溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹為什么用Scrapy無法使用Cookies登錄,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
我們知道,網站使用 Cookies 來記錄用戶的登錄狀態。如果我們從瀏覽器中把 Cookies 復制下來,放到爬蟲中,在某些情況下,就可以讓爬蟲直接訪問到登錄后的頁面。
以練習頁面http://exercise.kingname.info/exercise_login_success為例。在沒有登錄的情況下,訪問這個地址,會自動跳轉到登錄頁面,如下圖所示:
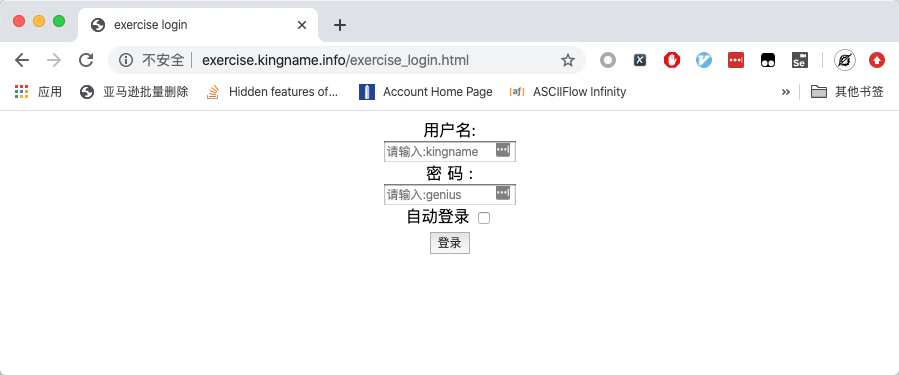
輸入用戶名kingname,密碼genius,點選自動登錄,并點擊登錄按鈕,跳轉到登錄成功的頁面,如下圖所示:
