溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
友情提示:本文超級長,請備好瓜子
Hadoop的運行模式
單機模式是Hadoop的默認模式,在該模式下無需任何守護進程,所有程序都在單個JVM上運行,該模式主要用于開發和調試mapreduce的應用邏輯;
偽分布式模式下,Hadoop守護進程運行在一臺機器上,模擬一個小規模的集群。該模式在單機模式的基礎上增加了代碼調試的功能,允許你檢查NameNode,DataNode,Jobtracker,Tasktracker等模擬節點的運行情況;
單機模式和偽分布式模式均用于開發和調試的目的,真實Hadoop集群的運行采用的是完全分布式模式
單機模式安裝步驟
一個干凈的linux基礎環境(重要,這個環境如果有問題后續就全是問題了)
為了方便大家我已經安裝好了一個,大家只需下載導入到vm里即可使用。
下載地址:關注公眾號【測試幫日記】對話框里回復“linux”或者加入QQ群522720170。
鏈接:https://pan.baidu.com/s/1qXRjaK8 密碼:xjfk
關閉防火墻(適用于centos7,低版本不適用)
分別執行如下兩條命令:
systemctl stop firewalld.service
systemctl disable firewalld.service
修改host name
vi /etc/hosts
然后把自己虛機的名字追加到兩行的末尾,如果用的是我們提供的虛機,名字就是linux,追加之后的效果如圖

重啟網絡:/etc/rc.d/init.d/network restart
設置無密碼登錄(用于hadoop啟動)
cd ~ #進入當前用戶的目錄
mkdir -p /root/.ssh #我們用的root用戶
cd ~/.ssh/
ssh-keygen -t rsa #如有提示,直接按回車 cat id_rsa.pub >> authorized_keys # 加入授權
安裝jdk1.8并配置環境變量
tar解壓
cp解壓后的包到/usr/lib/java/(如果沒有java目錄就創建一下)
vi /etc/profile,末尾添加如下內容:
export JAVA_HOME=/usr/lib/java/jdk1.8.0_11
export JRE_HOME=/usr/lib/java/jdk1.8.0_11/jre
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
執行source /etc/profile使得環境變量生效
驗證是否成功,如下圖


安裝hadoop2.7.4
tar解壓
cp解壓后的包到/usr/lib/hadoop/(如果沒有hadoop目錄就創建一下)
設置hadoop-env.sh
vi /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop/hadoop-env.sh
找到# The java implementation to use.這句話,在下面添加如下內容:
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/lib/java/jdk1.8.0_11
export HADOOP_HOME=/usr/lib/hadoop/hadoop-2.7.4
export PATH=$PATH:/usr/lib/hadoop/hadoop-2.7.4/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
執行source /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop/hadoop-env.sh,使得環境變量生效
驗證是否成功,如下圖

配置相關的xml文件
vi /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop/core-site.xml(hadoop全局配置)
內容如下:
<configuration>
<!--指定namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>
vi /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop/hdfs-site.xml(hdfs配置)
內容如下:
<configuration>
<!--指定hdfs保存數據的副本數量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
cd /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml(MapReduce的配置)
內容如下:
<configuration>
<!--告訴hadoop以后MapReduce運行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi yarn-site.xml(yarn配置)
內容如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<!--nomenodeManager獲取數據的方式是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
格式化hdfs文件系統
初次運行hadoop時一定要有該操作,命令如下:
/usr/lib/hadoop/hadoop-2.7.4/bin/hadoop namenode -format
執行期間可能需要確認是否繼續,如果有,就輸入y回車即可
當你看到如下的內容時證明成功了

如果看到的是exiting with status 1,那么請運行如下命令,之后在進行hdfs的格式化
mkdir -pv /tmp/hadoop-root/dfs/name
啟動hadoop(hdfs和yarn)
sh /usr/lib/hadoop/hadoop-2.7.4/sbin/start-all.sh
sh /usr/lib/hadoop/hadoop-2.7.4/sbin/stop-all.sh #停止
如果沒有報錯說明就成功了
使用jps命令查看進程,如果出現下面的內容就說明確定以及肯定成功啦
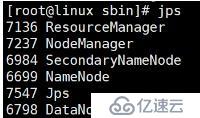
PS:如果修改了上面的xml文件需要重啟服務哦
使用web查看Hadoop運行狀態
http://你的服務器ip地址:50070/
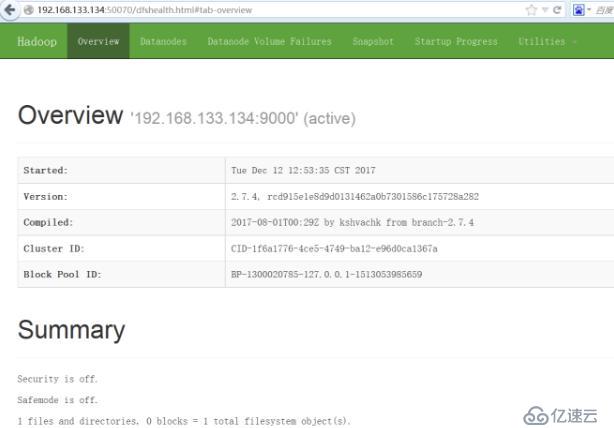
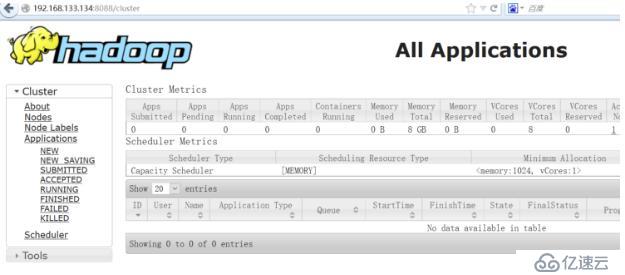
使用web查看集群狀態
http://你的服務器IP地址:8088
可能會遇到的問題
如果你多次進行了hdfs的格式化操作,可能會無法啟動datanode,原因是id不一致,一般的解決方法為將namenode clusterID和datanode clusterID改成一樣的就行了。修改的文件為/tmp/hadoop-root/dfs/下的name or data文件下的VERSION里的內容
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





