溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
MySQL 日志系統中的redolog和binlog的用法,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
之前我們了解了一條查詢語句的執行流程,并介紹了執行過程中涉及的處理模塊。一條查詢語句的執行過程一般是經過連接器、分析器、優化器、執行器等功能模塊,最后到達存儲引擎。
那么,一條 SQL 更新語句的執行流程又是怎樣的呢?
首先我們創建一個表 user_info,主鍵為 id,創建語句如下:
CREATE TABLE `T` ( `ID` int(11) NOT NULL, `c` int(11) DEFAULT NULL, PRIMARY KEY (`ID`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
插入一條數據:
INSERT INTO T VALUES ('2', '1');
如果要將 ID=2 這一行的 c 的值加 1,SQL 語句為:
UPDATE T SET c = c + 1 WHERE ID = 2;
前面介紹過 SQL 語句基本的執行鏈路,這里把那張圖拿過來。因為,更新語句同樣會走一遍查詢語句走的流程。
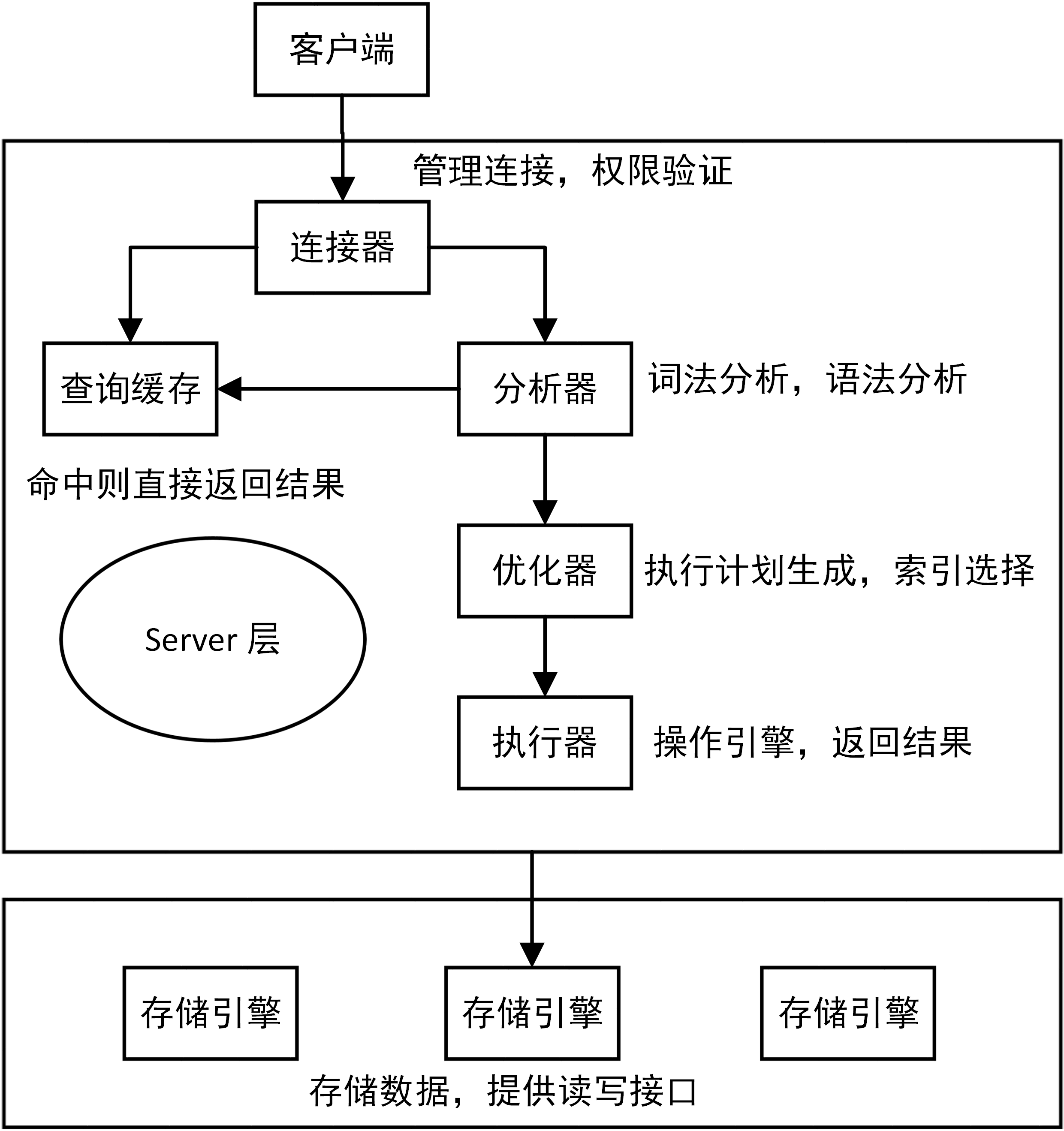
通過連接器,客戶端與 MySQL 建立連接
update 語句會把 T 表上的所有查詢緩存結果清空
分析器會通過詞法分析和語法分析識別這是一條更新語句
優化器會決定使用 ID 這個索引(聚簇索引)
執行器負責具體執行,找到匹配的一行,然后更新
