溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Kafka如何進行跨AZ部署最佳實踐,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
跨AZ部署是實現服務高可用較為有效的方法,同時也極具性價比。如果實現了跨AZ部署,不僅可以消除服務中的單點,同時還可以逐步建設如下能力:服務隔離,灰度發布,N+1冗余,可謂一舉多得。上一篇介紹了ES的跨AZ部署實踐,本文繼續介紹Kafka如何實現跨AZ部署。
“broker.rack”是服務端Broker配置文件中的一個參數,類似于ES中的Rack或Zone,通過Tag的方式,將集群中的Broker進行“分組”,在分配分區副本時實現跨Rack容錯。此參數接受一個“string”類型的值,默認為null;此外“broker.rack”不支持動態更新,是只讀的,這意味著:
更新Broker的broker.rack 需要重啟broker;
跨AZ部署的集群,擴縮容不需要對集群其他Broker進行重啟
生產環境的Kafka集群若要增加此配置實現跨AZ部署,需要對集群所有Broker進行重啟。
具體配置示例如下:
broker.rack=my-rack-id
當創建Topic時會受到broker.rack參數的約束,以確保分區副本能夠盡可能多的跨Rack,即n = min(#racks, replication-factor),n指的是分區的副本將會分布在n個Rack。
那什么是盡可能呢?
這個是基于Kafka分區分配算法,具體實現可參考源碼中的函數(assignReplicasToBrokers)。
這里要說的是,Kafka在為Topic分配分區時會根據如下幾個參數:replication-factor,partitions,兩個隨機參數(startIndex,fixedStartIndex),各Broker上分區數量以及broker.rack將所有可用的Broker ID生成一個有序列表,列表會按照輪詢broker.rack的Broker產生的。假設:
rack1: 0 1 rack2: 2 3
則生成的列表會變成:[0, 2, 1, 3]。在分片分區時,當Broker滿足如下兩個條件中的任意一個,副本將不會分配到該節點:
此Broker所在的broker.rack已經存在該分區的副本,且存在broker.rack中沒有該分區副本。
此Broker中已經存在該分區副本,并且還有其他Broker中沒有該分區的副本。
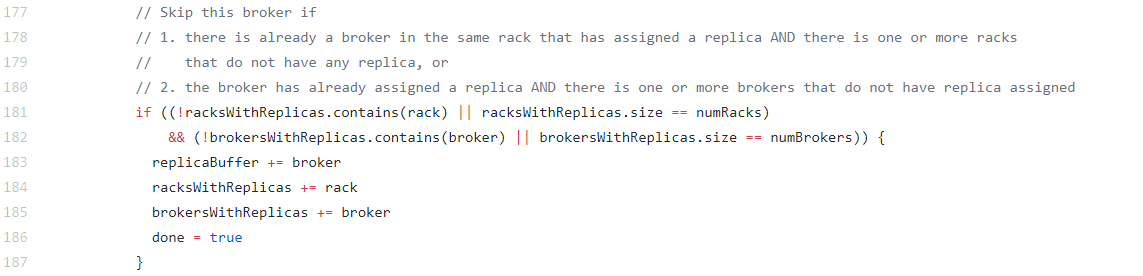
圖1 broker.rack參數分配機制部分源碼
通過上文的解釋,大家應該對Kafka的副本分配機制有所了解,總的來說:
當replication-factor<#broker.rack時,Topic的所有分區會優先覆蓋到所有的broke.rack;
當replication-factor=#broker.rack時,每個broke.rack將存在一套完整的分區副本;
當replication-factor>#broker.rack時,至少一個broke.rack存在一套完整的分區副本;
特別的,當replication-factor=2#broker.rack時,Topic的分區會均勻分配在兩個AZ。
還有值得注意的是:
Kafka在進行Leader選舉或Leader重平衡時,不關注broker.rack,即默認情況下,Leader會分布在多個AZ。
