溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Redis跳躍表的結構實現方法”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Redis跳躍表的結構實現方法”吧!
Redis 提供了5種數據類型:String(字符串)、Hash(哈希)、List(列表)、Set(集合)、Zset(有序集合),理解每種數據類型的特點對于redis的開發和運維非常重要。
原文解析:http://www.yund.tech/zdetail.html?type=1&id=e4802958843feef901c7d7b7932f8be0"
備注: 按照分析順序,本節應該說道有序集合對象了,但是考慮到有序集合對象的底層實現中使用到了跳躍表結構,避免在分析有序集合時造成突兀,所以本節先來看看 redis 中跳躍表結構的具體實現。
?Redis 的跳躍表由 redis.h/zskiplistNode 和 redis.h/zskiplist 兩個結構定義,其中 zskiplistNode 結構用于表示跳躍表節點,而 zskiplist 結構則用于保存跳躍表節點的相關信息,比如節點的數量,以及指向表頭節點和表尾節點的指針等。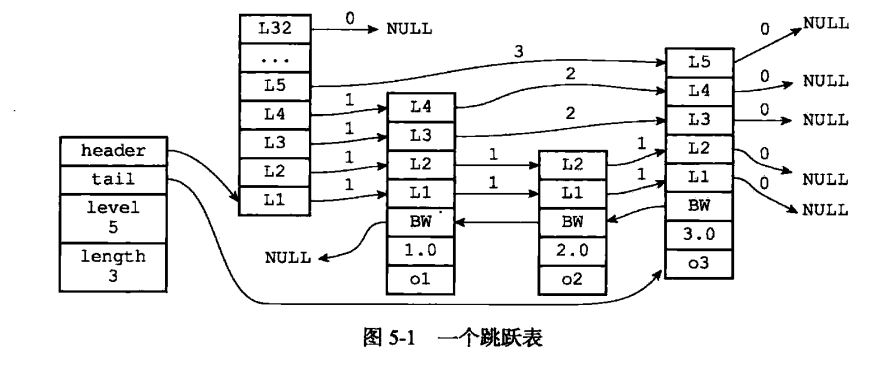
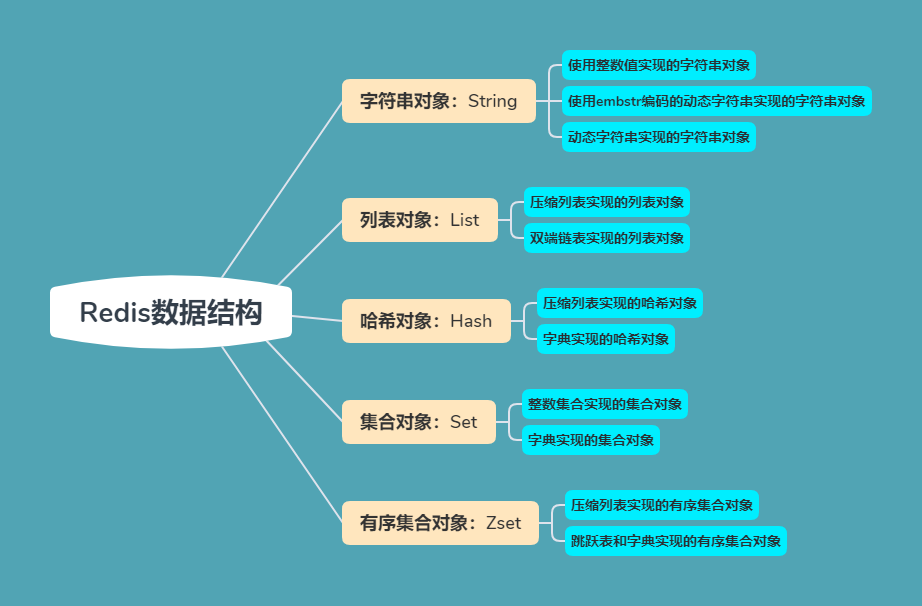
?圖 5-1 展示了一個跳躍表示例, 位于圖片最左邊的是 zskiplist 結構, 該結構包含以下屬性:
header :指向跳躍表的表頭節點。 tail :指向跳躍表的表尾節點。 level :記錄目前跳躍表內,層數最大的那個節點的層數(表頭節點的層數不計算在內)。 length :記錄跳躍表的長度,也即是,跳躍表目前包含節點的數量(表頭節點不計算在內)。
?zskiplist 結構右邊的是四個 zskiplistNode 結構, 該結構包含以下屬性:
層(level):節點中用 L1 、 L2 、 L3 等字樣標記節點的各個層, L1 代表第一層, L2 代表第二層,以此類推。每個層都帶有兩個屬性:前進指針和跨度。前進指針用于訪問位于表尾方向的其他節點,而跨度則記錄了前進指針所指向節點和當前節點的距離。在上面的圖片中,連線上帶有數字的箭頭就代表>前進指針,而那個數字就是跨度。當程序從表頭向表尾進行遍歷時,訪問會沿著層的前進指針進行。
