溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關如何實踐CAP 一致性協議及應用,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
C 一致性:分布式環境中,一致性是指多個副本之間,在同一時刻能否有同樣的值
A 可用性:系統提供的服務必須一直處于可用的狀態。即使集群中一部分節點故障。
P 分區容錯性:系統在遇到節點故障,或者網絡分區時,任然能對外提供一致性和可用性的服務。以實際效果而言,分區相當于通信的時限要求。系統如果不能在一定實現內達成數據一致性,也就意味著發生了分區的情況。必須就當前操作在 C 和 A 之前作出選擇
假設系統中有 5 個節點,n1~n5。n1,n2,n3 在A物理機房。n4,n5 在 B 物理機房。現在發生了網絡分區,A 機房和 B 機房網絡不通。
保證一致性:此時客戶端在 A 機房寫入數據,不能同步到B機房。寫入失敗。此時失去了可用性。
保證可用性:數據在 A 機房的 n1~n3 節點都寫入成功后返回成功。數據在 B 機房的 n4~n5 節點也寫入數據,返回成功。同一份數據在 A 機房和 B 機房出現了數據不一致的情況。聰明如你,可以想到 zookeeper,當一個節點 down 掉,系統會將其剔出節點,然其它一半以上的節點寫入成功即可。是不是 zookeeper 同時滿足了 CAP 呢。其實這里有一個誤區,系統將其剔出節點。有一個隱含的條件是,系統引入了一個調度者,一個踢出壞節點的調度者。當調度者和 zookeeper 節點出現網絡分區,整個系統還是不可用的。
CA without P: 在分布式環境中,P 是不可避免的,天災(某軟公司的Azure被雷劈劈中)人禍(某里公司 A 和 B 機房之間的光纜被挖斷)都能導致P。
CP without A:相當于每個寫請求都須在Server之前強一致。P (分區)會導致同步時間無限延長。這個是可以保證的。例如數據庫的分布式事務,兩階段提交,三階段提交等。
AP without C: 當網絡分區發生,A 和 B 集群失去聯系。為了保證高可用,系統在寫入時,系統寫入部分節點就會返回成功,這會導致在一定時間之內,客戶端從不同的機器上面讀取到的是數據是不一樣的。例如 redis 主從異步復制架構,當 master down 掉,系統會切換到 slave,由于是異步復制,salve 不是最新的數據,會導致一致性的問題。
二階段提交( Two-phaseCommit )是指,在計算機網絡以及數據庫領域內,為了使基于分布式系統架構下的所有節點在進行事務提交時保持一致性而設計的一種算法( Algorithm )。通常,二階段提交也被稱為是一種協議( Protocol )。在分布式系統中,每個節點雖然可以知曉自己的操作時成功或者失敗,卻無法知道其他節點的操作的成功或失敗。當一個事務跨越多個節點時,為了保持事務的 ACID 特性,需要引入一個作為協調者的組件來統一掌控所有節點(稱作參與者)的操作結果并最終指示這些節點是否要把操作結果進行真正的提交(比如將更新后的數據寫入磁盤等等)。因此,二階段提交的算法思路可以概括為:參與者將操作成敗通知協調者,再由協調者根據所有參與者的反饋情報決定各參與者是否要提交操作還是中止操作。
協調者
參與者
詢問投票階段:事務協調者給每個參與者發送 Prepare 消息,參與者受到消息后,,要么在本地寫入 redo 和 undo 日志成功后,返回同意的消息,否者一個終止事務的消息。