Kafka不像ES,它不具備副本自動轉移broker恢復的能力
那么,如何在一個AZ內部,實現broker的高可用部署呢?本身維護真正意義上的機架分布難度很大,加上在虛擬化場景下,機架和虛擬機/docker中間還存在宿主機層,維護成本更高,所以建議使用云廠商提供的高可用組/置放群組來實現。
梳理上文中提到影響影響分區分配的因素,排除兩個隨機參數(影響的僅僅是broker list的起始ID)和Broker上分區數量情況(這個參數影響的是AZ內部的再平衡,本文的場景驗證不關心AZ內部的分區分配情況)。
每個AZ的broker數量是否一致,也僅僅影響到的是AZ內部的分區情況,為了簡化驗證場景,我們暫不考慮每個AZ broker不一致的情況,所有可用的Broker ID 這個參數可以簡化為“單AZ broker數量”這個參數代替。
剩余幾個因素和需要驗證的值如下表所示:
表1 參數列表
參數 | 驗證值 | 備注 |
Topic分區數 | 1,2,3 | 考慮1個分區和奇偶分區的場景 |
Topic副本數 | 1,2,3 | 考慮1副本和奇偶副本數的場景 |
集群AZ數量 | 1,2,3 | 考慮1個AZ(沒有AZ)和奇偶AZ的場景 |
單AZ broker數量 | 1,2,3 | 考慮分區數或副本數小于,等于,大于單AZ的broker的各種場景 |
要窮盡上表中的各種組合,共需要驗證3*3*3*3=81種場景,為了排除偶然因素的影響,每種場景還需要重復多次試驗,這樣做會非常繁瑣、且效率不高。
我們可以將參數看作“因素”,驗證值看“水平”,每個因素取什么值是與其他因素無關。這正可以采用“正交試驗”的思路(根據正交性從全面試驗中挑選出部分有代表性的點進行試驗,是一種高效率、快速、經濟的實驗設計方法)。驗證上表中的場景剛好可以用最常用的L9(3^4)型正交表(3水平4因素一般都用此表),共需要驗證9種場景即可,每種場景進行10次驗證,以排查偶然因素。
實際上只需驗證7種場景即可,因為其中兩種場景不符合Kafka創建Topic的要求。通過Kafka Manager的可視化界面清晰的看到分區副本的分布情況,類似這樣的:
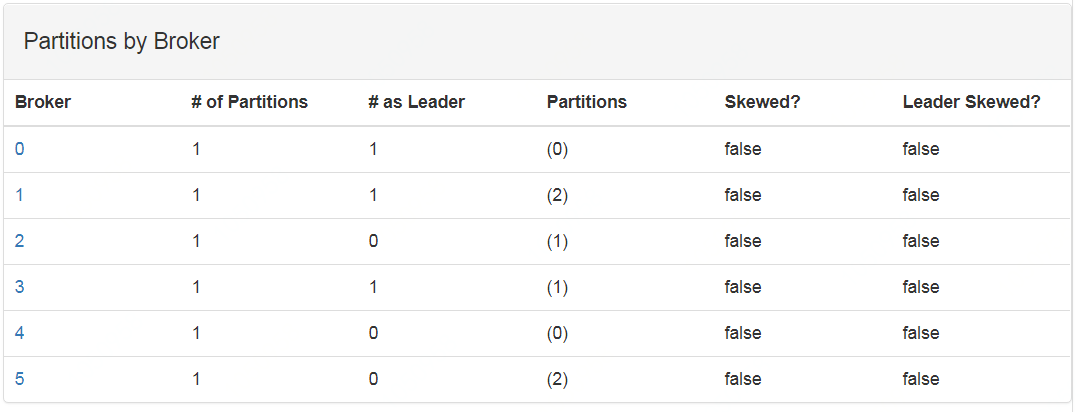
圖2 三分區兩副本2AZ時的分布情況,其中 broker id為0,1,2一個AZ,3,4,5一個AZ
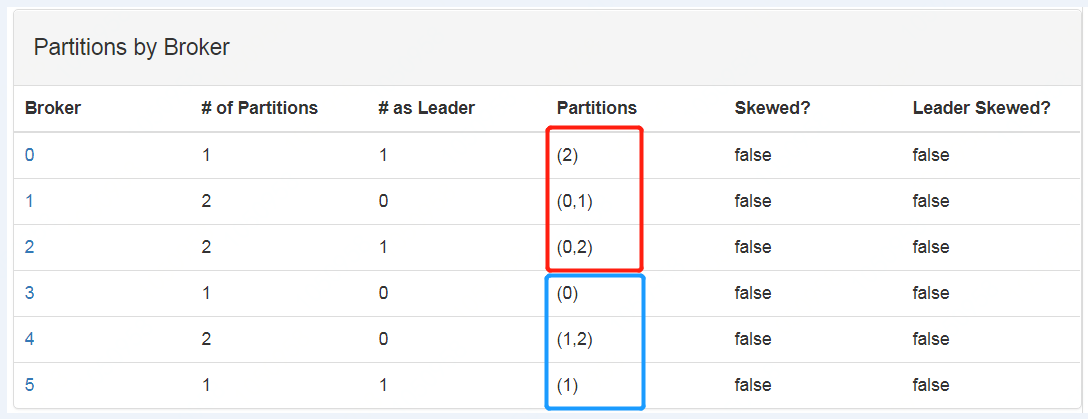
圖3 三分區三副本2AZ時的分布情況,其中 broker id為0,1,2一個AZ,3,4,5一個AZ
采用L9(34)型的正交表,場景以及結論如下:
表2 正交場景表
場景 | 分區數 | 副本數 | AZ數量 | 單AZ broker數量 | 分區分布 | Leader分布 | 備注 |
1 | 1 | 1 | 1 | 1 | 每個AZ具備一套分區 | 一個AZ | replication-factor=#broker.rack |
2 | 1 | 2 | 2 | 2 | 每個AZ具備一套分區 | 兩個AZ隨機 | replication-factor=#broker.rack |
3 | 1 | 3 | 3 | 3 | 每個AZ具備一套分區 | 兩個AZ隨機 | replication-factor=#broker.rack |
4 | 2 | 1 | 2 | 3 | 2個AZ共有一套分區 | 兩個AZ隨機 | replication-factor<#broker.rack |
5 | 2 | 2 | 3 | 1 | 一個AZ具備一套分區,其他分區共有一套分區 | 三個AZ隨機 | replication-factor<#broker.rack |