更新過程中還會涉及 redo log(重做日志)和 binlog(歸檔日志)的操作
其中,這兩種日志默認在數據庫的 data 目錄下,redo log 是 ib_logfile0 格式的,binlog 是 xxx-bin.000001 格式的。
接下來讓我們分別去研究下日志模塊中的 redo log 和 binlog。
在 MySQL 中,如果每一次的更新操作都需要寫進磁盤,然后磁盤也要找到對應的那條記錄,然后再更新,整個過程 IO 成本、查找成本都很高。為了解決這個問題,MySQL 的設計者就采用了日志(redo log)來提升更新效率。
而日志和磁盤配合的整個過程,其實就是 MySQL 里的 WAL 技術,WAL 的全稱是 Write-Ahead Logging,它的關鍵點就是先寫日志,再寫磁盤。
具體來說,當有一條記錄需要更新的時候,InnoDB 引擎就會先把記錄寫到 redo log(redolog buffer)里面,并更新內存(buffer pool),這個時候更新就算完成了。同時,InnoDB 引擎會在適當的時候(如系統空閑時),將這個操作記錄更新到磁盤里面(刷臟頁)。
redo log 是 InnoDB 存儲引擎層的日志,又稱重做日志文件,redo log 是循環寫的,redo log 不是記錄數據頁更新之后的狀態,而是記錄這個頁做了什么改動。
redo log 是固定大小的,比如可以配置為一組 4 個文件,每個文件的大小是 1GB,那么日志總共就可以記錄 4GB 的操作。從頭開始寫,寫到末尾就又回到開頭循環寫,如下圖所示。
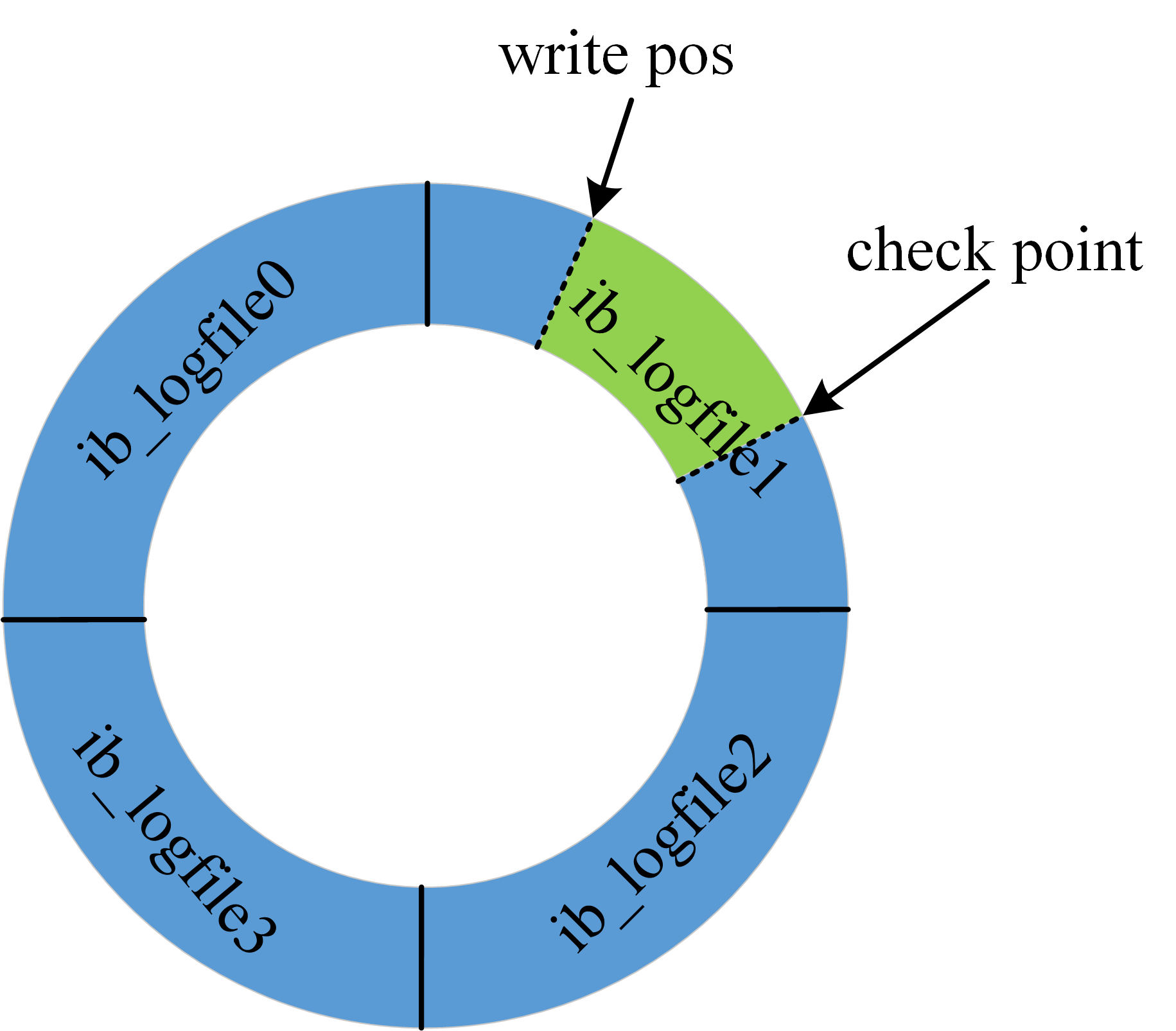