執行初始化(執行提交):協調者在收到所有參與者的消息后,如果有一個返回終止事務,那么協調者給每個參與者發送回滾的指令。否者發送 commit 消息
協調者故障:備用協調者接管,并查詢參與者執行到什么地址
參與者故障:協調者會等待他重啟然后執行
協調者和參與者同時故障:協調者故障,然后參與者也故障。例如:有機器 1,2,3,4。其中 4 是協調者,1,2,3是參與者 4 給1,2 發完提交事務后故障了,正好3這個時候也故障了,注意這是 3 是沒有提交事務數據的。在備用協調者啟動了,去詢問參與者,由于3死掉了,一直不知道它處于什么狀態(接受了提交事務,還是反饋了能執行還是不能執行 3 個狀態)。面對這種情況,2PC,是不能解決的,要解決需要下文介紹的 3PC。
同步阻塞問題:由于所有參與的節點都是事務阻塞型的,例如 update tablesetstatus=1wherecurrent_day=20181103,那么參與者 table表的 current_day=20181103的記錄都會被鎖住,其他的要修改 current_day=20181103行的事務,都會被阻塞
單點故障阻塞其他事務:協調者再執行提交的階段 down 掉,所有的參與者出于鎖定事務資源的狀態中。無法完成相關的事務操作。
參與者和協調者同時 down 掉:協調者在發送完 commit 消息后 down 掉,而唯一接受到此消息的參與者也 down 掉了。新協調者接管,也是一個懵逼的狀態,不知道此條事務的狀態。無論提交或者回滾都是不合適的。這個是兩階段提交無法改變的
2PC 當時只考慮如果單機故障的情況,是可以勉強應付的。當遇到協調者和參與者同時故障的話,2PC 的理論是不完善的。此時 3PC 登場。
3PC 就是對 2PC 漏洞的補充協議。主要改動兩點:
在 2PC 的第一階段和第二階段插入一個準備階段,做到就算參與者和協調者同時故障也不阻塞,并且保證一致性。
在協調者和參與者之間引入超時機制
事務詢問階段( can commit 階段):協調者向參與者發送 commit 請求,然后等待參與者反應。這個和 2PC 階段不同的是,此時參與者沒有鎖定資源,沒有寫 redo,undo,執行回滾日志。回滾代價低
事務準備階段 (pre commit):如果參與者都返回ok,那么就發送Prepare消息,參與者本地執行redo和undo日志。否者就向參與者提交終止(abort)事務的請求。如果再發送Prepare消息的時候,等待超時,也會向參與者提交終止事務的請求。
執行事務階段(do commit):如果所有發送Prepare都返回成功,那么此時變為執行事務階段,向參與者發送commit事務的消息。否者回滾事務。在此階段參與者如果在一定時間內沒有收到docommit消息,觸發超時機制,會自己提交事務。此番處理的邏輯是,能夠進入此階段,說明在事務詢問階段所有節點都是好的。即使在提交的時候部分失敗,有理由相信,此時大部分節點都是好的。是可以提交的
不能解決網絡分區的導致的數據不一致的問題:例如 1~5 五個參與者節點,1,2,3 個節點在A機房,4,5 節點在 B 機房。在 pre commit階段,1~5 個節點都收到 Prepare 消息,但是節點1執行失敗。協調者向1~5個節點發送回滾事務的消息。但是此時A,B機房的網絡分區。1~3 號節點會回滾。但是 4~5 節點由于沒收到回滾事務的消息,而提交了事務。待網絡分區恢復后,會出現數據不一致的情況。
不能解決 fail-recover 的問題:
