須相同,所以在實際中經常使用的鍵值類string,重寫了equals以及hashcode方法
HashMap底層采用了hash算法
根據 key 獲得 hashCode 值
HashMap 初始有很多個類似于“桶”的數據結構,比如說預設了 10 個桶,通過 hashCode 經過一定的算法(這個算法必須是快速的)
得到這個 hashCode 應存在哪個桶中,然后內部生成 Map.Entry 對象將 key 和 value 存到桶中去。
所以一般情況下HashMap的插入和查找的時間復雜度都是O(1);
“hashmap查詢時間復雜度為O(1)的原因是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





