溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前提:搭建zookeeper集群、java環境、無秘互通
注意:文中加粗部分表示需要按實際情況修改的部分
zookeeper可以參考:zookeeper傳送門
下載安裝包
https://mirrors.tuna.tsinghua.edu.cn/apache/ 是官網提供的安裝包下載網站之一。
結構
| 主機名 | study | centos156 | client |
|---|---|---|---|
| IP | 192.168.233.155 | 192.168.233.156 | 192.168.233.158 |
| 服務1 | zookeeper 1 | zookeeper 2 | zookeeper 3 |
| 服務2 | namenode | namenode | |
| 服務3 | datanode | datanode | datanode |
| 服務4 | journalnode | journalnode | |
| 服務5 | nodemanager | nodemanager | nodemanager |
| 服務6 | zkfc | zkfc | |
| 服務7 | ResourceManager |
服務簡介:
zookeeper:分布式應用程序協調服務。
namenode:管理服務。管理元數據,維護目錄樹,響應請求。
datanode:hadoop中存儲數據。
journalnode:實現namenode數據共享,保持數據的一致性。
ResourceManager:yarn集群中資源的統一管理和分配
nodemanager:ResourceManager在每臺機器上的代理
參考文檔:hadoop介紹
注:zookeeper和hadoop可以不裝在一個臺機器上,只需配置文件指定即可
檢查java環境
java -version
如果能夠顯示版本說明jdk安裝ok
#下載文件(可能因為版本更新生效)
cd /tmp
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz
#解壓文件
tar axf hadoop-2.7.5/hadoop-2.7.5.tar.gz -C /usr/local
#重命名,方便管理配置
cd /usr/local
rename hadoop-2.7.5 hadoop hadoop-2.7.5
#修改環境變量
vim /etc/profile
在文件最后添加如下內容
export HADOOP_HOME=/usr/local/hadoop
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${PATH}
export HADOOP_MAPARED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export LD_LIBRARY_PATH=${HADOOP_HOME}/lib/native/:${LD_LIBRARY_PATH}
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
#使其生效
source /etc/profile
#創建文件存放目錄
mkdir -p /usr/local/hadoop/{name,data,tmp,journal}
#修改配置文件
cd $HADOOP_HOME/etc/hadoop
#修改slaves文件,指定slave服務器
vim slaves
study
centos156
client
#修改core-site.xml,指定hdfs集群,臨時文件目錄,zookeeper等
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop</value>
<description>HDFS的邏輯服務名,hadoop位置可以寫成任何東西</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>hadoop臨時文件存放目錄,也可寫作file:/usr/local/hadoop/tmp</description>
</property><property>
<name>io.file.buffer.size</name>
<value>4096</value>
<description>指定執行文件IO緩存區大小,機器好可以設置大些</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>study:2181,centos156:2181,client:2181</value>
<description>指定zookeeper地址</description>
</property>
</configuration>
參考文檔
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>hadoop</value>
<description>HDFS NN的邏輯名稱,需要與core-site.xml中的HDFS的邏輯服務名一致,這里使用上面的hadoop</description>
</property>
<property>