由于 3PC 有超時機制的存在,2PC 中未解決的問題,參與者和協調者同時 down 掉,也就解決了。一旦參與者在超時時間內沒有收到協調者的消息,就會自己提交。這樣也能避免參與者一直占用共享資源。但是其在網絡分區的情況下,不能保證數據的一致性。
像 2PC 和 3PC 都需要引入一個協調者的角色,當協調者 down 掉之后,整個事務都無法提交,參與者的資源都出于鎖定的狀態,對于系統的影響是災難性的,而且出現網絡分區的情況,很有可能會出現數據不一致的情況。有沒有不需要協調者角色,每個參與者來協調事務呢,在網絡分區的情況下,又能最大程度保證一致性的解決方案呢。此時 Paxos 出現了。
Paxos 算法是 Lamport 于 1990 年提出的一種基于消息傳遞的一致性算法。由于算法難以理解起初并沒有引起人們的重視,Lamport在八年后重新發表,即便如此Paxos算法還是沒有得到重視。2006 年 Google 的三篇論文石破天驚,其中的 chubby 鎖服務使用Paxos 作為 chubbycell 中的一致性,后來才得到關注。
Paxos 協議是一個解決分布式系統中,多個節點之間就某個值(提案)達成一致(決議)的通信協議。它能夠處理在少數節點離線的情況下,剩余的多數節點仍然能夠達成一致。即每個節點,既是參與者,也是決策者
Proposer:提議提案的服務器
Acceptor:批準提案的服務器
由于 Paxos 和下文提到的 zookeeper 使用的 ZAB 協議過于相似,詳細講解參照下文, Zookeeper原理部分。
Paxos 是論證了一致性協議的可行性,但是論證的過程據說晦澀難懂,缺少必要的實現細節,而且工程實現難度比較高廣為人知實現只有 zk 的實現 zab 協議。然后斯坦福大學 RamCloud 項目中提出了易實現,易理解的分布式一致性復制協議 Raft。Java,C++,Go 等都有其對應的實現。
節點狀態
Leader(主節點):接受 client 更新請求,寫入本地后,然后同步到其他副本中
Follower(從節點):從 Leader 中接受更新請求,然后寫入本地日志文件。對客戶端提供讀請求
Candidate(候選節點):如果 follower 在一段時間內未收到 leader 心跳。則判斷 leader 可能故障,發起選主提議。節點狀態從 Follower 變為 Candidate 狀態,直到選主結束
termId:任期號,時間被劃分成一個個任期,每次選舉后都會產生一個新的 termId,一個任期內只有一個 leader。termId 相當于 paxos 的 proposalId。
RequestVote:請求投票,candidate 在選舉過程中發起,收到 quorum (多數派)響應后,成為 leader。
AppendEntries:附加日志,leader 發送日志和心跳的機制
election timeout:選舉超時,如果 follower 在一段時間內沒有收到任何消息(追加日志或者心跳),就是選舉超時。
Leader 不會修改自身日志,只會做追加操作,日志只能由Leader轉向Follower。例如即將要down掉的Leader節點已經提交日志1,未提交日志 2,3。down 掉之后,節點 2 啟動最新日志只有 1,然后提交了日志 4。好巧不巧節點 1 又啟動了。此時節點 2 的編號 4 日志會追加到節點 1 的編號 1 日志的后面。節點 1 編號 2,3 的日志會丟掉。
不依賴各個節點物理時序保證一致性,通過邏輯遞增的 term-id 和 log-id 保證。