圖中展示了一組 4 個文件的 redo log 日志,checkpoint 是當前要擦除的位置,擦除記錄前需要先把對應的數據落盤(更新內存頁,等待刷臟頁)。write pos 到 checkpoint 之間的部分可以用來記錄新的操作,如果 write pos 和 checkpoint 相遇,說明 redolog 已滿,這個時候數據庫停止進行數據庫更新語句的執行,轉而進行 redo log 日志同步到磁盤中。checkpoint 到 write pos 之間的部分等待落盤(先更新內存頁,然后等待刷臟頁)。
有了 redo log 日志,那么在數據庫進行異常重啟的時候,可以根據 redo log 日志進行恢復,也就達到了 crash-safe。
redo log 用于保證 crash-safe 能力。innodb_flush_log_at_trx_commit 這個參數設置成 1 的時候,表示每次事務的 redo log 都直接持久化到磁盤。這個參數建議設置成 1,這樣可以保證 MySQL 異常重啟之后數據不丟失。
MySQL 整體來看,其實就有兩塊:一塊是 Server 層,它主要做的是 MySQL 功能層面的事情;還有一塊是引擎層,負責存儲相關的具體事宜。redo log 是 InnoDB 引擎特有的日志,而 Server 層也有自己的日志,稱為 binlog(歸檔日志)。
binlog 屬于邏輯日志,是以二進制的形式記錄的是這個語句的原始邏輯,依靠 binlog 是沒有 crash-safe 能力的。
binlog 有兩種模式,statement 格式的話是記 sql 語句,row 格式會記錄行的內容,記兩條,更新前和更新后都有。
sync_binlog 這個參數設置成 1 的時候,表示每次事務的 binlog 都持久化到磁盤。這個參數也建議設置成 1,這樣可以保證 MySQL 異常重啟之后 binlog 不丟失。
為什么會有兩份日志呢?
