溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Java 多線程核心知識是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Java 多線程核心知識是什么”吧!
多線程相對于其他 Java 知識點來講,有一定的學習門檻,并且了解起來比較費勁。在平時工作中如若使用不當會出現數據錯亂、執行效率低(還不如單線程去運行)或者死鎖程序掛掉等等問題,所以掌握了解多線程至關重要。
本文從基礎概念開始到最后的并發模型由淺入深,講解下線程方面的知識。
本節我將帶大家了解多線程中幾大基礎概念。
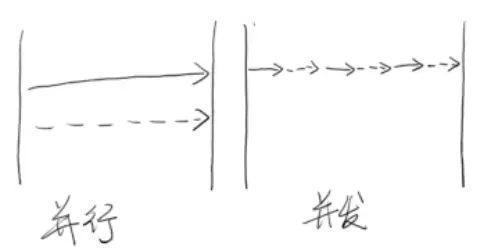
并行,表示兩個線程同時做事情。
并發,表示一會做這個事情,一會做另一個事情,存在著調度。單核 CPU 不可能存在并行(微觀上)。
1.jpeg
臨界區用來表示一種公共資源或者說是共享數據,可以被多個線程使用。但是每一次,只能有一個線程使用它,一旦臨界區資源被占用,其他線程要想使用這個資源,就必須等待。
3.jpeg
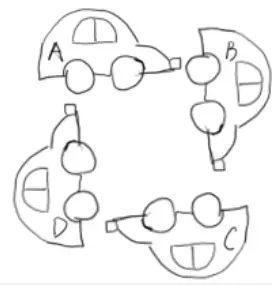
假設有兩個線程1、2,它們都需要資源 A/B,假設1號線程占有了 A 資源,2號線程占有了 B 資源;由于兩個線程都需要同時擁有這兩個資源才可以工作,為了避免死鎖,1號線程釋放了 A 資源占有鎖,2號線程釋放了 B 資源占有鎖;此時 AB 空閑,兩個線程又同時搶鎖,再次出現上述情況,此時發生了活鎖。
簡單類比,電梯遇到人,一個進的一個出的,對面占路,兩個人同時往一個方向讓路,來回重復,還是堵著路。
如果線上應用遇到了活鎖問題,恭喜你中獎了,這類問題比較難排查。
饑餓是指某一個或者多個線程因為種種原因無法獲得所需要的資源,導致一直無法執行。
在線程的生命周期中,它要經歷創建、可運行、不可運行幾種狀態。
當用 new 操作符創建一個新的線程對象時,該線程處于創建狀態。
處于創建狀態的線程只是一個空的線程對象,系統不為它分配資源。
執行線程的 start() 方法將為線程分配必須的系統資源,安排其運行,并調用線程體——run()方法,這樣就使得該線程處于可運行狀態(Runnable)。
這一狀態并不是運行中狀態(Running),因為線程也許實際上并未真正運行。
當發生下列事件時,處于運行狀態的線程會轉入到不可運行狀態:
調用了 sleep() 方法;
線程調用 wait() 方法等待特定條件的滿足;
線程輸入/輸出阻塞;
返回可運行狀態;
處于睡眠狀態的線程在指定的時間過去后;
如果線程在等待某一條件,另一個對象必須通過 notify() 或 notifyAll() 方法通知等待線程條件的改變;
如果線程是因為輸入輸出阻塞,等待輸入輸出完成。
線程的優先級是為了在多線程環境中便于系統對線程的調度,優先級高的線程將優先執行。一個線程的優先級設置遵從以下原則:
線程創建時,子繼承父的優先級;
線程創建后,可通過調用 setPriority() 方法改變優先級;
線程的優先級是1-10之間的正整數。
線程調度器選擇優先級最高的線程運行。但是,如果發生以下情況,就會終止線程的運行:
線程體中調用了 yield() 方法,讓出了對 CPU 的占用權;
線程體中調用了 sleep() 方法,使線程進入睡眠狀態;
線程由于 I/O 操作而受阻塞;
另一個更高優先級的線程出現;
在支持時間片的系統中,該線程的時間片用完。
單線程創建方式比較簡單,一般只有兩種方式:繼承 Thread 類和實現 Runnable 接口;這兩種方式比較常用就不在 Demo 了,但是對于新手需要注意的問題有:
不管是繼承 Thread 類還是實現 Runable 接口,業務邏輯是寫在 run 方法里面,線程啟動的時候是執行 start() 方法;
開啟新的線程,不影響主線程的代碼執行順序也不會阻塞主線程的執行;
新的線程和主線程的代碼執行順序是不能夠保證先后的;
對于多線程程序,從微觀上來講某一時刻只有一個線程在工作,多線程目的是讓 CPU 忙起來;