<name>dfs.ha.namenodes.hadoop</name>
<value>study,centos156</value>
<description>hadoop邏輯名namenode節點列表,hadoop對應邏輯名</description>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoop.study</name>
<value>study:9000</value>
<description>hadoop中study的rpc通信地址</description>
</property>
<property>
<name>dfs.namenode.http-address.hadoop.study</name>
<value>study:50070</value>
<description>hadoop中study的http通信地址</description>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoop.centos156</name>
<value>centos156:9000</value>
<description>hadoop中centos156的rpc通信地址</description>
</property>
<property>
<name>dfs.namenode.http-address.hadoop.centos156</name>
<value>centos156:50070</value>
<description>hadoop中centos156的http通信地址</description>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://study:8485;centos156:8485;client:8485/hadoop</value>
<description> journalNode 的 URI 地址,活動的namenode會將edit log寫入journalNode</description>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/journal</value>
<description>用于存放 editlog 和其他狀態信息的目錄</description>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<description>啟動自動failover,詳情請看參考文檔</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.hadoop</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>實現客戶端與 active NameNode 進行交互的 Java類</description>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<description>解決HA集群腦裂問題,只允許一個nn寫數據</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
<description>the location stored ssh key,指定用戶密匙,建議不要用root,用于故障轉移,可以不設置</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>5000</value>
<description>ssh連接超時時間,上面秘鑰沒設置這個也可以不設置</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/name</value>
<description>namenode數據存放目錄</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/data</value>
<description>datanode數據存放目錄</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>client參數,node level參數,指定一個文件在hdfs中有幾個副本,設置2或3即可,不能錯過datanode節點數</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
<description>允許webhdfs,用于數據讀取</description>
</property>
</configuration>
webhdfs詳解
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>mapreduce框架,一般用yarn</description>
</property>
</configuration>
MapReduce詳解
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>nodemanager啟動時加載services的方式為mapreduce分配</description>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
