溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關并發Bug之源有哪些,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
一個線程對共享變量的修改,另外一個線程能夠立刻看到,我們稱為可見性
談到可見性,要先引出 JMM (Java Memory Model) 概念, 即 Java 內存模型,Java 內存模型規定,將所有的變量都存放在 主內存 中,當線程使用變量時,會把主內存里面的變量 復制 到自己的工作空間或者叫作 私有內存 ,線程讀寫變量時操作的是自己工作內存中的變量。
用 Git 的工作流程理解上面的描述就很簡單了,Git 遠程倉庫就是主內存,Git 本地倉庫就是自己的工作內存
文字描述有些抽象,我們來圖解說明:
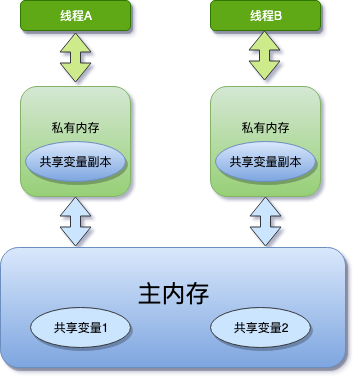
看這個場景:
主內存中有變量 x,初始值為 0
線程 A 要將 x 加 1,先將 x=0 拷貝到自己的私有內存中,然后更新 x 的值
線程 A 將更新后的 x 值回刷到主內存的時間是不固定的
剛好在線程 A 沒有回刷 x 到主內存時,線程 B 同樣從主內存中讀取 x,此時為 0,和線程 A 一樣的操作,最后期盼的 x=2 就會編程 x=1
這就是線程可見性的問題
JMM 是一個抽象的概念,在實際實現中,線程的工作內存是這樣的: 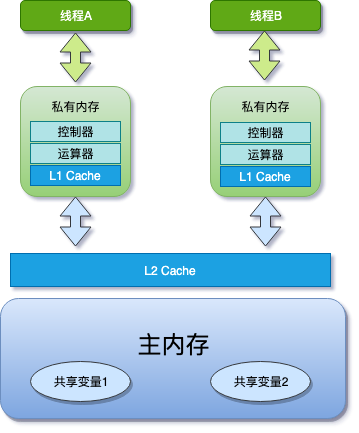
為了平衡內存/IO 短板,會在 CPU 上增加緩存,每個核都只有自己的一級緩存,甚至有一個所有 CPU 都共享的二級緩存,就是上圖的樣子了,都說這么設計是硬件同學留給軟件同學的一個坑,但能否跳過去這個坑也是衡量軟件同學是否走向 Java 進階的關鍵指標吧......
小提示
從上圖中你也可以看出,在 Java 中,所有的實例域,靜態域和數組元素都存儲在堆內存中,堆內存在線程之間共享,這些在后續文章中都稱之為「共享變量」,局部變量,方法定義參數和異常處理器參數不會在線程之間共享,所以他們不會有內存可見性的問題,也就不受內存模型的影響
一句話,要想解決多線程可見性問題,所有線程都必須要刷取主內存中的變量 怎么解決可見性問題呢?Java 關鍵字 volatile 幫你搞定,后續章節會分析......
原子(atom)指化學反應不可再分的基本微粒,原子性操作你應該能感受到其含義:
所謂原子操作是指不會被線程調度機制打斷的操作;這種操作一旦開始,就一直運行到結束,中間不會有任何 context switch
小品「鐘點工」有一句非常經典的臺詞,要把大象裝冰箱,總共分幾步?