通過查看 Thread 的源碼可以看到,Thread 類是實現了 Runnable 接口的,所以這兩種本質上來講是一個;
PS:平時在工作中也可以借鑒這種代碼結構,對上層調用來講提供更多的選擇,作為服務提供方核心業務歸一維護
通過上面的介紹,完全可以開發一個多線程的程序,為什么還要引入線程池呢。主要是因為上述單線程方式存在以下幾個問題:
線程的工作周期:線程創建所需時間為 T1,線程執行任務所需時間為 T2,線程銷毀所需時間為 T3,往往是 T1+T3 大于 T2,所有如果頻繁創建線程會損耗過多額外的時間;
如果有任務來了,再去創建線程的話效率比較低,如果從一個池子中可以直接獲取可用的線程,那效率會有所提高。所以線程池省去了任務過來,要先創建線程再去執行的過程,節省了時間,提升了效率;
線程池可以管理和控制線程,因為線程是稀缺資源,如果無限制的創建,不僅會消耗系統資源,還會降低系統的穩定性,使用線程池可以進行統一的分配,調優和監控;
線程池提供隊列,存放緩沖等待執行的任務。
大致總結了上述的幾個原因,所以可以得出一個結論就是在平時工作中,如果要開發多線程程序,盡量要使用線程池的方式來創建和管理線程。
通過線程池創建線程從調用 API 角度來說分為兩種,一種是原生的線程池,另外該一種是通過 Java 提供的并發包來創建,后者比較簡單,后者其實是對原生的線程池創建方式做了一次簡化包裝,讓調用者使用起來更方便,但道理都是一樣的。所以搞明白原生線程池的原理是非常重要的。
通過 ThreadPoolExecutor 創建線程池,API 如下所示:
/** * public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime, * TimeUnit unit,BlockingQueue<Runnable> workQueue) * corePoolSize用于指定核心線程數量 * maximumPoolSize指定最大線程數 * keepAliveTime和TimeUnit指定線程空閑后的最大存活時間 * workQueue則是線程池的緩沖隊列,還未執行的線程會在隊列中等待 * 監控隊列長度,確保隊列有界 * 不當的線程池大小會使得處理速度變慢,穩定性下降,并且導致內存泄露。如果配置的線程過少,則隊列會持續變大,消耗過多內存。 * 而過多的線程又會 由于頻繁的上下文切換導致整個系統的速度變緩——殊途而同歸。隊列的長度至關重要,它必須得是有界的,這樣如果線程池不堪重負了它可以暫時拒絕掉新的請求。 * ExecutorService 默認的實現是一個無界的 LinkedBlockingQueue。 */ private ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, corePoolSize+1, 10l, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(1000));
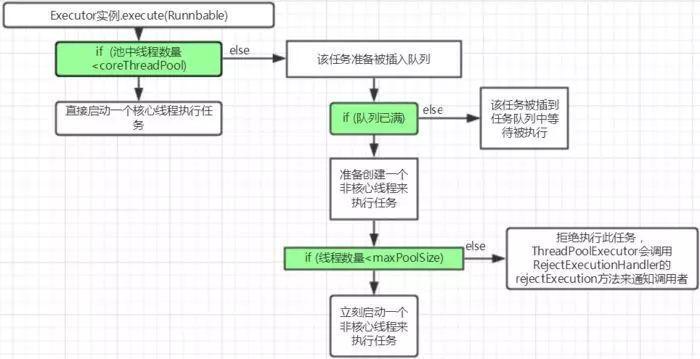
先來解釋下其中的參數含義(如果看的比較模糊可以大致有個印象,后面的圖是關鍵)。
corePoolSize
核心池的大小。
在創建了線程池后,默認情況下,線程池中并沒有任何線程,而是等待有任務到來才創建線程去執行任務,除非調用了 prestartAllCoreThreads() 或者 prestartCoreThread() 方法,從這兩個方法的名字就可以看出,是預創建線程的意思,即在沒有任務到來之前就創建 corePoolSize 個線程或者一個線程。默認情況下,在創建了線程池后,線程池中的線程數為0,當有任務來之后,就會創建一個線程去執行任務,當線程池中的線程數目達到 corePoolSize 后,就會把到達的任務放到緩存隊列當中。
maximumPoolSize
線程池最大線程數,這個參數也是一個非常重要的參數,它表示在線程池中最多能創建多少個線程。
keepAliveTime