在超時時間內沒有收到 Leader 的心跳
啟動時
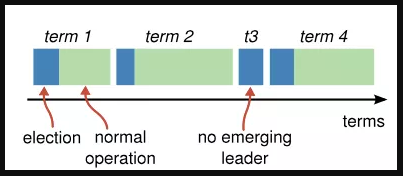
如圖 raft-2所示,Raft將時間分為多個 term(任期),term 以連續的整數來標識,每個 term 表示一個選舉的開始。例如 Follower 節點 1,在 term1 和 term2 連接處的時間,聯系不到 Leader,將 currentTerm 編號加1,變成2,進入了到term2任期,在 term2 的藍色部分選舉完成,綠色部分正常工作。
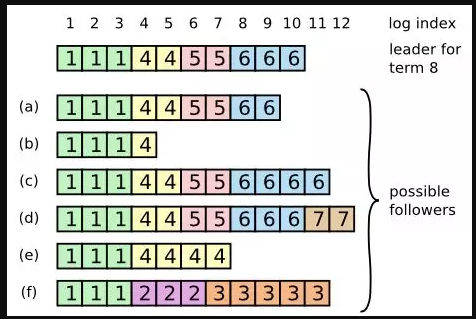
當然一個任期不一定能選出 Leader,那么會將 currentTerm 繼續加1,然后繼續進行選舉,例如圖中的 t3。選舉的原則是,每一輪選舉每個選民一張選票,投票的請求先到且選民發現候選人節點的日志 id 大于等于自己的,就會投票,否者不會投票。獲得半數以上的票的節點成為主節點,注意這并不是說選出來的事務 id 一定是最大的,例如下圖 raft-1a~f六個節點(正方形框里面的數字是選舉的輪數 term)。
在第四輪選舉中,a 先發出投票,六臺機器中,a~e 都會投 a,即使 f 不投 a,a 也會贏得選舉。如果沒有事務id(如剛啟動時),就遵循投票請求先來先頭。然后 Leader 將最新的日志復制到各個節點,再對外提供服務。
當然除了這些選舉限制,還會有其他的情況。如 commit 限制等保證,Leader 選舉成功一定包含所有的 commit 和 log。
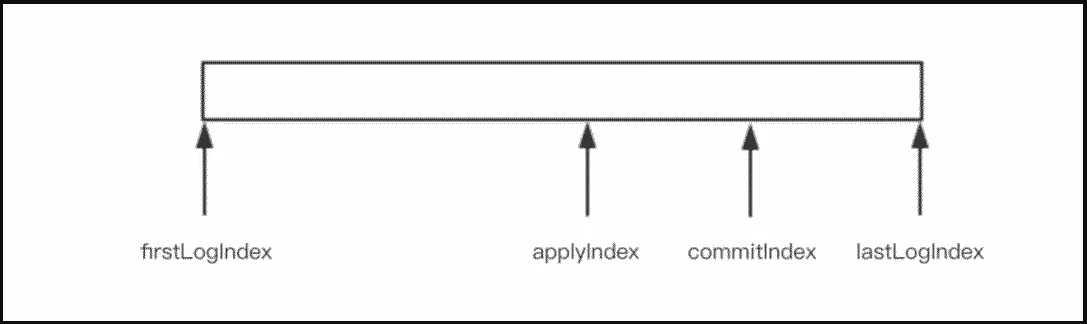
raft 日志寫入過程,主節點收到一個 x=1的請求后,會寫入本地日志,然后將 x=1的日志廣播出去,follower 如果收到請求,會將日志寫入本地 log ,然后返回成功。當 leader 收到半數以上的節點回應時,會將此日志的狀態變為 commit,然后廣播消息讓 follwer 提交日志。節點在 commit 日志后,會更新狀態機中的 logindex 。
firstLogIndex/lastLogIndex 為節點中開始和結束的索引位置(包含提交,未提交,寫入狀態機)commitIndex:已提交的索引。applyIndex:已寫入狀態機中的索引。
日志復制的本質是讓 follwer 和 Leader 的已提交的日志順序和內容都完全一樣,用于保證一致性。
具體的原則就是:
原則1:兩個日志在不同的 raft 節點中,如果有兩個相同的 term 和 logIndex ,則保證兩個日志的內容完全一樣。
原則2:兩段日志在不同的 raft 節點中,如果起始和終止的的 term,logIndex 都相同,那么兩段日志中日志內容完全一樣。
如何保證
第一個原則只需要在創建 logIndex 的時候使用新的 logIndex,保證 logIndex 的唯一性。而且創建之后不去更改。那么在 leader 復制到 follwer 之后,logIndex,term 和日志內容都沒變。