來看一小段程序: 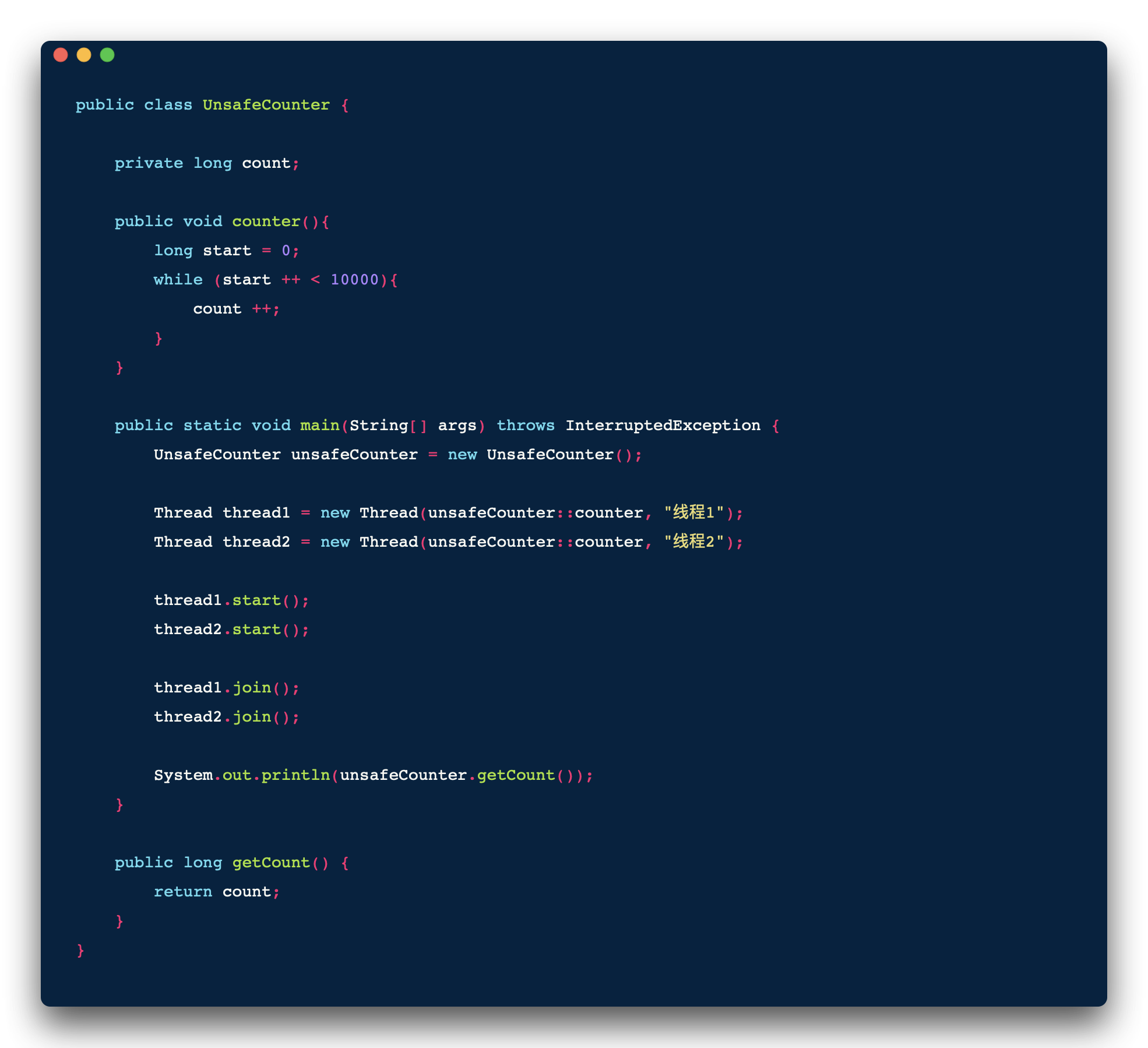
多線程情況下能得到我們期盼的 count = 20000 的值嗎? 也許有同學會認為,線程調用的 counter 方法只有一個 count++ 操作,是單一操作,所以是原子性的,非也。在線程第一講中說過我們不能用高級語言思維來理解 CPU 的處理方式,count++ 轉換成 CPU 指令則需要三步,通過下面命令解析出匯編指令等信息:
javap -c UnsafeCounter
截取 counter 方法的匯編指令來看: 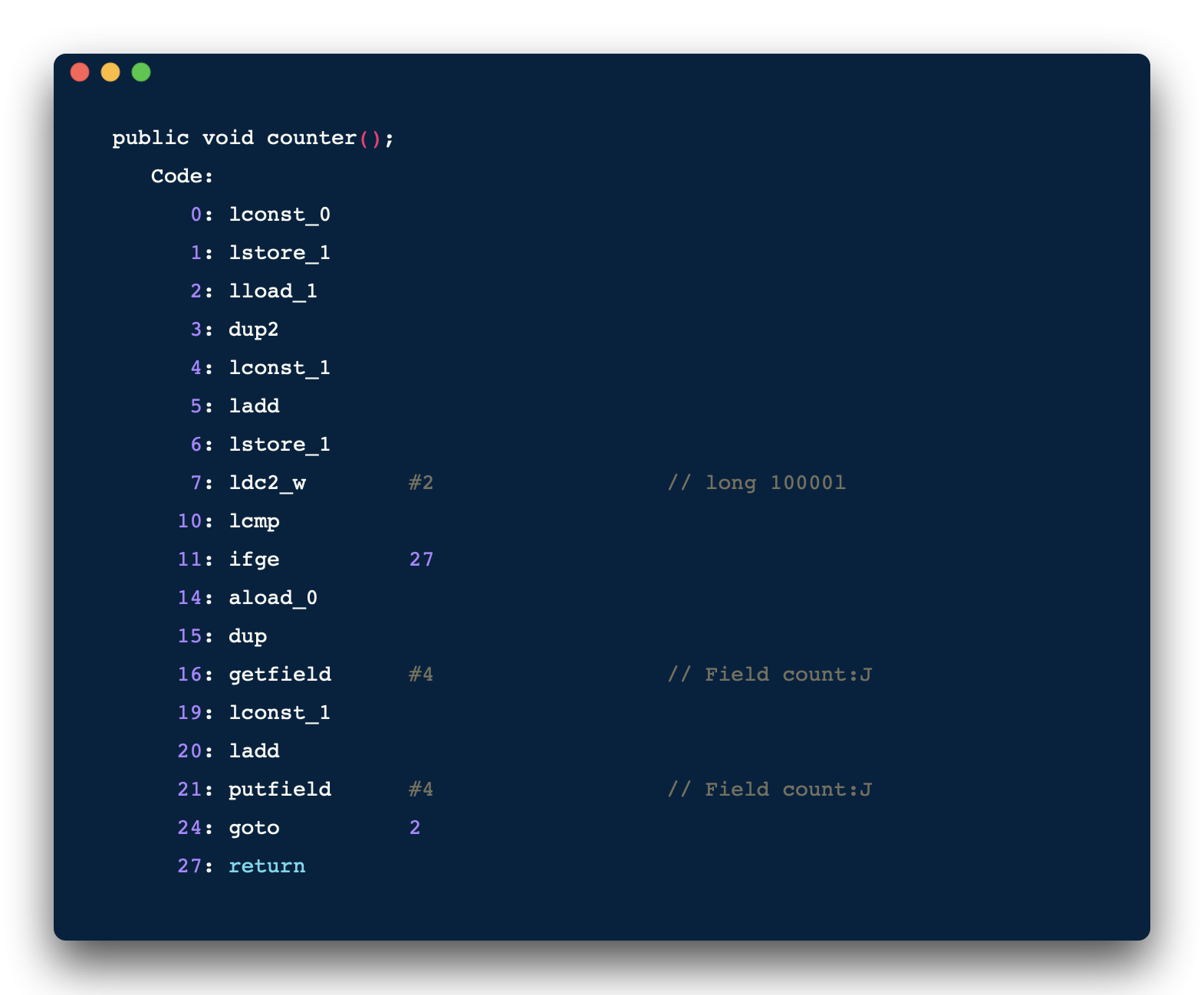
解釋一下上面的指令, 16 : 獲取當前 count 值,并且放入棧頂 19 : 將常量 1 放入棧頂 20 : 將當前棧頂中兩個值相加,并把結果放入棧頂 21 : 把棧頂的結果再賦值給 count
由此可見,簡單的 count++ 不是一步操作,被轉換為匯編后就不具備原子性了,就好比大象裝冰箱,其實要分三步:
第一步,把冰箱門打開;第二步,把大象放進去;第三步,把冰箱門帶上
結合 JMM 結構圖理解,說明一下為什么很難得到 count=20000 的結果:
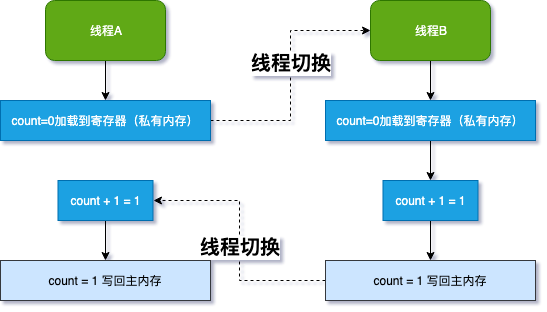
多線程計數器,如何保證多個操作的原子性呢?最粗暴的方式是在方法上加 synchronized 關鍵字,比如這樣: 