表示線程沒有任務執行時最多保持多久時間會終止。默認情況下,只有當線程池中的線程數大于 corePoolSize 時,keepAliveTime 才會起作用,直到線程池中的線程數不大于 corePoolSize,即當線程池中的線程數大于 corePoolSize 時,如果一個線程空閑的時間達到 keepAliveTime,則會終止,直到線程池中的線程數不超過 corePoolSize。
但是如果調用了 allowCoreThreadTimeOut(boolean) 方法,在線程池中的線程數不大于 corePoolSize 時,keepAliveTime 參數也會起作用,直到線程池中的線程數為0。
unit
參數 keepAliveTime 的時間單位。
workQueue
一個阻塞隊列,用來存儲等待執行的任務,這個參數的選擇也很重要,會對線程池的運行過程產生重大影響,一般來說,這里的阻塞隊列有以下這幾種選擇:ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue。
threadFactory
線程工廠,主要用來創建線程。
handler
表示當拒絕處理任務時的策略,有以下四種取值:
ThreadPoolExecutor.AbortPolicy:丟棄任務并拋出 RejectedExecutionException 異常;
ThreadPoolExecutor.DiscardPolicy:也是丟棄任務,但是不拋出異常;
ThreadPoolExecutor.DiscardOldestPolicy:丟棄隊列最前面的任務,然后重新嘗試執行任務(重復此過程);
ThreadPoolExecutor.CallerRunsPolicy:由調用線程處理該任務。
上面這些參數是如何配合工作的呢?請看下圖:
5.jpeg
以上就是原生線程池創建的核心原理。除了原生線程池之外并發包還提供了簡單的創建方式,上面也說了它們是對原生線程池的一種包裝,可以讓開發者簡單快捷的創建所需要的線程池。
創建一個線程的線程池,在這個線程池中始終只有一個線程存在。如果線程池中的線程因為異常問題退出,那么會有一個新的線程來替代它。此線程池保證所有任務的執行順序按照任務的提交順序執行。
創建固定大小的線程池。每次提交一個任務就創建一個線程,直到線程達到線程池的最大大小。線程池的大小一旦達到最大值就會保持不變,如果某個線程因為執行異常而結束,那么線程池會補充一個新線程。
可根據實際情況,調整線程數量的線程池,線程池中的線程數量不確定,如果有空閑線程會優先選擇空閑線程,如果沒有空閑線程并且此時有任務提交會創建新的線程。在正常開發中并不推薦這個線程池,因為在極端情況下,會因為 newCachedThreadPool 創建過多線程而耗盡 CPU 和內存資源。
此線程池可以指定固定數量的線程來周期性的去執行。比如通過 scheduleAtFixedRate 或者 scheduleWithFixedDelay 來指定周期時間。
PS:另外在寫定時任務時(如果不用 Quartz 框架),最好采用這種線程池來做,因為它可以保證里面始終是存在活的線程的。
在阿里的 Java 開發手冊時有一條是不推薦使用 Executors 去創建,而是推薦去使用 ThreadPoolExecutor 來創建線程池。
這樣做的目的主要原因是:使用 Executors 創建線程池不會傳入核心參數,而是采用的默認值,這樣的話我們往往會忽略掉里面參數的含義,如果業務場景要求比較苛刻的話,存在資源耗盡的風險;另外采用 ThreadPoolExecutor 的方式可以讓我們更加清楚地了解線程池的運行規則,不管是面試還是對技術成長都有莫大的好處。
改了變量,其他線程可以立即知道。保證可見性的方法有以下幾種:
volatile
加入 volatile 關鍵字的變量在進行匯編時會多出一個 lock 前綴指令,這個前綴指令相當于一個內存屏障,內存屏障可以保證內存操作的順序。當聲明為 volatile 的變量進行寫操作時,那么這個變量需要將數據寫到主內存中。
由于處理器會實現緩存一致性協議,所以寫到主內存后會導致其他處理器的緩存無效,也就是線程工作內存無效,需要從主內存中重新刷新數據。
到此,相信大家對“Java 多線程核心知識是什么”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