第二個原則,在 Leader 復制給 Follower 時,要傳遞當前最新日志 currenTermId 和currentLogIndex,以及上一條日志 preCurrentTermId 和 preCurrentLogIndex。如圖 raft-1,在 d 節點,term7,logIndex12。在給節點節點 a 同步時,發送(term7,logIndex11),(term7,logIndex12),a 節點沒有找到(term7,logIndex11)的日志,會讓Leader,d 節點重新發送。d 節點會重新發(term6,logIndex10)(term7,logIndex11),還是沒有(term6,logIndex10)的日志,依然會拒絕同步。接著發(term6,logIndex9)(term6,logIndex10)。現在a節點有了(term6,logIndex9)。那么 leader 節點就會將(term6,logIndex9) ~ (term7,logIndex11)日志內容給節點 a,節點 a 將會和節點 d 有一樣的日志。
Google 的粗粒度鎖服務 Chubby 的設計開發者 Burrows 曾經說過:“所有一致性協議本質上要么是 Paxos 要么是其變體”。Paxos 雖然解決了分布式系統中,多個節點就某個值達成一致性的通信協議。但是還是引入了其他的問題。由于其每個節點,都可以提議提案,也可以批準提案。當有三個及以上的 proposer 在發送 prepare 請求后,很難有一個 proposer 收到半數以上的回復而不斷地執行第一階段的協議,在這種競爭下,會導致選舉速度變慢。
所以 zookeeper 在 paxos 的基礎上,提出了 ZAB 協議,本質上是,只有一臺機器能提議提案(Proposer),而這臺機器的名稱稱之為 Leader 角色。其他參與者扮演 Acceptor 角色。為了保證 Leader 的健壯性,引入了 Leader 選舉機制。
ZAB協議還解決了這些問題
在半數以下節點宕機,依然能對臺提供服務
客戶端所有的寫請求,交由 Leader 來處理。寫入成功后,需要同步給所有的 follower 和 observer
leader 宕機,或者集群重啟。需要確保已經再 Leader 提交的事務最終都能被服務器提交,并且確保集群能快速回復到故障前的狀態
基本名詞
數據節點(dataNode):zk 數據模型中的最小數據單元,數據模型是一棵樹,由斜杠( / )分割的路徑名唯一標識,數據節點可以存儲數據內容及一系列屬性信息,同時還可以掛載子節點,構成一個層次化的命名空間。
事務及 zxid:事務是指能夠改變 Zookeeper 服務器狀態的操作,一般包括數據節點的創建與刪除、數據節點內容更新和客戶端會話創建與失效等操作。對于每個事務請求,zk 都會為其分配一個全局唯一的事務 ID,即 zxid,是一個 64 位的數字,高 32 位表示該事務發生的集群選舉周期(集群每發生一次 leader 選舉,值加 1),低 32 位表示該事務在當前選擇周期內的遞增次序(leader 每處理一個事務請求,值加 1,發生一次 leader 選擇,低 32 位要清 0)。
事務日志:所有事務操作都是需要記錄到日志文件中的,可通過 dataLogDir 配置文件目錄,文件是以寫入的第一條事務 zxid 為后綴,方便后續的定位查找。zk 會采取“磁盤空間預分配”的策略,來避免磁盤 Seek 頻率,提升 zk 服務器對事務請求的影響能力。默認設置下,每次事務日志寫入操作都會實時刷入磁盤,也可以設置成非實時(寫到內存文件流,定時批量寫入磁盤),但那樣斷電時會帶來丟失數據的風險。
事務快照:數據快照是 zk 數據存儲中另一個非常核心的運行機制。數據快照用來記錄 zk 服務器上某一時刻的全量內存數據內容,并將其寫入到指定的磁盤文件中,可通過 dataDir 配置文件目錄。可配置參數 snapCount,設置兩次快照之間的事務操作個數,zk 節點記錄完事務日志時,會統計判斷是否需要做數據快照(距離上次快照,事務操作次數等于snapCount/2~snapCount 中的某個值時,會觸發快照生成操作,隨機值是為了避免所有節點同時生成快照,導致集群影響緩慢)。
