溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Gne如何提取新聞網頁,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
GNE[1]是我開源的一個新聞網站正文通用抽取器,自發布以來得到了很多同學的好評。
一直以來,GNE 是以 Python 包的形式存在,要測試 GNE 的提取效果,需要使用 pip 先安裝,再寫代碼使用。
為了降低測試 GNE 的成本,也為了讓更多同學了解 GNE,測試 GNE,我開發了網頁版的 GNE——Gne Online。
打開Gne Online 的地址為:http://122.51.39.219/,打開以后的頁面如下圖所示。
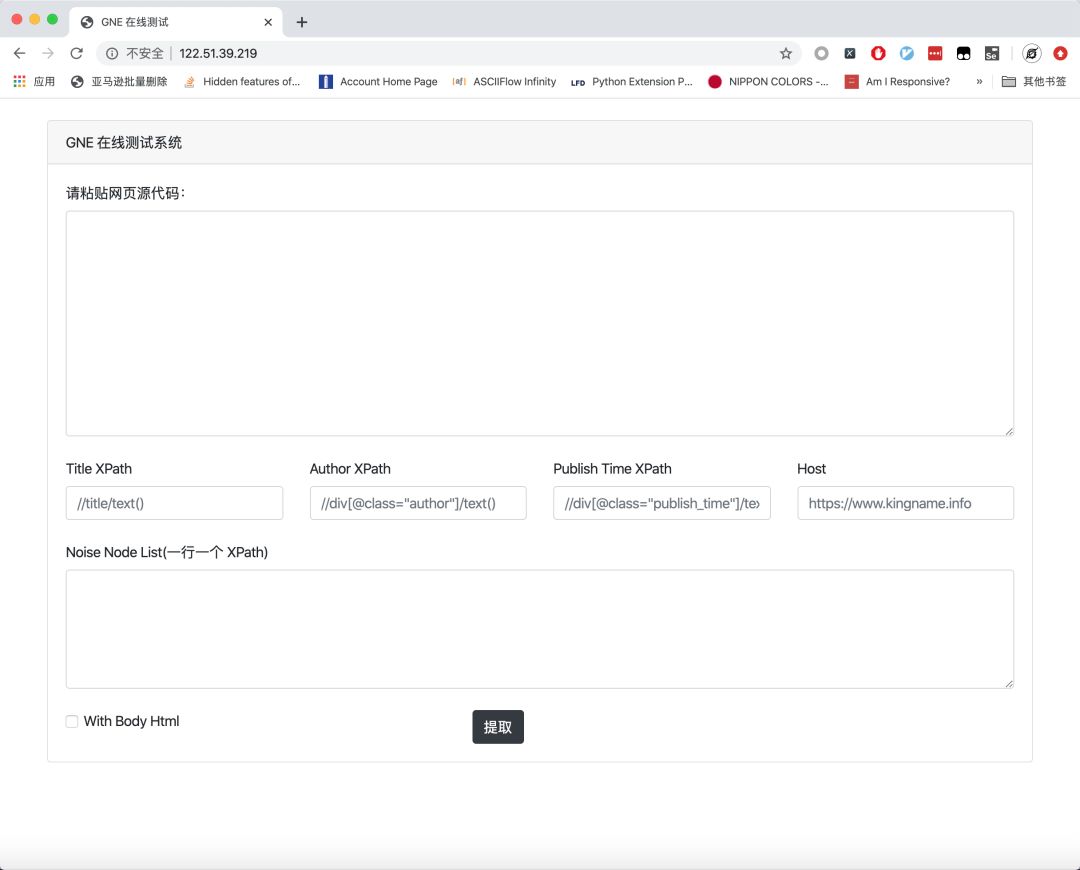
要測試 GNE 的功能,你只需要在最上面的文本框中粘貼網頁源代碼,并點擊提取按鈕即可:
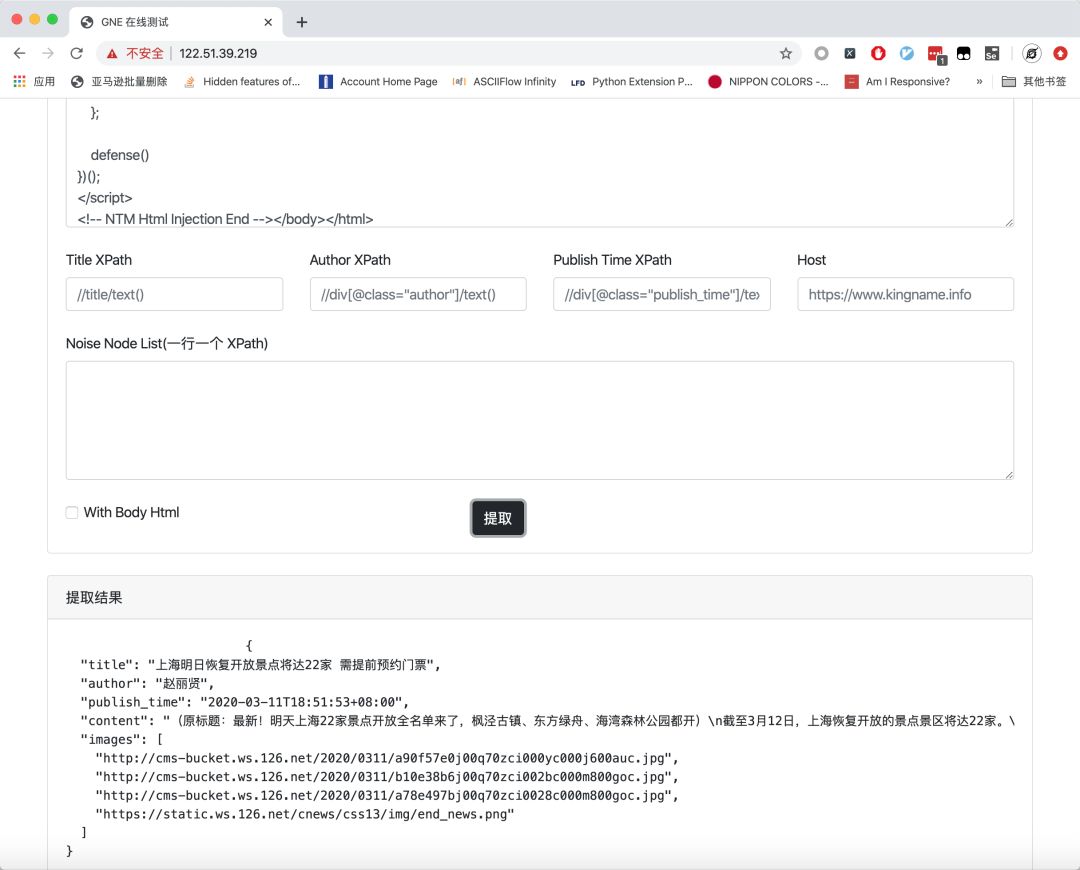
對于標題、作者、新聞發布時間這種可能發送誤提取的情況,我們可以通過下面對應的Title XPath、Author、Publish Time XPath來輸入 XPath 定向提取。例如對于今日頭條的文章:
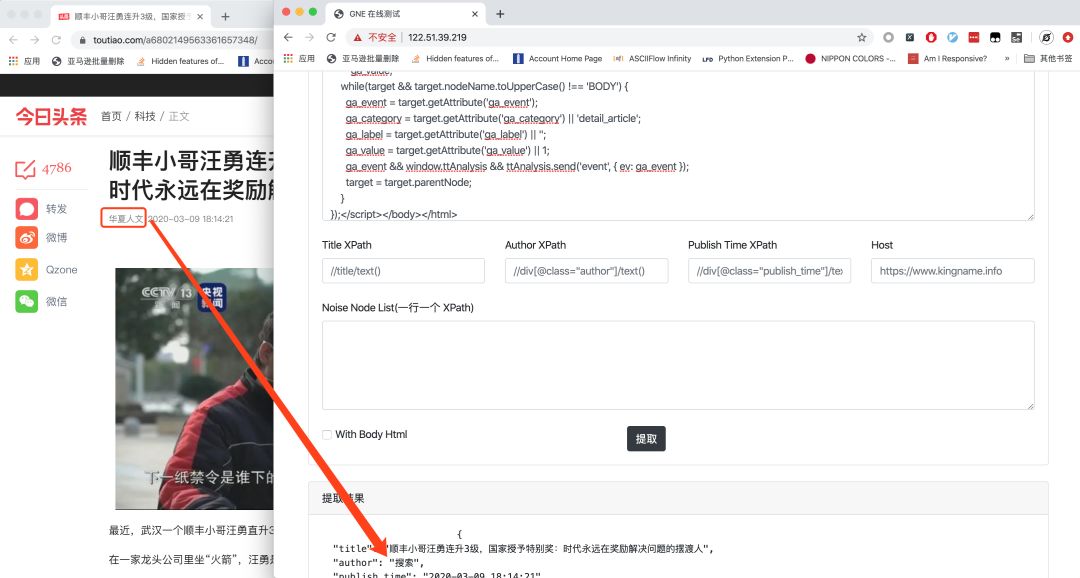