因為最開始 MySQL 里并沒有 InnoDB 引擎。MySQL 自帶的引擎是 MyISAM,但是 MyISAM 沒有 crash-safe 的能力,binlog 日志只能用于歸檔。而 InnoDB 是另一個公司以插件形式引入 MySQL 的,既然只依靠 binlog 是沒有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系統——也就是 redo log 來實現 crash-safe 能力。
redo log 和 binlog 區別:
redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 層實現的,所有引擎都可以使用。
redo log 是物理日志,記錄的是在某個數據頁上做了什么修改;binlog 是邏輯日志,記錄的是這個語句的原始邏輯。
redo log 是循環寫的,空間固定會用完;binlog 是可以追加寫入的。追加寫是指 binlog 文件寫到一定大小后會切換到下一個,并不會覆蓋以前的日志。
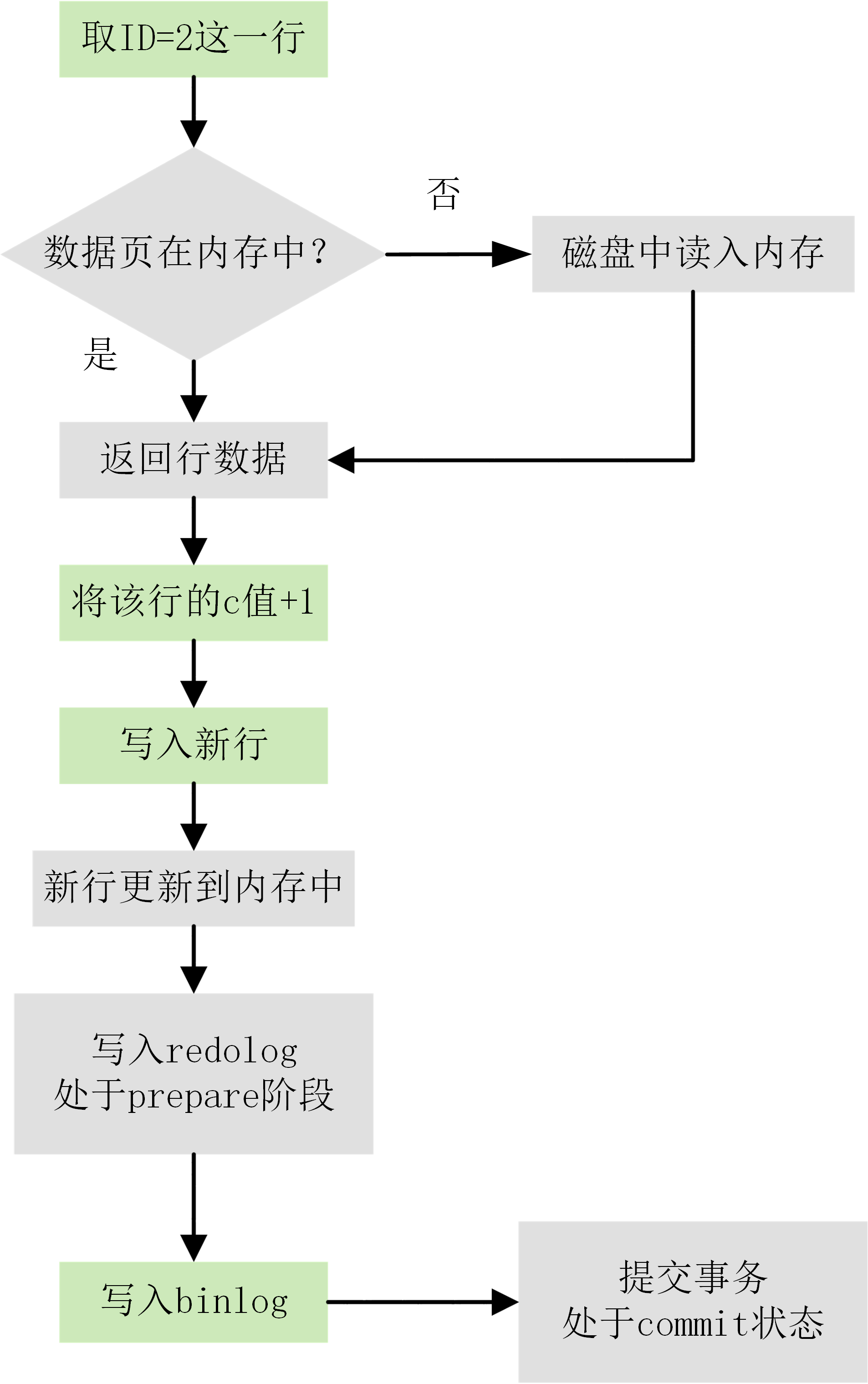
有了對這兩個日志的概念性理解后,再來看執行器和 InnoDB 引擎在執行這個 update 語句時的內部流程。
執行器先找引擎取 ID=2 這一行。ID 是主鍵,引擎直接用樹搜索找到這一行。如果 ID=2 這一行所在的數據頁本來就在內存中,就直接返回給執行器;否則,需要先從磁盤讀入內存,然后再返回。
執行器拿到引擎給的行數據,把這個值加上 1,比如原來是 N,現在就是 N+1,得到新的一行數據,再調用引擎接口寫入這行新數據。
引擎將這行新數據更新到內存(InnoDB Buffer Pool)中,同時將這個更新操作記錄到 redo log 里面,此時 redo log 處于 prepare 狀態。然后告知執行器執行完成了,隨時可以提交事務。
執行器生成這個操作的 binlog,并把 binlog 寫入磁盤。
執行器調用引擎的提交事務接口,引擎把剛剛寫入的 redo log 改成提交(commit)狀態,更新完成。
下圖為 update 語句的執行流程圖,圖中灰色框表示是在 InnoDB 內部執行的,綠色框表示是在執行器中執行的。
其中將 redo log 的寫入拆成了兩個步驟:prepare 和 commit,這就是兩階段提交(2PC)。
MySQL 使用兩階段提交主要解決 binlog 和 redo log 的數據一致性的問題。