核心角色
leader:系統剛啟動時或者 Leader 崩潰后正處于選舉狀態;
follower:Follower 節點所處的狀態,Follower 與 Leader 處于數據同步階段;
observer:Leader 所處狀態,當前集群中有一個 Leader 為主進程。
節點狀態
LOOKING:節點正處于選主狀態,不對外提供服務,直至選主結束;
FOLLOWING:作為系統的從節點,接受主節點的更新并寫入本地日志;
LEADING:作為系統主節點,接受客戶端更新,寫入本地日志并復制到從節點
寫入節點后的數據,立馬就能被讀到,這是錯誤的。* zk 寫入是必須通過 leader 串行的寫入,而且只要一半以上的節點寫入成功即可。而任何節點都可提供讀取服務。例如:zk,有 1~5 個節點,寫入了一個最新的數據,最新數據寫入到節點 1~3,會返回成功。然后讀取請求過來要讀取最新的節點數據,請求可能被分配到節點 4~5 。而此時最新數據還沒有同步到節點4~5。會讀取不到最近的數據。如果想要讀取到最新的數據,可以在讀取前使用 sync 命令*。
zk啟動節點不能偶數臺,這也是錯誤的。zk 是需要一半以上節點才能正常工作的。例如創建 4 個節點,半數以上正常節點數是 3。也就是最多只允許一臺機器 down 掉。而 3 臺節點,半數以上正常節點數是 2,也是最多允許一臺機器 down 掉。4 個節點,多了一臺機器的成本,但是健壯性和 3 個節點的集群一樣。基于成本的考慮是不推薦的
節點啟動
節點運行期間無法與 Leader 保持連接,
Leader 失去一半以上節點的連接
ZAB 協議類似于兩階段提交,客戶端有一個寫請求過來,例如設置 /my/test 值為 1,Leader 會生成對應的事務提議(proposal)(當前 zxid為 0x5000010 提議的 zxid 為Ox5000011),現將 set/my/test1(此處為偽代碼)寫入本地事務日志,然后 set/my/test1日志同步到所有的follower。follower收到事務 proposal ,將 proposal 寫入到事務日志。如果收到半數以上 follower 的回應,那么廣播發起 commit 請求。follower 收到 commit 請求后。會將文件中的 zxid ox5000011 應用到內存中。
上面說的是正常的情況。有兩種情況。第一種 Leader 寫入本地事務日志后,沒有發送同步請求,就 down 了。即使選主之后又作為 follower 啟動。此時這種還是會日志會丟掉(原因是選出的 leader 無此日志,無法進行同步)。第二種 Leader 發出同步請求,但是還沒有 commit 就 down 了。此時這個日志不會丟掉,會同步提交到其他節點中。
現在 5 臺 zk 機器依次編號 1~5
節點 1 啟動,發出去的請求沒有響應,此時是 Looking 的狀態
節點 2 啟動,與節點 1 進行通信,交換選舉結果。由于兩者沒有歷史數據,即 zxid 無法比較,此時 id 值較大的節點 2 勝出,但是由于還沒有超過半數的節點,所以 1 和 2 都保持 looking 的狀態
節點 3 啟動,根據上面的分析,id 值最大的節點 3 勝出,而且超過半數的節點都參與了選舉。節點 3 勝出成為了 Leader