后退指針(backward):節點中用 BW 字樣標記節點的后退指針,它指向位于當前節點的前一個節點。后退指針在程序從表尾向表頭遍歷時使用。
分值(score):各個節點中的 1.0 、 2.0 和 3.0 是節點所保存的分值。在跳躍表中,節點按各自所保存的分值從小到大排列。
成員對象(obj):各個節點中的 o1 、 o2 和 o3 是節點所保存的成員對象。 注意表頭節點和其他節點的構造是一樣的: 表頭節點也有后退指針、分值和成員對象, 不過表頭節點的這些屬性都不會被用到, 所以圖中省略了這些部分, 只顯示了表頭節點的各個層。
跳躍表節點實現由 redis.h/zskiplistNode 結構定義:
typedef struct zskiplistNode {
// 后退指針
struct zskiplistNode *backward;
// 分值
double score;
// 成員對象
robj *obj;
// 層
struct zskiplistLevel {
// 前進指針
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;跳躍表節點的 level 數組可以包含多個元素, 每個元素都包含一個指向其他節點的指針,程序可以通過這些層來加快訪問其他節點的速度,一般來說, 層的數量越多,訪問其他節點的速度就越快。
每次創建一個新跳躍表節點的時候,程序都根據冪次定律(power law,越大的數出現的概率越小)隨機生成一個介于 1 和 32 之間的值作為 level 數組的大小, 這個大小就是層的“高度”。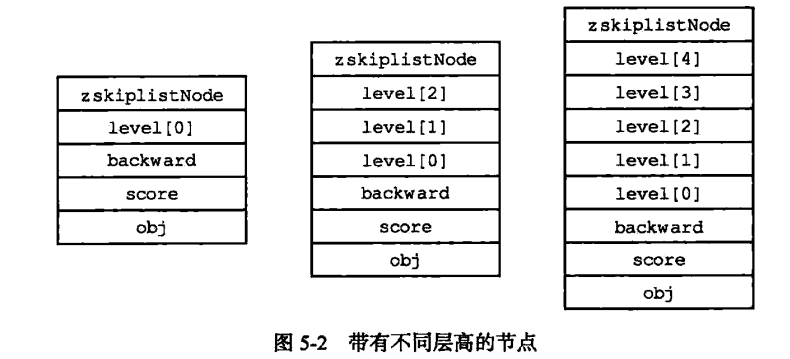
圖 5-2 分別展示了三個高度為 1 層、3 層和 5 層的節點,因為 C 語言的數組索引總是從 0 開始的, 所以節點的第一層是 level[0] ,而第二層是 level[1] ,以此類推。
每個層都有一個指向表尾方向的前進指針(level[i].forward 屬性),用于從表頭向表尾方向訪問節點。
圖 5-3 用虛線表示出了程序從表頭向表尾方向,遍歷跳躍表中所有節點的路徑:
迭代程序首先訪問跳躍表的第一個節點(表頭), 然后從第四層的前進指針移動到表中的第二個節點。 在第二個節點時, 程序沿著第二層的前進指針移動到表中的第三個節點。 在第三個節點時, 程序同樣沿著第二層的前進指針移動到表中的第四個節點。 當程序再次沿著第四個節點的前進指針移動時, 它碰到一個NULL,程序知道這時已經到達了跳躍表的表尾, 于是結束這次遍歷。
