溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了互聯網的分布式ID的示例分析,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
ID是數據的唯一標識,傳統的做法是利用UUID和數據庫的自增ID,在互聯網企業中,大部分公司使用的都是Mysql,并且因為需要事務支持,所以通常會使用Innodb存儲引擎,UUID太長以及無序,所以并不適合在Innodb中來作為主鍵,自增ID比較合適,但是隨著公司的業務發展,數據量將越來越大,需要對數據進行分表,而分表后,每個表中的數據都會按自己的節奏進行自增,很有可能出現ID沖突。這時就需要一個單獨的機制來負責生成唯一ID,生成出來的ID也可以叫做分布式ID,或全局ID。下面來分析各個生成分布式ID的機制。  這篇文章并不會分析的特別詳細,主要是做一些總結,以后再出一些詳細某個方案的文章。
這篇文章并不會分析的特別詳細,主要是做一些總結,以后再出一些詳細某個方案的文章。
第一種方案仍然還是基于數據庫的自增ID,需要單獨使用一個數據庫實例,在這個實例中新建一個單獨的表:
表結構如下:
CREATE DATABASE `SEQID`; CREATE TABLE SEQID.SEQUENCE_ID ( id bigint(20) unsigned NOT NULL auto_increment, stub char(10) NOT NULL default '', PRIMARY KEY (id), UNIQUE KEY stub (stub) ) ENGINE=MyISAM;
可以使用下面的語句生成并獲取到一個自增ID
begin;
replace into SEQUENCE_ID (stub) VALUES ('anyword');
select last_insert_id();
commit;stub字段在這里并沒有什么特殊的意義,只是為了方便的去插入數據,只有能插入數據才能產生自增id。而對于插入我們用的是replace,replace會先看是否存在stub指定值一樣的數據,如果存在則先delete再insert,如果不存在則直接insert。
這種生成分布式ID的機制,需要一個單獨的Mysql實例,雖然可行,但是基于性能與可靠性來考慮的話都不夠,業務系統每次需要一個ID時,都需要請求數據庫獲取,性能低,并且如果此數據庫實例下線了,那么將影響所有的業務系統。
為了解決數據庫可靠性問題,我們可以使用第二種分布式ID生成方案。
如果我們兩個數據庫組成一個主從模式集群,正常情況下可以解決數據庫可靠性問題,但是如果主庫掛掉后,數據沒有及時同步到從庫,這個時候會出現ID重復的現象。我們可以使用雙主模式集群,也就是兩個Mysql實例都能單獨的生產自增ID,這樣能夠提高效率,但是如果不經過其他改造的話,這兩個Mysql實例很可能會生成同樣的ID。需要單獨給每個Mysql實例配置不同的起始值和自增步長。
第一臺Mysql實例配置:
set @@auto_increment_offset = 1; -- 起始值 set @@auto_increment_increment = 2; -- 步長
第二臺Mysql實例配置:
set @@auto_increment_offset = 2; -- 起始值 set @@auto_increment_increment = 2; -- 步長
經過上面的配置后,這兩個Mysql實例生成的id序列如下: mysql1,起始值為1,步長為2,ID生成的序列為:1,3,5,7,9,... mysql2,起始值為2,步長為2,ID生成的序列為:2,4,6,8,10,...