6 | 2 | 3 | 1 | 2 | -- | -- | 副本數>分區數無法創建 |
7 | 3 | 1 | 3 | 2 | 3個AZ共有一套分區 | 三個AZ隨機 | replication-factor<#broker.rack |
8 | 3 | 2 | 1 | 3 | 每個AZ具備兩套分區 |
| replication-factor>#broker.rack |
9 | 3 | 3 | 2 | 1 | -- | -- | 副本數>分區數無法創建 |
可見,跨AZ部署的集群,若采取4副本可以做到AZ內部以及跨AZ數據備份的能力。若一個AZ主要是為了容災的話,可以通過Kafka的API(kafka-reassign-partitions.sh)將所有的Leader集中在一個AZ,從而降低跨AZ寫數據的延遲。不過,一般的,AZ之間的延遲往往很低是可接受的。
多AZ的部署架構,主要是硬件成本,而考慮成本,需要結合數據重要性。若數據重要性較高,四副本的Topic配置是需要的,并且Kafka作為消息隊列,Messages的存儲本身并不重要,所以成本的影響不大。
第二個問題就是網路延遲,我們通過壓測來驗證網絡延遲會對Kafka帶來什么。在可用區A和可用區B創建一套集群:
基準集群為:在華北可用區A部署的2臺機器組成的集群
跨AZ集群為在華北可用區A和可用區B部署的2臺機器組成的集群
兩個AZ直接的ping延遲和AZ內部的ping延遲均值分別為:0.070ms和1.171ms。從三個角度驗證網絡延遲的影響。
生產者向Kafka集群發送消息,又可分為同步(acks=all)和異步(acks=1)兩種方式,我們采用kafka自帶的壓測工具(/kafka-producer-perf-test.sh)對兩個集群進行壓測。
在上述兩個集群各創建一個topic(--replication-factor 2 --partitions 1,leader位于可用區A上)
壓測機位于華北可用區A,每條消息的大小為300字節(為了體現網絡的問題,弱化自身處理每條消息的能力),每秒發送10000條數據。
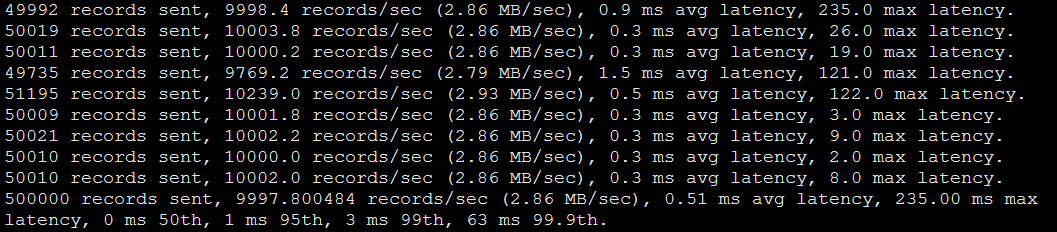
當消息生產者已異步方式寫入時,即acks=1時,兩個集群的平均延遲幾乎沒有差別,壓測結果兩者分別是0.42 ms avg latency和0.51 ms avg latency。
壓測參數:
./kafka-producer-perf-test.sh --topic pressure1 --num-records 500000 --record-size 300 \ --throughput 10000 --producer-props bootstrap.servers=10.160.109.68:9092
基準集群壓測結果:
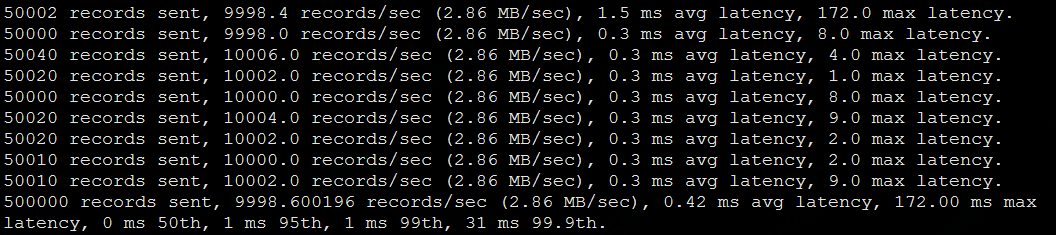
跨AZ集群壓測結果:
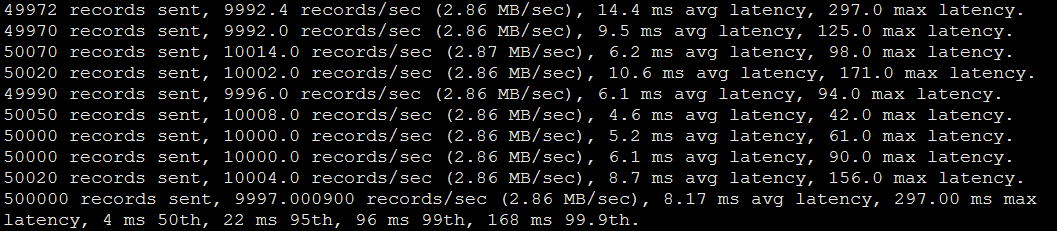
當消息采用同步機制時,消息的寫入有影響。影響還是有些大的,基準集群為1.09 ms avg latency,跨AZ集群為8.17 ms avg latency:
壓測參數:
./kafka-producer-perf-test.sh --topic pressure --num-records 500000 --record-size 300 \ --throughput 10000 --producer-props acks=all bootstrap.servers=10.160.109.68:9092