層的跨度(level[i].span 屬性)用于記錄兩個節點之間的距離:
兩個節點之間的跨度越大, 它們相距得就越遠。 指向 NULL 的所有前進指針的跨度都為 0 , 因為它們沒有連向任何節點。 初看上去, 很容易以為跨度和遍歷操作有關,但實際上并不是這樣,遍歷操作只使用前進指針就可以完成了,跨度實際上是用來計算排位(rank)的:在查找某個節點的過程中,將沿途訪問過的所有層的跨度累計起來,得到的結果就是目標節點在跳躍表中的排位。
例如, 圖 5-4 用虛線標記了在跳躍表中查找分值為 3.0 、 成員對象為 o3 的節點時, 沿途經歷的層: 查找的過程只經過了一個層, 并且層的跨度為 3 , 所以目標節點在跳躍表中的排位為 3 。
例如, 圖 5-5 用虛線標記了在跳躍表中查找分值為 2.0 、 成員對象為 o2 的節點時, 沿途經歷的層: 在查找節點的過程中, 程序經過了兩個跨度為 1 的節點, 因此可以計算出, 目標節點在跳躍表中的排位為 2 。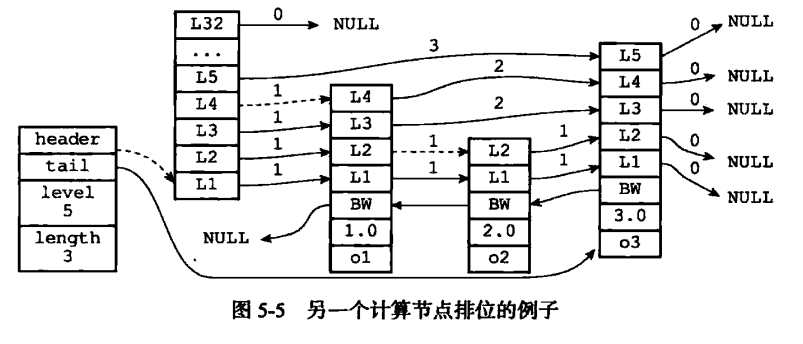
節點的后退指針(backward 屬性)用于從表尾向表頭方向訪問節點: 跟可以一次跳過多個節點的前進指針不同, 因為每個節點只有一個后退指針, 所以每次只能后退至前一個節點。 圖 5-6 用虛線展示了如果從表尾向表頭遍歷跳躍表中的所有節點:程序首先通過跳躍表的 tail 指針訪問表尾節點,然后通過后退指針訪問倒數第二個節點,之后再沿著后退指針訪問倒數第三個節點,再之后遇到指向 NULL 的后退指針,于是訪問結束。
圖 5-6 用虛線展示了如果從表尾向表頭遍歷跳躍表中的所有節點:程序首先通過跳躍表的 tail 指針訪問表尾節點,然后通過后退指針訪問倒數第二個節點,之后再沿著后退指針訪問倒數第三個節點,再之后遇到指向 NULL 的后退指針,于是訪問結束。
節點的分值(score 屬性)是一個 double 類型的浮點數, 跳躍表中的所有節點都按分值從小到大來排序。
節點的成員對象(obj 屬性)是一個指針, 它指向一個字符串對象, 而字符串對象則保存著一個 SDS (簡單動態字符串,前面分析過)值。
在同一個跳躍表中,各個節點保存的成員對象必須是唯一的,但是多個節點保存的分值卻可以是相同的:分值相同的節點將按照成員對象在字典序中的大小來進行排序,成員對象較小的節點會排在前面(靠近表頭的方向),而成員對象較大的節點則會排在后面(靠近表尾的方向)。