對于這種生成分布式ID的方案,需要單獨新增一個生成分布式ID應用,比如DistributIdService,該應用提供一個接口供業務應用獲取ID,業務應用需要一個ID時,通過rpc的方式請求DistributIdService,DistributIdService隨機去上面的兩個Mysql實例中去獲取ID。
實行這種方案后,就算其中某一臺Mysql實例下線了,也不會影響DistributIdService,DistributIdService仍然可以利用另外一臺Mysql來生成ID。
但是這種方案的擴展性不太好,如果兩臺Mysql實例不夠用,需要新增Mysql實例來提高性能時,這時就會比較麻煩。
現在如果要新增一個實例mysql3,要怎么操作呢? 第一,mysql1、mysql2的步長肯定都要修改為3,而且只能是人工去修改,這是需要時間的。 第二,因為mysql1和mysql2是不停在自增的,對于mysql3的起始值我們可能要定得大一點,以給充分的時間去修改mysql1,mysql2的步長。 第三,在修改步長的時候很可能會出現重復ID,要解決這個問題,可能需要停機才行。
為了解決上面的問題,以及能夠進一步提高DistributIdService的性能,如果使用第三種生成分布式ID機制。
我們可以使用號段的方式來獲取自增ID,號段可以理解成批量獲取,比如DistributIdService從數據庫獲取ID時,如果能批量獲取多個ID并緩存在本地的話,那樣將大大提供業務應用獲取ID的效率。
比如DistributIdService每次從數據庫獲取ID時,就獲取一個號段,比如(1,1000],這個范圍表示了1000個ID,業務應用在請求DistributIdService提供ID時,DistributIdService只需要在本地從1開始自增并返回即可,而不需要每次都請求數據庫,一直到本地自增到1000時,也就是當前號段已經被用完時,才去數據庫重新獲取下一號段。
所以,我們需要對數據庫表進行改動,如下:
CREATE TABLE id_generator ( id int(10) NOT NULL, current_max_id bigint(20) NOT NULL COMMENT '當前最大id', increment_step int(10) NOT NULL COMMENT '號段的長度', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
這個數據庫表用來記錄自增步長以及當前自增ID的最大值(也就是當前已經被申請的號段的最后一個值),因為自增邏輯被移到DistributIdService中去了,所以數據庫不需要這部分邏輯了。
這種方案不再強依賴數據庫,就算數據庫不可用,那么DistributIdService也能繼續支撐一段時間。但是如果DistributIdService重啟,會丟失一段ID,導致ID空洞。
為了提高DistributIdService的高可用,需要做一個集群,業務在請求DistributIdService集群獲取ID時,會隨機的選擇某一個DistributIdService節點進行獲取,對每一個DistributIdService節點來說,數據庫連接的是同一個數據庫,那么可能會產生多個DistributIdService節點同時請求數據庫獲取號段,那么這個時候需要利用樂觀鎖來進行控制,比如在數據庫表中增加一個version字段,在獲取號段時使用如下SQL:
update id_generator set current_max_id=#{newMaxId}, version=version+1 where version = #{version}因為newMaxId是DistributIdService中根據oldMaxId+步長算出來的,只要上面的update更新成功了就表示號段獲取成功了。
為了提供數據庫層的高可用,需要對數據庫使用多主模式進行部署,對于每個數據庫來說要保證生成的號段不重復,這就需要利用最開始的思路,再在剛剛的數據庫表中增加起始值和步長,比如如果現在是兩臺Mysql,那么 mysql1將生成號段(1,1001],自增的時候序列為1,3,4,5,7.... mysql1將生成號段(2,1002],自增的時候序列為2,4,6,8,10...
更詳細的可以參考滴滴開源的TinyId:https://github.com/didi/tinyid/wiki/tinyid%E5%8E%9F%E7%90%86%E4%BB%8B%E7%BB%8D
在TinyId中還增加了一步來提高效率,在上面的實現中,ID自增的邏輯是在DistributIdService中實現的,而實際上可以把自增的邏輯轉移到業務應用本地,這樣對于業務應用來說只需要獲取號段,每次自增時不再需要請求調用DistributIdService了。
上面的三種方法總的來說是基于自增思想的,而接下來就介紹比較著名的雪花算法-snowflake。
我們可以換個角度來對分布式ID進行思考,只要能讓負責生成分布式ID的每臺機器在每毫秒內生成不一樣的ID就行了。