redo log 和 binlog 都可以用于表示事務的提交狀態,而兩階段提交就是讓這兩個狀態保持邏輯上的一致。下圖為 MySQL 二階段提交簡圖:
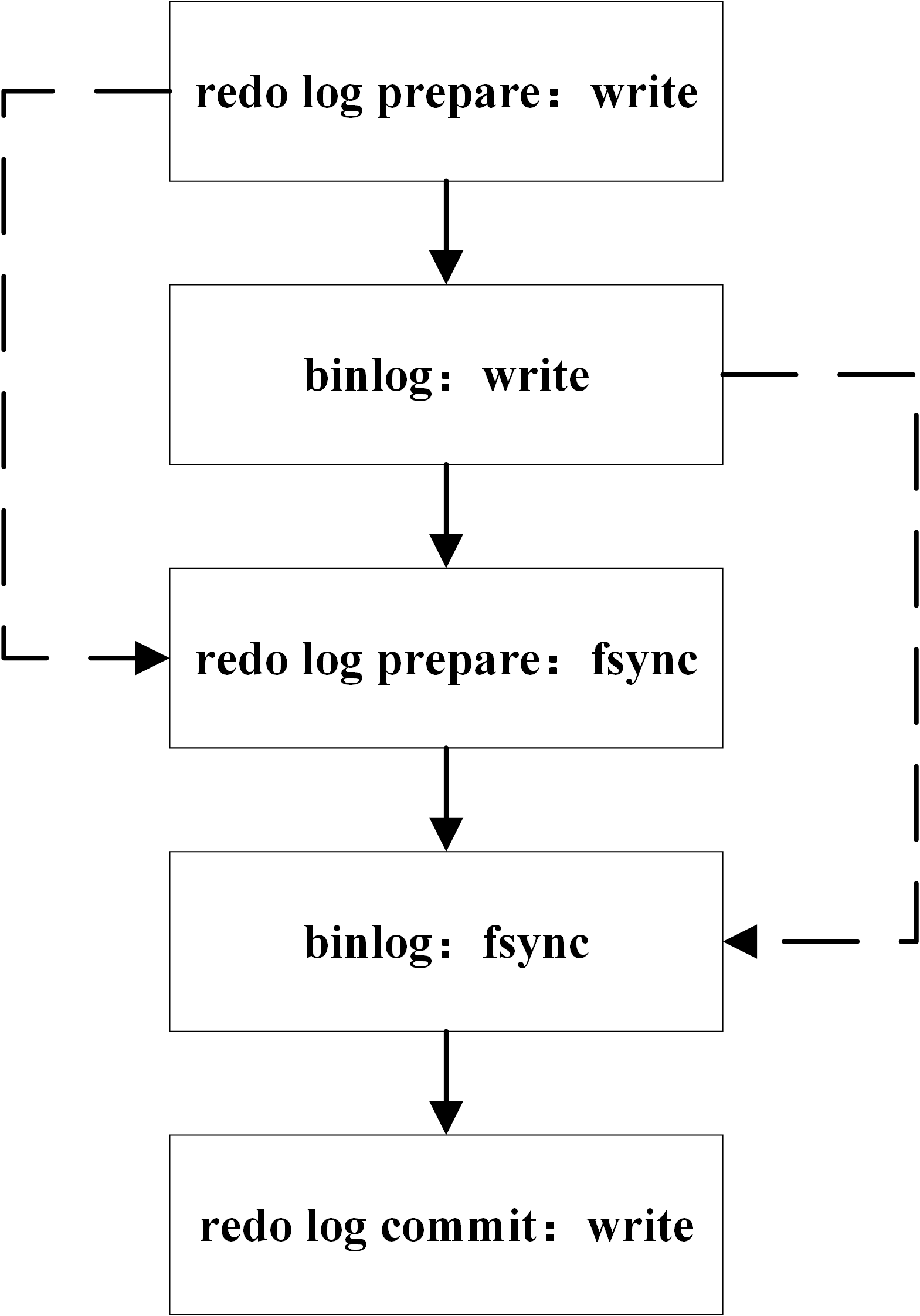
兩階段提交原理描述:
InnoDB redo log 寫盤,InnoDB 事務進入 prepare 狀態。
如果前面 prepare 成功,binlog 寫盤,那么再繼續將事務日志持久化到 binlog,如果持久化成功,那么 InnoDB 事務則進入 commit 狀態(在 redo log 里面寫一個 commit 記錄)
備注: 每個事務 binlog 的末尾,會記錄一個 XID event,標志著事務是否提交成功,也就是說,recovery 過程中,binlog 最后一個 XID event 之后的內容都應該被 purge。
binlog 會記錄所有的邏輯操作,并且是采用追加寫的形式。當需要恢復到指定的某一秒時,比如今天下午二點發現中午十二點有一次誤刪表,需要找回數據,那你可以這么做:
首先,找到最近的一次全量備份,從這個備份恢復到臨時庫
然后,從備份的時間點開始,將備份的 binlog 依次取出來,重放到中午誤刪表之前的那個時刻。
這樣你的臨時庫就跟誤刪之前的線上庫一樣了,然后你可以把表數據從臨時庫取出來,按需要恢復到線上庫去。
redo log 和 binlog 有一個共同的數據字段,叫 XID。崩潰恢復的時候,會按順序掃描 redo log:
如果碰到既有 prepare、又有 commit 的 redo log,就直接提交;
如果碰到只有 parepare、而沒有 commit 的 redo log,就拿著 XID 去 binlog 找對應的事務。
一個事務的 binlog 是有完整格式的:
statement 格式的 binlog,最后會有 COMMIT
row 格式的 binlog,最后會有一個 XID event
在 MySQL 5.6.2 版本以后,還引入了 binlog-checksum 參數,用來驗證 binlog 內容的正確性。對于 binlog 日志由于磁盤原因,可能會在日志中間出錯的情況,MySQL 可以通過校驗 checksum 的結果來發現。所以,MySQL 是有辦法驗證事務 binlog 的完整性的。
redo log 太小的話,會導致很快就被寫滿,然后不得不強行刷 redo log,這樣 WAL 機制的能力就發揮不出來了。
如果是幾個 TB 的磁盤的話,直接將 redo log 設置為 4 個文件,每個文件 1GB。