例如, 在圖 5-7 所示的跳躍表中, 三個跳躍表節點都保存了相同的分值 10086.0 , 但保存成員對象 o1 的節點卻排在保存成員對象 o2和 o3 的節點之前, 而保存成員對象 o2 的節點又排在保存成員對象 o3 的節點之前, 由此可見, o1 、 o2 、 o3 三個成員對象在字典中的排序為 o1 <= o2 <= o3 。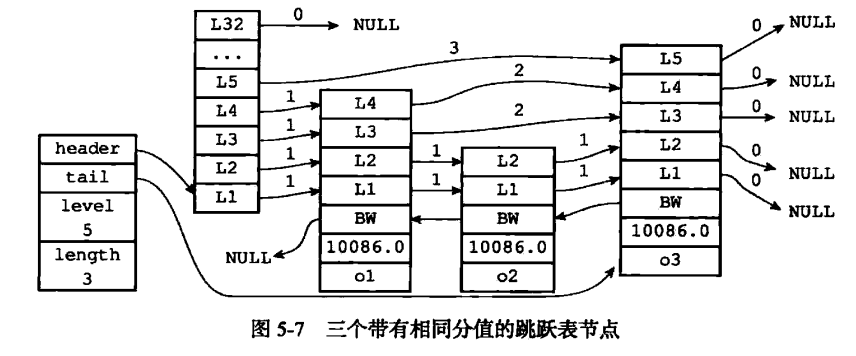
雖然僅靠多個跳躍表節點就可以組成一個跳躍表, 如圖 5-8 所示。
但通過使用一個 zskiplist 結構來持有這些節點,程序可以更方便地對整個跳躍表進行處理,比如快速訪問跳躍表的表頭節點和表尾節點,又或者快速地獲取跳躍表節點的數量(也即是跳躍表的長度)等信息, 如圖 5-9 所示。
zskiplist 結構的定義如下:
typedef struct zskiplist {
// 表頭節點和表尾節點
struct zskiplistNode *header, *tail;
// 表中節點的數量
unsigned long length;
// 表中層數最大的節點的層數
int level;
} zskiplist;如圖: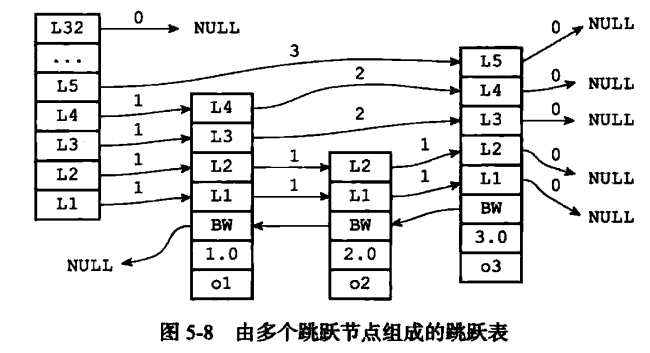
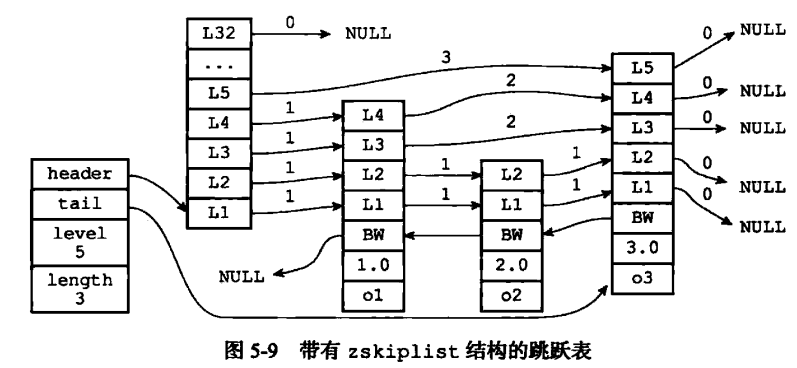
header 和 tail 指針分別指向跳躍表的表頭和表尾節點,通過這兩個指針,程序定位表頭節點和表尾節點的復雜度為 O(1) 。
通過使用 length 屬性來記錄節點的數量,程序可以在 O(1)復雜度內返回跳躍表的長度。level 屬性則用于在 O(1) 復雜度內獲取跳躍表中層高最大的那個節點的層數量,注意表頭節點的層高并不計算在內。
?以表格的形式列出了跳躍表的API操作,以及API的時間復雜度。
| 函數 | 作用 | 時間復雜度 |
|---|---|---|
| zslCreate | 創建一個新的跳躍表。 | O(1) |
| zslFree | 釋放給定跳躍表,以及表中包含的所有節點。 | O(N) , N 為跳躍表的長度。 |
| zslInsert | 將包含給定成員和分值的新節點添加到跳躍表中。 | 平均 O(log N) ,最壞 O(N) , N 為跳躍表長度。 |