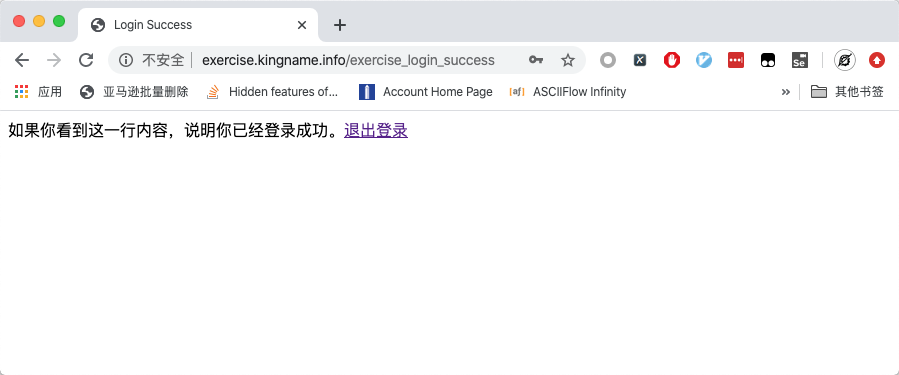
一旦登錄成功,即使關閉瀏覽器再重新打開該網址,依然會直接進入登錄后的頁面。
我們在 Chrome 的開發者工具中可以看到在登錄后,當我們刷新頁面時發送的請求:
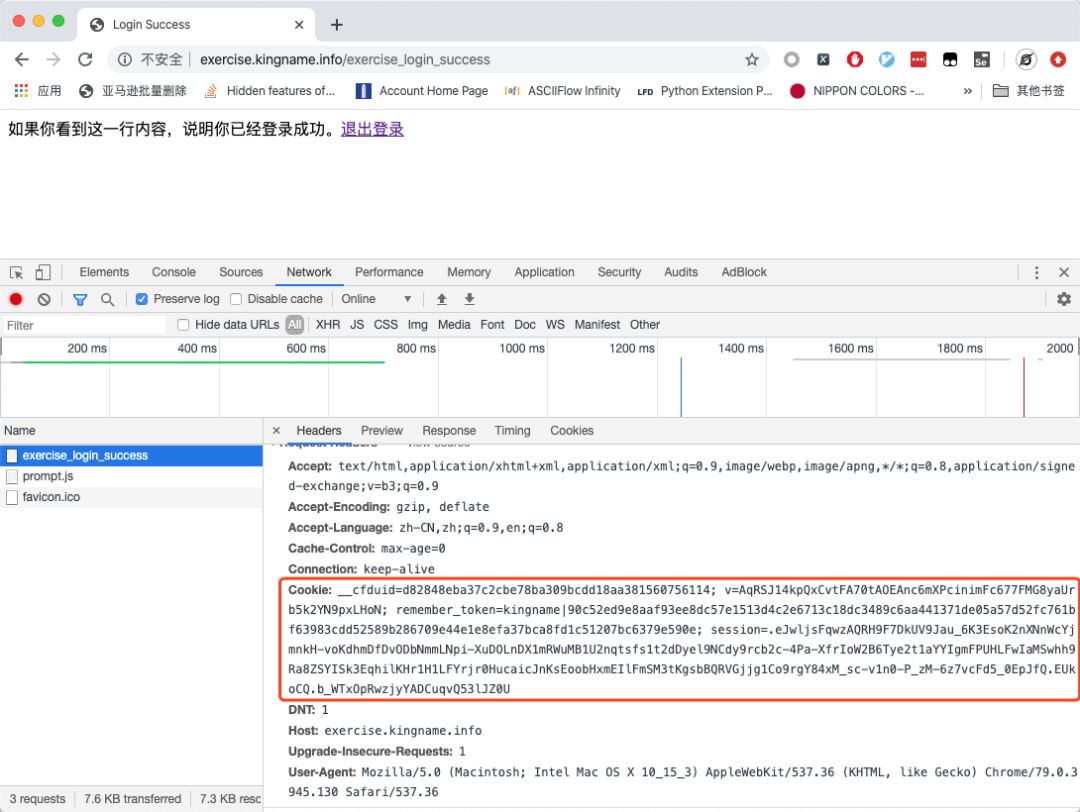
在 Request Headers里面可以看到請求頭,在請求頭中包含了 Cookie項。
當我們使用 Requests 訪問這個網址時,只要請求頭中含有這個 Cookie,我們就能直接訪問到請求成功的頁面,如下圖所示:
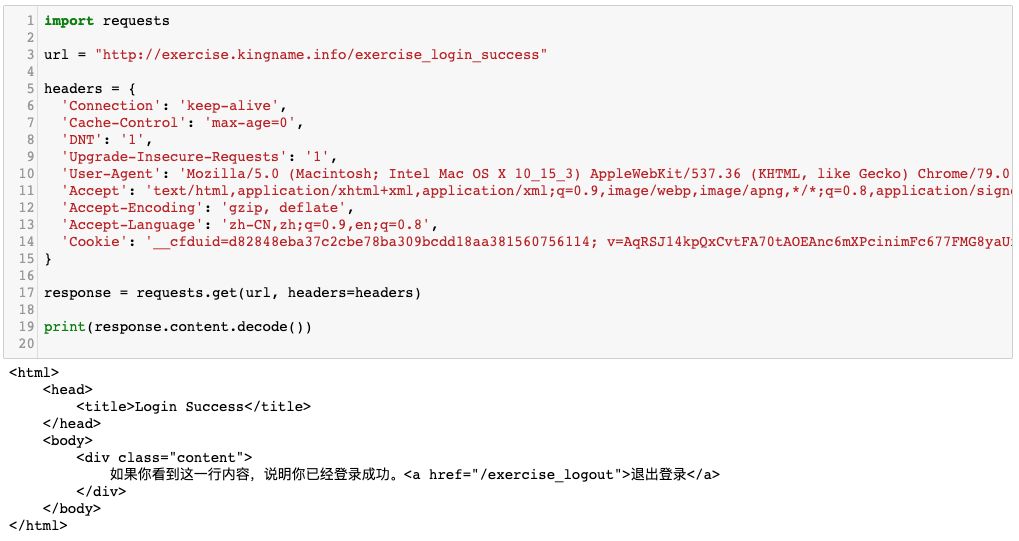
整個過程非常簡單并直觀。
但如果你想使用 Scrapy 做同樣的事情,你會發現登錄失敗了。如下圖所示:
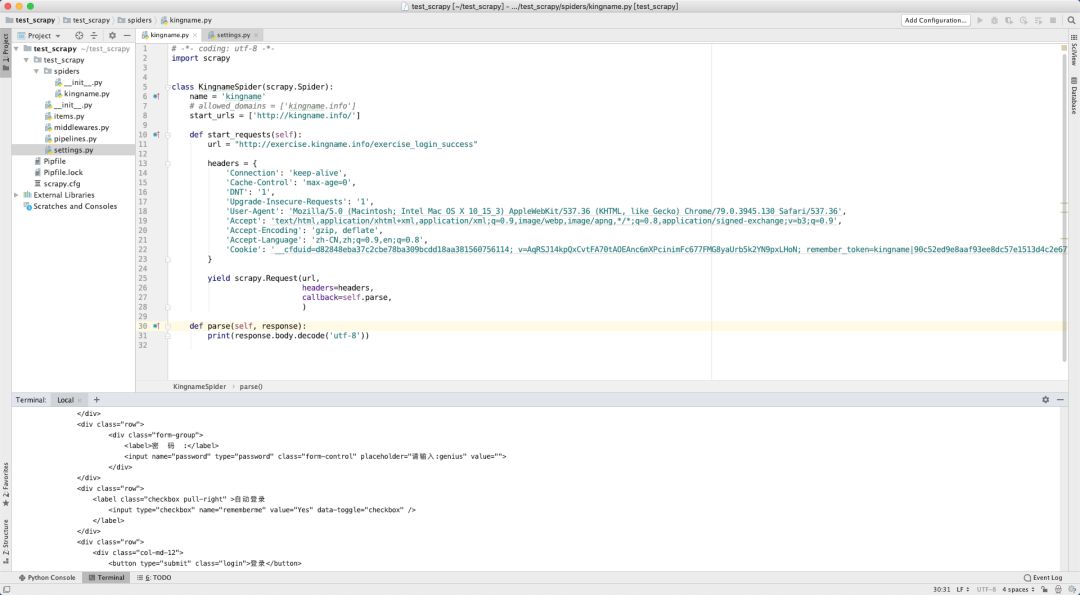