<description>實現mapreduce_shuffle的java類</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>study</value>
<description>resourcemanager節點列表,一個namenode上有即可</description>
</property>
</configuration>
修改腳本文件中的JAVA_HOME
vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
注意 export HADOOP_SSH_OPTS是自動hadoop服務ssh使用端口,如果你沒有使用默認的22號端口,請修改該選項,否則HA無法實現
vim yarn-env.sh
JAVA_HOME=/usr/local/jdk
#將study節點上的hadoop文件拷貝到centos156的/usr/local目錄下
scp -r study:/usr/local/hadoop /usr/local
#修改環境變量
scp -r study:/etc/profile /etc/
source /etc/profile
#如果你使用的是其他的用戶執行hadoop,就需要修改hadoop文件的屬主等信息
#與 主節點二-centos156操作一樣
scp -r study:/usr/local/hadoop /usr/local
scp -r study:/etc/profile /etc/
source /etc/profile
第一次運行hadoop是需要格式化數據,啟動會比較麻煩,之后的啟動只需要start-all.sh停止stop-all.sh
前提:zookeeper狀態正常,jdk狀態正常,環境變量設置正常
#創建命名空間
hdfs zkfc -formatZK
#啟動journalnode
hadoop-daemon.sh start journalnode(最好三個節點一起啟動)
#格式化namenode
hdfs namenode -format hadoop
#啟動namenode
hadoop-daemon.sh start namenode
#啟動zfkc
hadoop-daemon.sh start zkfc
#啟動journalnode
hadoop-daemon.sh start journalnode
#從hdfs namenode -bootstrapStandby獲取格式化后的元數據
hdfs namenode -bootstrapStandby
#啟動namenode
hadoop-daemon.sh start namenode
#啟動zfkc
hadoop-daemon.sh start zkfc
#啟動journalnode
hadoop-daemon.sh start journalnode
上面三個節點命令運行完成后重啟hadoop集群
關閉集群
stop-all.sh
啟動集群
start-all.sh
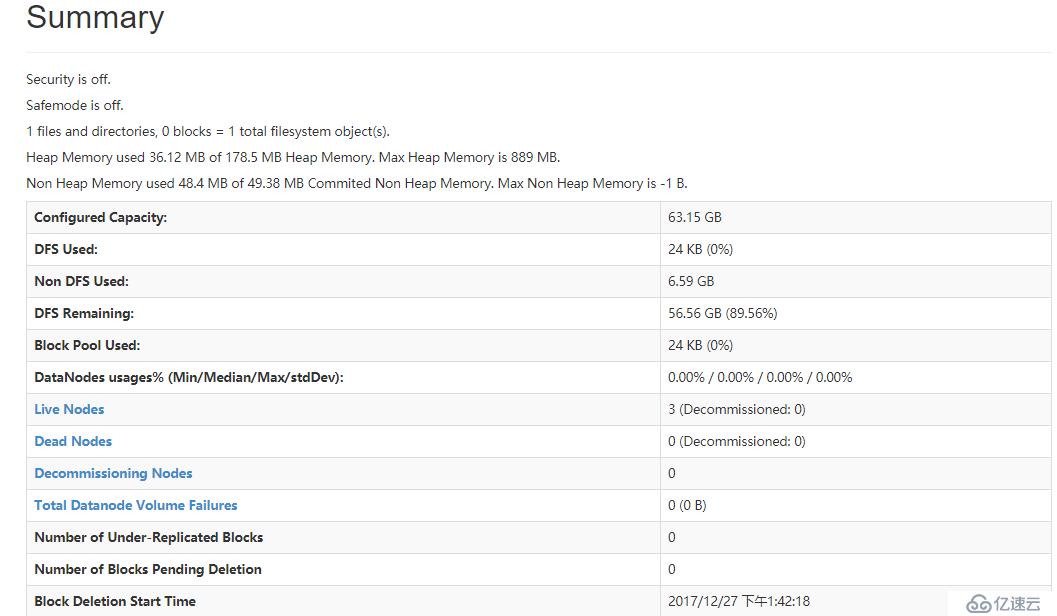
訪問狀態頁面
http://192.168.233.155:50070/dfshealth.html#tab-overview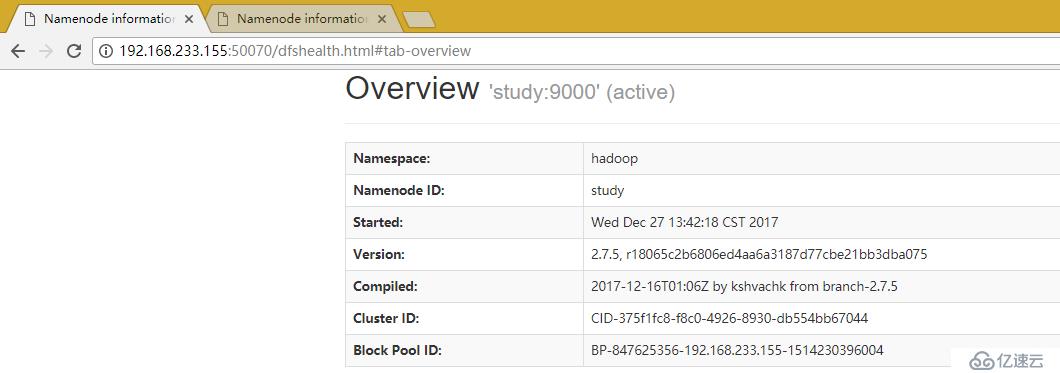
http://192.168.233.156:50070/dfshealth.html#tab-overview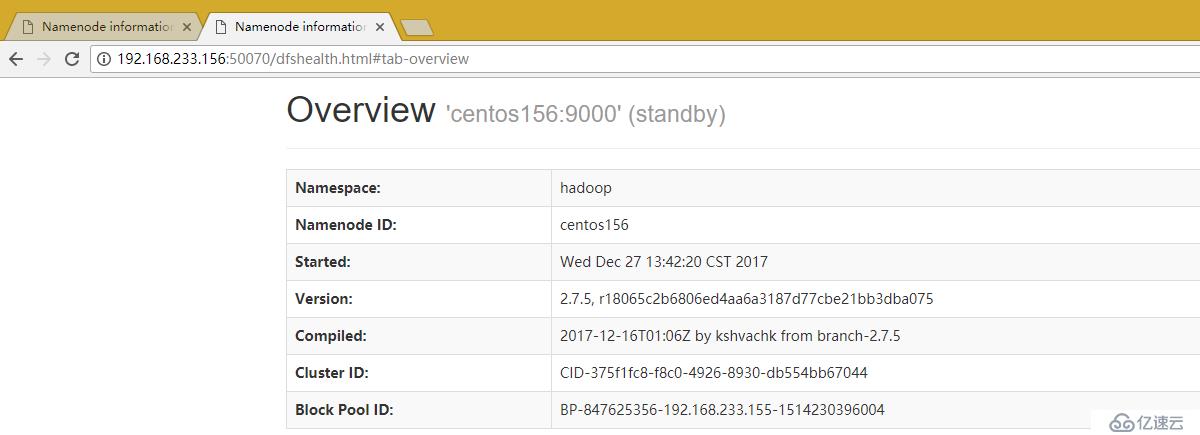
頁面上的datanodes可以看到datanode的狀態,utilities可以查看文件和日志
hadoop常用命令
關閉集群 stop-all.sh
啟動集群 start-all.sh
單獨啟動namenode hadoop-daemon.sh start namenode
單獨啟動datanode hadoop-daemon.sh start datanode
單獨啟動journalnode hadoop-daemon.sh start journalnode
單獨啟動zkfc hadoop-daemon.sh start zkfc
手動轉移活動namenode hdfs haadmin -transitionToActive --forcemanual study
查看/下面的文件 hadoop fs -ls /
上傳文件到hadoop hadoop fs -put <原文件> <存放路徑>
i.e. hadoop fs -put /etc/passwd /
hadoop中創建命令 hadoop fs –mkdir <絕對路徑>
i.e. hadoop fs -mkdir /tmp
創建空文件 hadoop fs -touchz <文件絕對路徑>
i.e. hadoop fs -touchz /tmp/hello
查看文件 hadoop fs -cat <文件絕對路徑>
i.e. hadoop fs -cat /passwd
移動或重命名 hadoop fs -mv <文件絕對路徑> <新文件絕對路徑\名稱>
下載hadoop中的文件或目錄到本地