| zslDelete | 刪除跳躍表中包含給定成員和分值的節點。 | 平均 O(log N) ,最壞 O(N) , N 為跳躍表長度。 |
| zslGetRank | 返回包含給定成員和分值的節點在跳躍表中的排位。 | 平均 O(log N) ,最壞 O(N) , N 為跳躍表長度。 |
| zslGetElementByRank | 返回跳躍表在給定排位上的節點。 | 平均 O(log N) ,最壞 O(N) , N 為跳躍表長度。 |
| zslIsInRange | 給定一個分值范圍(range), 比如 0 到 15 , 20 到 28,諸如此類, 如果給定的分值范圍包含在跳躍表的分值范圍之內, 那么返回 1 ,否則返回 0 。 | 通過跳躍表的表頭節點和表尾節點, 這個檢測可以用 O(1) 復雜度完成。 |
| zslFirstInRange | 給定一個分值范圍, 返回跳躍表中第一個符合這個范圍的節點。 | 平均 O(log N) ,最壞 O(N) 。 N 為跳躍表長度。 |
| zslLastInRange | 給定一個分值范圍, 返回跳躍表中最后一個符合這個范圍的節點。 | 平均 O(log N) ,最壞 O(N) 。 N 為跳躍表長度。 |
| zslDeleteRangeByScore | 給定一個分值范圍, 刪除跳躍表中所有在這個范圍之內的節點。 | O(N) , N 為被刪除節點數量。 |
| zslDeleteRangeByRank | 給定一個排位范圍, 刪除跳躍表中所有在這個范圍之內的節點。 | O(N) , N 為被刪除節點數量。 |
(1)跳躍表是有序集合的底層實現之一,除此之外它在 Redis 中沒有其他應用。
(2)Redis 的跳躍表實現由 zskiplist 和 zskiplistNode 兩個結構組成,其中 zskiplist 用于保存跳躍表信息(比如表頭節點、表尾節點、長度),而 zskiplistNode 則用于表示跳躍表節點。
(3)每個跳躍表節點的層高都是 1 至 32 之間的隨機數。
(4)在同一個跳躍表中,多個節點可以包含相同的分值,但每個節點的成員對象必須是唯一的。
(5)跳躍表中的節點按照分值大小進行排序,當分值相同時,節點按照成員對象的大小進行排序。
感謝各位的閱讀,以上就是“Redis跳躍表的結構實現方法”的內容了,經過本文的學習后,相信大家對Redis跳躍表的結構實現方法這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