節點 4 啟動,和 1~3 個節點通信,得知最新的 leader 為節點 3,而此時 zxid 也小于節點 3,所以承認了節點 3 的 leader 的角色
節點 5 啟動,和節點 4 一樣,選取承認節點 3 的 leader 的角色
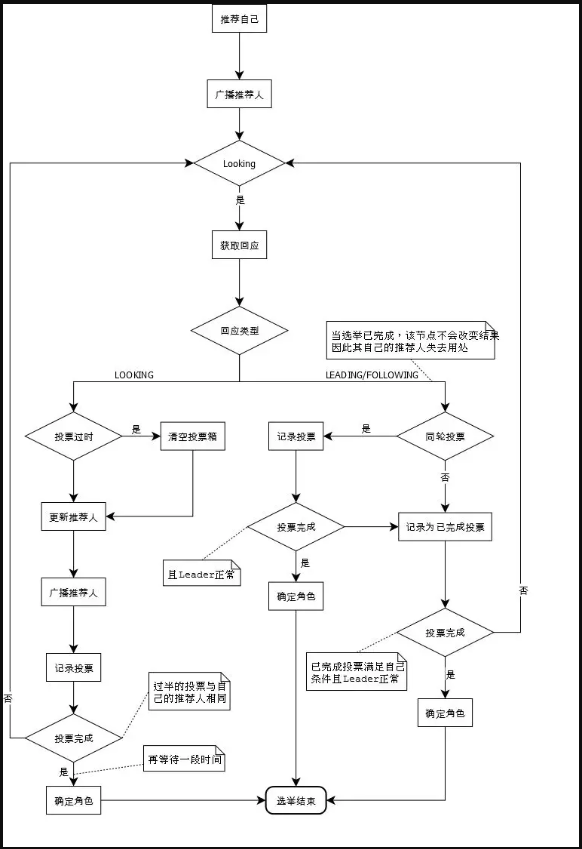
1. 節點 1 發起投票,第一輪投票先投自己,然后進入 Looking 等待的狀態。
2. 其他的節點(如節點 2 )收到對方的投票信息。節點 2 在 Looking 狀態,則將自己的投票結果廣播出去(此時走的是上圖中左側的 Looking 分支);如果不在 Looking 狀態,則直接告訴節點 1 當前的 Leader 是誰,就不要瞎折騰選舉了(此時走的是上圖右側的 Leading/following 分支)。
3. 此時節點 1,收到了節點 2 的選舉結果。如果節點 2 的 zxid 更大,那么清空投票箱,建立新的投票箱,廣播自己最新的投票結果。在同一次選舉中,如果在收到所有節點的投票結果后,如果投票箱中有一半以上的節點選出了某個節點,那么證明 leader 已經選出來了,投票也就終止了。否則一直循環。
zookeeper 的選舉,優先比較大 zxid,zxid 最大的節點代表擁有最新的數據。如果沒有 zxid,如系統剛剛啟動的時候,則比較機器的編號,優先選擇編號大的。
在選出 Leader 之后,zk 就進入狀態同步的過程。其實就是把最新的 zxid 對應的日志數據,應用到其他的節點中。此 zxid 包含 follower 中寫入日志但是未提交的 zxid 。稱之為服務器提議緩存隊列 committedLog 中的 zxid。
同步會完成三個 zxid 值的初始化。
peerLastZxid:該 learner 服務器最后處理的 zxid。 minCommittedLog:leader服務器提議緩存隊列 committedLog 中的最小 zxid。 maxCommittedLog:leader服務器提議緩存隊列 committedLog 中的最大 zxid。
系統會根據 learner 的 peerLastZxid和 leader 的 minCommittedLog, maxCommittedLog做出比較后做出不同的同步策略。
場景: peerLastZxid介于 minCommittedLogZxid和 maxCommittedLogZxid間。
此種場景出現在,上文提到過的,Leader 發出了同步請求,但是還沒有 commit 就 down 了。 leader 會發送 Proposal 數據包,以及 commit 指令數據包。新選出的 leader 繼續完成上一任 leader 未完成的工作。
例如此刻 Leader 提議的緩存隊列為 0x20001,0x20002,0x20003,0x20004,此處 learn 的 peerLastZxid 為 0x20002,Leader會將 0x20003 和 0x20004 兩個提議同步給 learner。
此種場景出現在,上文提到過的,Leader 寫入本地事務日志后,還沒發出同步請求,就 down 了,然后在同步日志的時候作為 learner 出現。