snowflake是twitter開源的分布式ID生成算法,是一種算法,所以它和上面的三種生成分布式ID機制不太一樣,它不依賴數據庫。
核心思想是:分布式ID固定是一個long型的數字,一個long型占8個字節,也就是64個bit,原始snowflake算法中對于bit的分配如下圖:
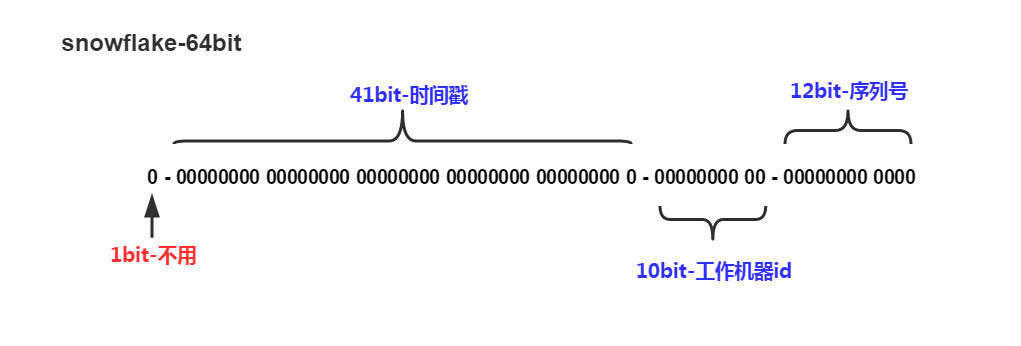
第一個bit位是標識部分,在java中由于long的最高位是符號位,正數是0,負數是1,一般生成的ID為正數,所以固定為0。
時間戳部分占41bit,這個是毫秒級的時間,一般實現上不會存儲當前的時間戳,而是時間戳的差值(當前時間-固定的開始時間),這樣可以使產生的ID從更小值開始;41位的時間戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年
工作機器id占10bit,這里比較靈活,比如,可以使用前5位作為數據中心機房標識,后5位作為單機房機器標識,可以部署1024個節點。
序列號部分占12bit,支持同一毫秒內同一個節點可以生成4096個ID
根據這個算法的邏輯,只需要將這個算法用Java語言實現出來,封裝為一個工具方法,那么各個業務應用可以直接使用該工具方法來獲取分布式ID,只需保證每個業務應用有自己的工作機器id即可,而不需要單獨去搭建一個獲取分布式ID的應用。
snowflake算法實現起來并不難,提供一個github上用java實現的:https://github.com/beyondfengyu/SnowFlake
在大廠里,其實并沒有直接使用snowflake,而是進行了改造,因為snowflake算法中最難實踐的就是工作機器id,原始的snowflake算法需要人工去為每臺機器去指定一個機器id,并配置在某個地方從而讓snowflake從此處獲取機器id。
但是在大廠里,機器是很多的,人力成本太大且容易出錯,所以大廠對snowflake進行了改造。
github地址:uid-generator
uid-generator使用的就是snowflake,只是在生產機器id,也叫做workId時有所不同。
uid-generator中的workId是由uid-generator自動生成的,并且考慮到了應用部署在docker上的情況,在uid-generator中用戶可以自己去定義workId的生成策略,默認提供的策略是:應用啟動時由數據庫分配。說的簡單一點就是:應用在啟動時會往數據庫表(uid-generator需要新增一個WORKER_NODE表)中去插入一條數據,數據插入成功后返回的該數據對應的自增唯一id就是該機器的workId,而數據由host,port組成。
對于uid-generator中的workId,占用了22個bit位,時間占用了28個bit位,序列化占用了13個bit位,需要注意的是,和原始的snowflake不太一樣,時間的單位是秒,而不是毫秒,workId也不一樣,同一個應用每重啟一次就會消費一個workId。
具體可參考https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
github地址:Leaf
美團的Leaf也是一個分布式ID生成框架。它非常全面,即支持號段模式,也支持snowflake模式。號段模式這里就不介紹了,和上面的分析類似。
Leaf中的snowflake模式和原始snowflake算法的不同點,也主要在workId的生成,Leaf中workId是基于ZooKeeper的順序Id來生成的,每個應用在使用Leaf-snowflake時,在啟動時都會都在Zookeeper中生成一個順序Id,相當于一臺機器對應一個順序節點,也就是一個workId。
總得來說,上面兩種都是自動生成workId,以讓系統更加穩定以及減少人工成功。
這里額外再介紹一下使用Redis來生成分布式ID,其實和利用Mysql自增ID類似,可以利用Redis中的incr命令來實現原子性的自增與返回,比如:
127.0.0.1:6379> set seq_id 1 // 初始化自增ID為1 OK 127.0.0.1:6379> incr seq_id // 增加1,并返回 (integer) 2 127.0.0.1:6379> incr seq_id // 增加1,并返回 (integer) 3
使用redis的效率是非常高的,但是要考慮持久化的問題。Redis支持RDB和AOF兩種持久化的方式。
RDB持久化相當于定時打一個快照進行持久化,如果打完快照后,連續自增了幾次,還沒來得及做下一次快照持久化,這個時候Redis掛掉了,重啟Redis后會出現ID重復。
AOF持久化相當于對每條寫命令進行持久化,如果Redis掛掉了,不會出現ID重復的現象,但是會由于incr命令過得,導致重啟恢復數據時間過長。
上述內容就是互聯網的分布式ID的示例分析,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