hadoop fs -get <文件絕對路徑> <本地路徑>
i.e. hadoop fs -get /passwd /tmp
修改文件權限 hadoop fs -chmod [-R] <文件絕對路徑>
i.e. hadoop fs -chmod 777 /passwd
刪除文件 hadoop fs -rm <文件絕對路徑>
刪除目錄 hadoop fs -rm -r <目錄絕對路徑>
數據備份mkdir /tmp/hadoop
chmod 777 /tmp/hadoop
hadoop fs -copyToLocal hdfs://study:9000/ /tmp/hadoop
數據恢復
先用u盤或者其他的任何方式將文件傳輸到目標機器
hadoop fs -copyFromLocal /tmp/hadoop hdfs://study:9000/
hadoop fs -ls /

master: Host key verification failed.
請檢查authorized_keys 和known_hosts文件是是否有該主機的信息,ssh 主機名能不能連上
hadoop集群一個主節點namenode掛掉之后啟動異常
2018-01-17 08:53:24,751 FATAL [hadoop1:16000.activeMasterManager] master.HMaster: Failed to become active master
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category READ is not supported in state standby
at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:87)
at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.checkOperation(NameNode.java:1774)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOperation(FSNamesystem.java:1313)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getFileInfo(FSNamesystem.java:3850)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getFileInfo(NameNodeRpcServer.java:1011)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getFileInfo(ClientNamenodeProtocolServerSideTranslatorPB.java:843)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
處理過程:
查看狀態(看web頁面)發現study的狀態為standby,centos156狀態為active
如果有一個active這集群狀態依然是正常的,如果兩個都是standby則為異常。
狀態不正常可能是數據異常造成的,namenode掛的時間長了數據不同步,處理方法一、從centos 156節點將數據同步過來,方法二、刪除所有節點上所有hadoop的數據,刪除zk中hadoop-ha目錄
本次使用的是方法二
所有節點刪除${HADOOP_HOME}下name、data、logs、tmp目錄下的所有文件
刪除zk中的數據
zkCli.sh
ls /
rmr /hadoop-ha
quit
重新生成數據
主節點1-study
#創建命名空間
hdfs zkfc -formatZK
#啟動journalnode
hadoop-daemon.sh start journalnode(最好三個節點一起啟動)
#格式化namenode
hdfs namenode -format hadoop
#啟動namenode
hadoop-daemon.sh start namenode
#啟動zfkc
hadoop-daemon.sh start zkfc
主節點二-centos156
#啟動journalnode
hadoop-daemon.sh start journalnode
#從hdfs namenode -bootstrapStandby獲取格式化后的元數據
hdfs namenode -bootstrapStandby
#啟動namenode
hadoop-daemon.sh start namenode
#啟動zfkc
hadoop-daemon.sh start zkfc
從節點-client
#啟動journalnode
hadoop-daemon.sh start journalnode
查看狀態肯定是active,都是新的了
hadoop介紹
配置文件參考文檔
webhdfs詳解
hadoop HDFS常用文件操作命令
hadoop fs管理文件權限:https://www.cnblogs.com/linn/p/5526071.html
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