實際上,redo log 并沒有記錄數據頁的完整數據,所以它并沒有能力自己去更新磁盤數據頁,也就不存在由 redo log 更新過去數據最終落盤的情況。
數據頁被修改以后,跟磁盤的數據頁不一致,稱為臟頁。最終數據落盤,就是把內存中的數據頁寫盤。這個過程與 redo log 毫無關系。
在崩潰恢復場景中,InnoDB 如果判斷到一個數據頁可能在崩潰恢復的時候丟失了更新,就會將它讀到內存,然后讓 redo log 更新內存內容。更新完成后,內存頁變成臟頁,就回到了第一種情況的狀態。
在一個事務的更新過程中,日志是要寫多次的。比如下面這個事務:
begin;
INSERT INTO T1 VALUES ('1', '1');
INSERT INTO T2 VALUES ('1', '1');
commit;這個事務要往兩個表中插入記錄,插入數據的過程中,生成的日志都得先保存起來,但又不能在還沒 commit 的時候就直接寫到 redo log 文件里。
因此就需要 redo log buffer 出場了,它就是一塊內存,用來先存 redo 日志的。也就是說,在執行第一個 insert 的時候,數據的內存被修改了,redo log buffer 也寫入了日志。
但是,真正把日志寫到 redo log 文件,是在執行 commit 語句的時候做的。
以下是我截取的部分 redo log buffer 的源代碼:
/** redo log buffer */
struct log_t{
char pad1[CACHE_LINE_SIZE];
lsn_t lsn;
ulint buf_free; // buffer 內剩余空間的起始點的 offset
#ifndef UNIV_HOTBACKUP
char pad2[CACHE_LINE_SIZE];
LogSysMutex mutex;
LogSysMutex write_mutex;
char pad3[CACHE_LINE_SIZE];
FlushOrderMutex log_flush_order_mutex;
#endif /* !UNIV_HOTBACKUP */
byte* buf_ptr; // 隱性的 buffer
byte* buf; // 真正操作的 buffer
bool first_in_use;
ulint buf_size; // buffer大小
bool check_flush_or_checkpoint;
UT_LIST_BASE_NODE_T(log_group_t) log_groups;
#ifndef UNIV_HOTBACKUP