新聞的作者提取失誤,此時可以指定 XPath://div[@class="article-sub"]/span[1]/text()來定向提取,如下圖所示。
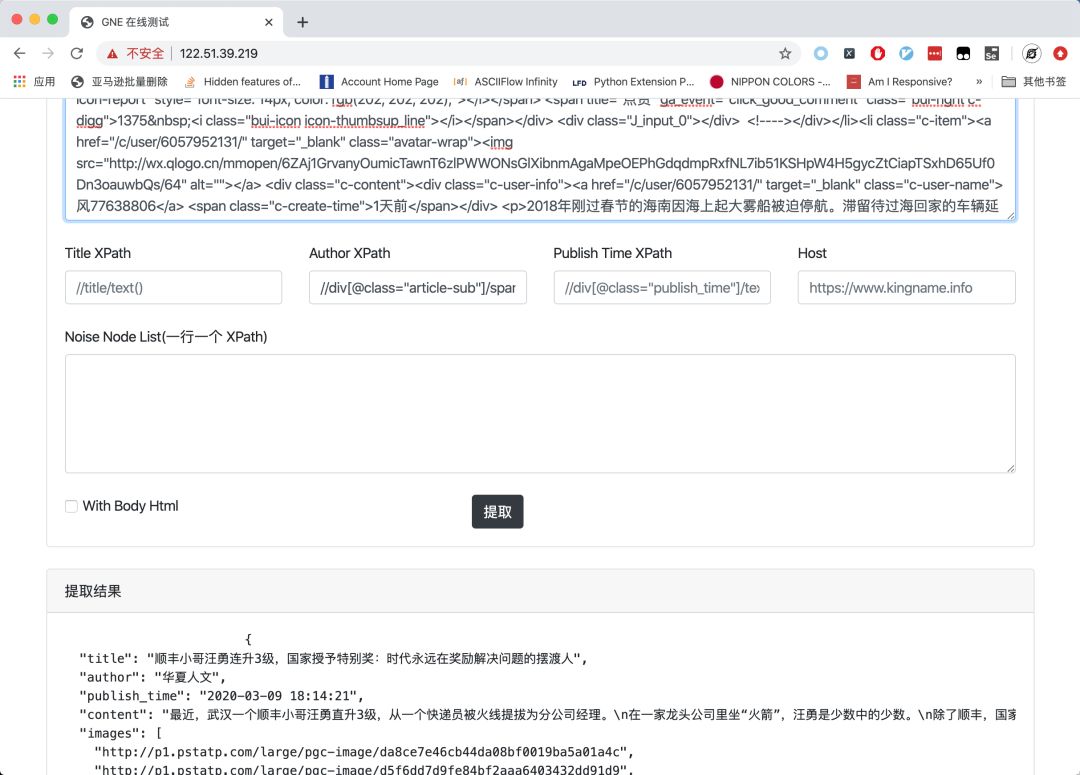
通過設定Host輸入框,可以在網頁正文中的圖片為相對路徑時,拼上網址。
通過勾選下面的With Body Html復選框,可以返回正文所在的區域的網頁源代碼。
看完上述內容,你們掌握Gne如何提取新聞網頁的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