這其中的關鍵,就在于 Scrapy 發起請求的時候,并不會使用 Headers 中的 Cookie,而是單獨有一個cookies參數。
當使用 Request 時,Cookie在 Headers 中是以字符串的形式存在,不同的項目之間使用分號連接,項目內的鍵值之間使用冒號連接。
但是在 Scrapy 中,傳給cookies參數的值是一個字典,字典的 key 就是各個項目的 key,值就是各個項目的值。
所以我們對 Scrapy 的代碼稍作修改,從Headers 中移除 Cookie 項,并改成字典形式,傳給 cookies參數,再次請求發現請求成功:
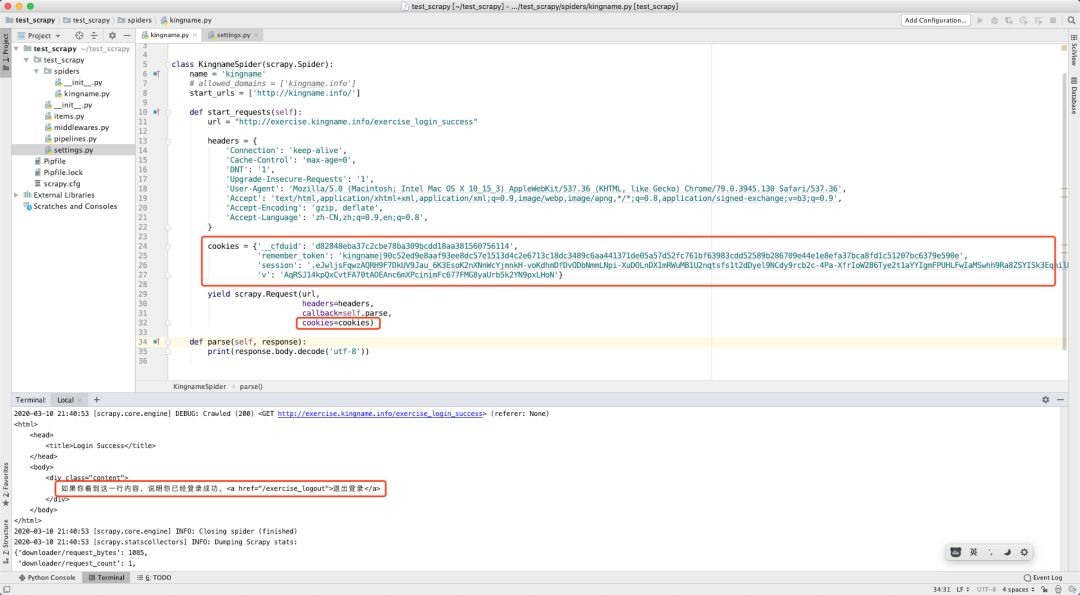
關于為什么用Scrapy無法使用Cookies登錄就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