例如即將要 down 掉的 leader 節點 1,已經處理了 0x20001,0x20002,在處理 0x20003 時還沒發出提議就 down 了。后來節點 2 當選為新 leader,同步數據的時候,節點 1 又神奇復活。如果新 leader 還沒有處理新事務,新 leader 的隊列為,0x20001, 0x20002,那么僅讓節點 1 回滾到 0x20002 節點處,0x20003 日志廢棄,稱之為僅回滾同步。如果新 leader 已經處理 0x30001 , 0x30002 事務,那么新 leader 此處隊列為0x20001,0x20002,0x30001,0x30002,那么讓節點 1 先回滾,到 0x20002 處,再差異化同步0x30001,0x30002。
peerLastZxid小于 minCommittedLogZxid或者 leader 上面沒有緩存隊列。leader 直接使用 SNAP 命令進行全量同步。
當前開源的緩存 kv 系統,大都是 AP 系統,例如設置主從同步集群 redis,master 異步同步到 slave。雖然在 master 停止服務后,slave 會頂上來。但是在 master 寫入了數據,但是還沒來得及同步到 slave 就 down 了,然后 slave 被選為主節點繼續對外提供服務的情況下,會丟失部分數據。這對于要求強一致性的系統來說是不可接受的。例如很多場景下 redis 做分布式鎖,有天然的缺陷在里面,如果 master 停止服務,這個鎖不很不可靠的,雖然出現的幾率很小,但一旦出現,將是致命的錯誤。
為了實現 CP 的 KV 存儲系統,且要兼容現有的 redis 業務。有贊開發了 ZanKV(先已開源ZanRedisDB)。
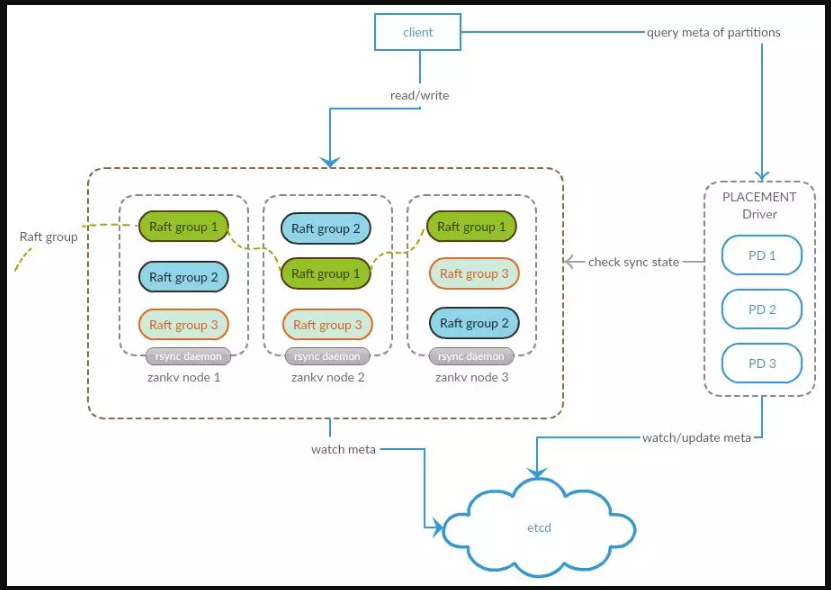
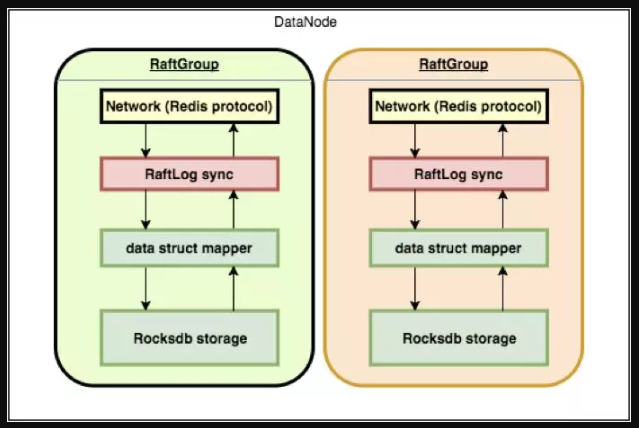
底層的存儲結構是 RocksDB(底層采用 LSM 數據結構)。一個 setx=1的會通過 redis protocol 協議傳輸,內容會通過 Raft 協議,同步寫入到其他的節點的 RocksDB。有了Raft 理論的加持,RocksDB優秀的存儲性能,即使遇到網絡分區,master 節點 down 掉, slave 節點 down 掉,等一系列異常情況,其都能輕松應對。在擴容方面,系統用選擇維護映射表的方式來建立分區和節點的關系,映射表會根據一定的算法并配合靈活的策略生成,來達到方便擴容。具體原理可參見《使用開源技術構建有贊分布式KV存儲服務》。
從三個方面介紹了一致性,首先是描述分布架構中的核心理論-CAP,以及其簡單的證明。第二部分介紹了 CAP 里面協議,重點介紹了 Raft 協議。第三部分,重點介紹了常用的 zookeeper 原理。
為了保證數據 commit 之后不可丟,系統都會采用(WAL write ahead log)(在每次修改數據之前先寫操作內容日志,然后再去修改數據。即使修改數據時異常,也可以通過操作內容日志恢復數據)
分布式存儲系統中,是假設機器是不穩定,隨時都有可能 down 掉的情況下來設計的。也就是說就算機器 down 掉了,用戶寫入的數據也不能丟,避免單點故障。為此每一份寫入的數據,需要在多個副本中同時存放。例如 zk 節點數據復制,etcd 的數據復制。而復制數據給節點又會帶來一致性的問題,例如主節點和從節點數據不一致改如何去同步數據。也會帶來可用性的問題,如 leader 節點 down 掉,如何快速選主,恢復數據等。好在已有成熟的理論如 Paxos 協議,ZAB 協議 Raft 協議等做為支撐。
上述就是小編為大家分享的如何實踐CAP 一致性協議及應用了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