問題是解決了,如果 synchronized 是萬能良方,那么也許并發就沒那么多事了,可以靠一個 synchronized 走天下了,事實并不是這樣,synchronized 是獨占鎖 (同一時間只能有一個線程可以調用),沒有獲取鎖的線程會被阻塞;另外也會帶來很多線程切換的上下文開銷
所以 JDK 中就有了非阻塞 CAS (Compare and Swap) 算法實現的原子操作類 AtomicLong 等工具類,看過源碼的同學也許會發現一個共同特點,所有原子類中都有下面這樣一段代碼:
private static final Unsafe unsafe = Unsafe.getUnsafe();
這個類是 JDK 的 rt.jar 包中的 Unsafe 類提供了 硬件級別 的原子性操作,類中的方法都是 native 修飾的,后面介紹原子類之前也會先說明這個類中的幾個方法,這里先簡單介紹有個印象即可。
有同學不理解我剛剛提到的線程上下文切換開銷很大是什么意思,舉 2個例子你就懂了:
你(CPU)在看兩本書(兩個線程),看第一本書很短時間后要去看第二本書,看第二本書很短時間后又回看第一本書,并要精確的記得看到第幾行,當初看到了什么(CPU 記住線程級別的信息),當讓你 "同時" 看 10 本甚至更多,切換的開銷就很大了吧
綜藝節目中有很多游戲,讓你一邊數錢,又要一邊做其他的事,最終保證多樣事情都做正確,大腦開銷大不大,你試試就知道了????
