溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關什么是KNN算法及對新聞分類示例分析,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
KNN的全稱是(K Nearest Neighbors) K最鄰算法,意思是K個最近的鄰居。是最簡單的分類算法之一。 KNN是通過測量不同特征值之間的距離進行分類。它的思路是:如果一個樣本在特征空間中的k個最相似(即特征空間中最鄰近)的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別,其中K通常是不大于20的整數。KNN算法中,所選擇的鄰居都是已經正確分類的對象。該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。
算法流程
對每一個未知點執行:
計算未知點到所有已知類別點的距離
按距離排序(升序)
選取其中前k個與未知點離得最近的點
統計k個點中各個類別的個數
上述k個點里類別出現頻率最高的作為未知點的類別
優缺點
優點:
簡單有效、易理解
缺點:
k近鄰需要保存全部數據集,因此對內存消耗大,當數據集較大時對設備要求非常高;
需要計算每個未知點到全部已知點的距離,可能會很耗時;
分類結果不易理解
根據新聞文本判斷進行分類,如是科技新聞還是體育新聞等。
訓練數據樣表類型:

# -*- coding: utf-8 -*-
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import jieba
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix
import seaborn as sns
####1.解決中文亂碼問題
#指定默認字體
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'
#解決負號'-'顯示為方塊的問題
matplotlib.rcParams['axes.unicode_minus'] = False
###2 。導入數據
raw_train = pd.read_csv("./train_sample_utf8.csv",encoding="utf-8")
raw_test = pd.read_csv("./test_sample_utf8.csv",encoding="utf8")
### 3. 查看數據
print(raw_train.head(5))
print(raw_train.shape)
print(raw_test.shape)
####4. 對數據進行分類圖表顯示
##plt.figure(figsize=(15, 8))
##plt.subplot(1, 2, 1) ####要生成一行兩列,這是第一個圖plt.subplot('行','列','編號')
##raw_train["分類"].value_counts().sort_index().plot(kind="barh",title='訓練集新聞主題分布')
##plt.subplot(1, 2, 2)
##raw_test["分類"].value_counts().sort_index().plot(kind="barh",title='測試集新聞主題分布')
####5. 定義 對文章進行分詞函數
def news_cut(text):
return " ".join(list(jieba.cut(text)))
#簡單測試下分詞效果
#test_content = "六月初的一天,來自深圳的中國旅游團游客紛紛拿起相機拍攝新奇刺激的好萊塢環球影城主題公園場景。"
##print(news_cut(test_content))
###6. 利用封裝的分詞函數,對訓練集和測試集中的新聞內容進行分詞處理
raw_train["分詞文章"] = raw_train["文章"].map(news_cut)
raw_test["分詞文章"] = raw_test["文章"].map(news_cut)
###查看數據
print(raw_train.head(5))
####7. 加載停用詞
stop_words = []
file = open("./stopwords.txt",encoding="utf-8")
for line in file:
stop_words.append(line.strip())
file.close()
####8.利用CountVectorizer統計詞出現頻率,并轉為向量
vectorizer = CountVectorizer(stop_words=stop_words)
X_train = vectorizer.fit_transform(raw_train["分詞文章"])
X_test = vectorizer.transform(raw_test["分詞文章"])
#####9. 利用knn算法進行預測
knn = KNeighborsClassifier(n_neighbors=10,weights="distance")
knn.fit(X_train, raw_train["分類"])
Y_test = knn.predict(X_test)
##將真實測試值 與預測圖較,并繪制熱力圖展示
ax = sns.heatmap(confusion_matrix(raw_test["分類"].values,Y_test),linewidths=.5,cmap="Greens",
annot=True, fmt='d',xticklabels=knn.classes_, yticklabels=knn.classes_)
ax.set_ylabel('真實')
ax.set_xlabel('預測')
ax.xaxis.set_label_position('top')
ax.xaxis.tick_top()
ax.set_title('混淆矩陣熱力圖') 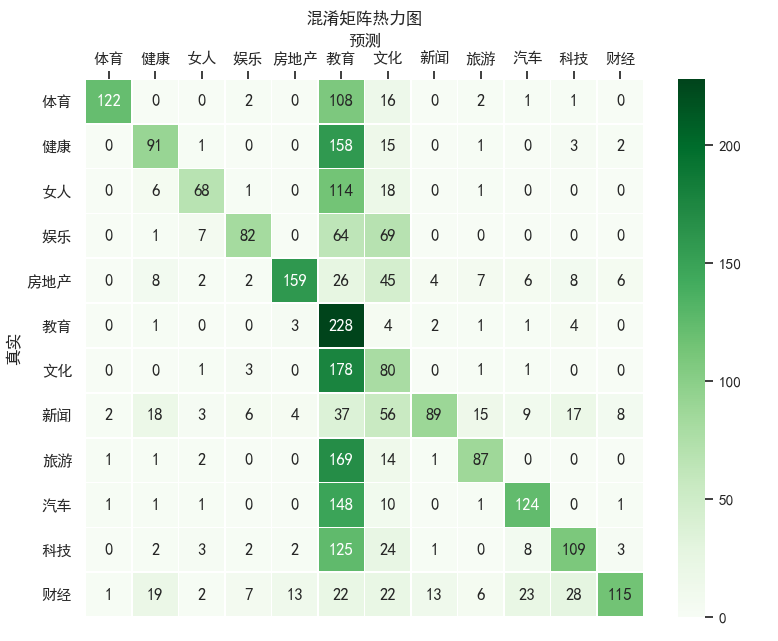
看完上述內容,你們對什么是KNN算法及對新聞分類示例分析有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