基準集群壓測結果:
下表是對比了當消息大小為10,50…300時,同步寫時的平均延遲,發現,跨AZ集群/基準集群大概能保持7倍的延遲差。

表4 步寫入時的數據對比
消息體大小 | 10 | 50 | 100 | 150 | 200 | 300 |
基準-平均延遲/ms | 0.91 | 0.83 | 0.65 | 0.75 | 0.72 | 1.09 |
跨AZ-平均延遲/ms | 5.39 | 4.48 | 5.23 | 5.23 | 5.14 | 8.17 |
比值(跨AZ/基準) | 5.92 | 5.40 | 8.05 | 6.97 | 7.14 | 7.50 |
選擇消息體大小為1000字節充分驗證跨AZ場景下,網絡傳輸對集群數據同步的影響。對于基準集群,我們將一臺Broker停掉,使用壓測工具異步寫入5000000條數據,然后啟動停掉的Broker,獲得副本分區與leader完成同步的時間;同樣的,對跨AZ集群,停掉可用區B 中的Broker,也向leader寫入同樣的數據,獲得副本分區與leader完成同步的時間,并對兩者進行比較。
基準集群在26s完成了副本同步:

跨AZ集群在142s完成了副本同步,而且在同步期間,出現了與ZK連接超時的WARN。

可見,跨AZ集群在ping延遲下,對于消息體較大時,會出現一些潛在的問題。
消費的延遲也主要集中在跨AZ的距離上,不過是可解的,消費者組支持如下參數:
client.rack #此參數接受一個string類型的值, 并與broker.rack的值保持一致。
當你的集群已經運行在生產環境上了,現在需要升級為跨AZ部署,那么應該如何對現有集群進行配置升級呢?
當集群中存在有brocker.rack參數為null的節點時,哪怕只有一臺機器,默認參數下創建topic會失敗,會出現如下報錯:

通過參數--disable-rack-aware 可以忽略broker.rack參數進行分區分配。生產環境的升級需要修改創建topic的方式,升級過程中對數據寫入和消費沒有影響(對已經存在的topic,Kafka也不會自動的將分區重平衡)。
生產環境跨AZ升級的一般步驟如下:
跨AZ創建測試集群,充分驗證跨AZ對集群的影響,需要關注寫入吞吐量的影響(Topic是否需要增加分區),集群自身數據同步的資源消耗和消費的跨AZ延遲情況;
制定充分的回滾預案,并進行回滾演練;
增加“broker.rack”參數,在新的可用區對集群進行擴容;
對集群原有節點,增加“broker.rack”參數,并需要滾動重所有節點;
在Topic級別,通過手動指定副本分配,在合適的時間對Topic進行分區分配;
按照需求,啟動Topic的Leader重分配。
Kafka的跨AZ部署的前提是需要有跨AZ部署的Zookeeper,不然當ZK集群所在的AZ故障,Kafka集群也將不可用;
對正在使用的Kafka集群進行跨AZ部署,當集群規模較大時,滾動重啟集群操作時間跨度會很長,并且需要人工對所有的Topic進行分區遷移,若集群中Topic很多,此操作的工作量會很大;
生產環境的跨AZ升級需要充分的驗證,對生產環境消息體的大小進行統計,特別的需要關注消息體大小大于80分位數,90分位數和95分位數下的數據同步對集群造成的延遲影響,以免在高并發寫入時拖垮集群。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