生活中你問候他人「吃了嗎你?」和「你吃了嗎?」是一個意思,你寫的是下面程序:
a = 1; b = 2; System.out.println(a); System.out.println(b);
編譯器優化后可能就變成了這樣:
b = 2; a = 1; System.out.println(a); System.out.println(b);
這個情況,編譯器調整了語句順序沒什么影響,但編譯器 擅自 優化順序,就給我們埋下了雷,比如應用雙重檢查方式實現的單例

一切又很完美是不是,非也,問題出現在 instance = new Singleton();,這 1 行代碼轉換成了 CPU 指令后又變成了 3 個,我們理解 new 對象應該是這樣的:
分配一塊內存 M
在內存 M 上初始化 Singleton 對象
然后 M 的地址賦值給 instance 變量
但編譯器擅自優化后可能就變成了這樣:
分配一塊內存 M
然后將 M 的地址賦值給 instance 變量
在內存 M 上初始化 Singleton 對象
首先 new 對象分了三步,給 CPU 留下了切換線程的機會;另外,編譯器優化后的順序可能導致問題的發生,來看:
線程 A 先執行 getInstance 方法,當執行到指令 2 時,恰好發生了線程切換
線程 B 剛進入到 getInstance 方法,判斷 if 語句 instance 是否為空
線程 A 已經將 M 的地址賦值給了 instance 變量,所以線程 B 認為 instance 不為空
線程 B 直接 return instance 變量
CPU 切換回線程 A,線程 A 完成后續初始化內容
我們還是畫個圖說明一下:
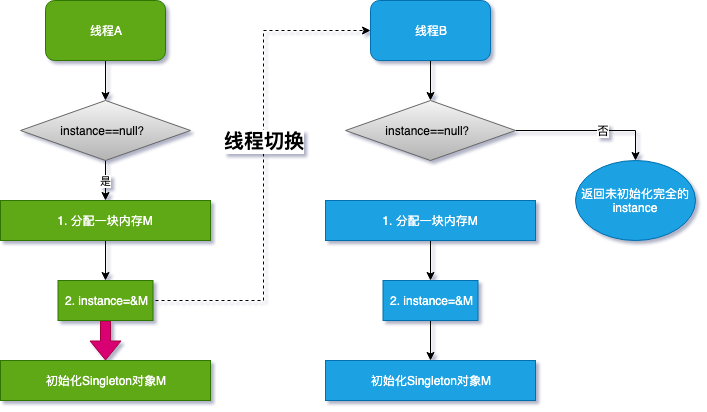
如果線程 A 執行到第 2 步,線程切換,由于線程 A 沒有把紅色箭頭執行完全,線程 B 就會得到一個未初始化完全的對象,訪問 instance 成員變量的時候就可能發生 NPE,如果將變量 instance 用 volatile 或者 final 修飾(涉及到類的加載機制,可看我之前寫的文章: 雙親委派模型:大廠高頻面試題,輕松搞定),問題就解決了.
你所看到的程序并不一定是編譯器優化/編譯后的 CPU 指令,大象裝冰箱是是個程序,但其隱含三個步驟,學習并發編程,你要按照 CPU 的思維考慮問題,所以你需要深刻理解 可見性/原子性/有序性 ,這是產生并發 Bug 的源頭
本節說明了三個問題,下面的文章也會逐個分析解決以上問題的辦法,以及相對優的方案,請持續關注,另外關于并發的測試代碼我都會按例上傳到 github,公眾號回復「demo」——> concurrency 獲取更多內容
為什么用 final 修飾的變量就是線程安全的了呢?