/** The fields involved in the log buffer flush @{ */
ulint buf_next_to_write;
volatile bool is_extending;
lsn_t write_lsn; /*!< last written lsn */
lsn_t current_flush_lsn;
lsn_t flushed_to_disk_lsn;
ulint n_pending_flushes;
os_event_t flush_event;
ulint n_log_ios;
ulint n_log_ios_old;
time_t last_printout_time;
/** Fields involved in checkpoints @{ */
lsn_t log_group_capacity;
lsn_t max_modified_age_async;
lsn_t max_modified_age_sync;
lsn_t max_checkpoint_age_async;
lsn_t max_checkpoint_age;
ib_uint64_t next_checkpoint_no;
lsn_t last_checkpoint_lsn;
lsn_t next_checkpoint_lsn;
mtr_buf_t* append_on_checkpoint;
ulint n_pending_checkpoint_writes;
rw_lock_t checkpoint_lock;
#endif /* !UNIV_HOTBACKUP */
byte* checkpoint_buf_ptr;
byte* checkpoint_buf;
/* @} */
};redo log buffer 本質上只是一個 byte 數組,但是為了維護這個 buffer 還需要設置很多其他的 meta data,這些 meta data 全部封裝在 log_t 結構體中。
這篇文章主要介紹了 MySQL 里面最重要的兩個日志,即物理日志 redo log(重做日志)和邏輯日志 binlog(歸檔日志),還講解了有與日志相關的一些問題。
另外還介紹了與 MySQL 日志系統密切相關的兩階段提交(2PC),兩階段提交是解決分布式系統的一致性問題常用的一個方案,類似的還有 三階段提交(3PC) 和 PAXOS 算法。
看完上述內容,你們掌握MySQL 日志系統中的redolog和binlog的用法的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