你會經常查看 CPU 匯編指令嗎?
如果讓你寫單例,你通常會采用哪種實現?

這是一款 IDEA 的主題插件,安裝后,選擇 Material Palenight 主題,同時作出如下設置 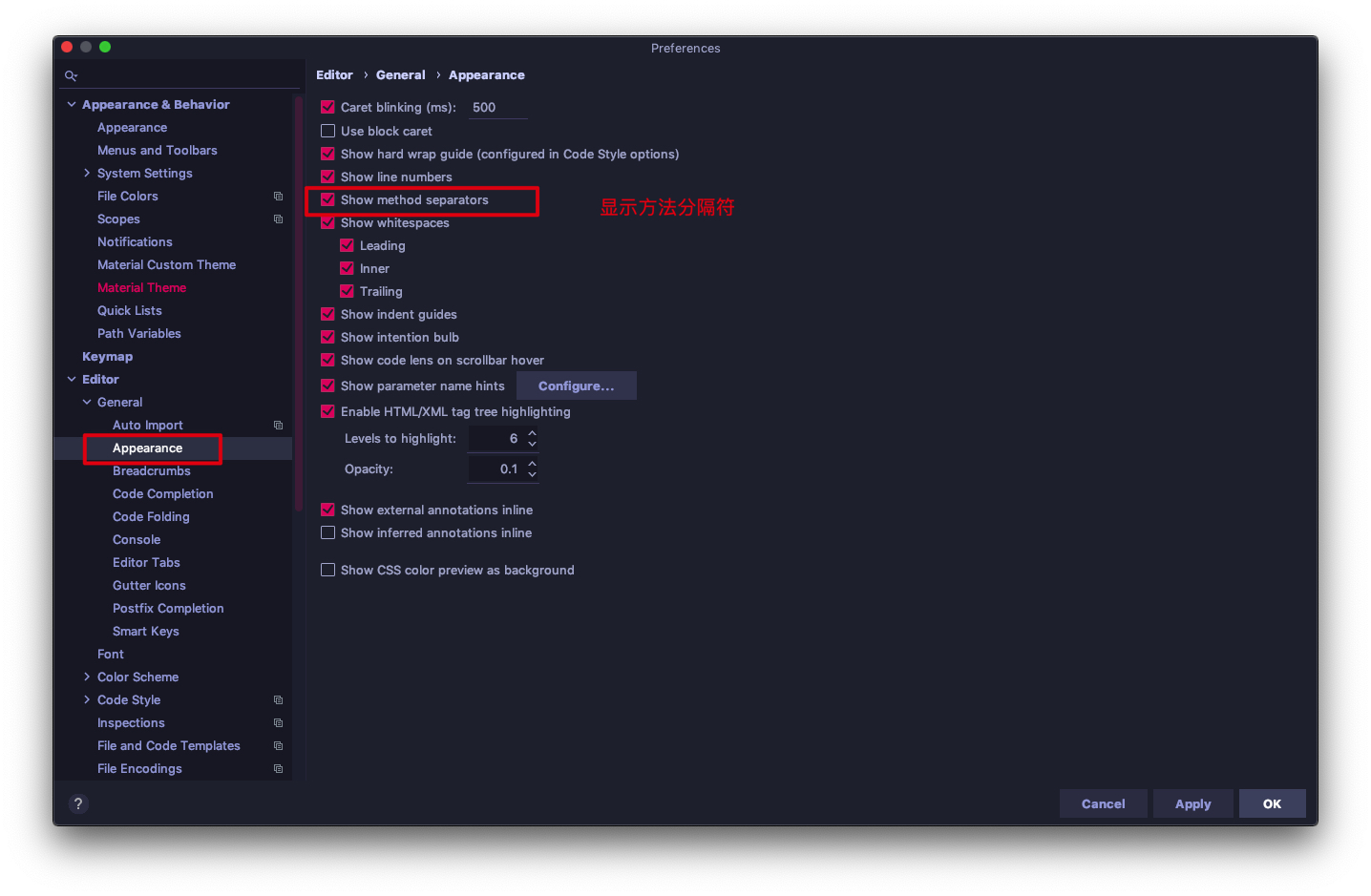
以上就是并發Bug之源有哪些,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





