溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關MongoDB開發系中什么是數據集設計分桶范式,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
數據集設計模式,MongoDB在官方文檔https://docs.mongodb.com/ecosystem/ 中的use cases部分提供了詳細的參考內容。
分桶模式是MongoDB數據集設計的一種范式。
所謂分桶優化,就是與其對每一條數據創建一個文檔,我們可以把某一個時間段內的測量數據聚合到一起放到一個文檔內,利用MongoDB提供的內嵌式數組或子文檔特性
我們知道許多傳感器數據都是時間序列數據。例如:風傳感器,潮汐監測以及位置追蹤等采集數據的無非這種類型: Timestamp,采集器名稱/ID,采集值。對于時序類型的數據,我們可以采用一種叫做時間分桶的優化策略。
簡單的說 時間序列就是各時間點上形成的數值序列,時間序列分析就是通過觀察歷史數據預測未來的值。采用分桶設計寫入的數據集,元素更多的是采用時間作為排序元素,依次寫入和讀取。
官方有一篇翻譯文章,專門敘述 分桶設計模式
基礎數據集如下
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:02:00.000Z"),
temperature: 41
}
改進后的文檔集如下
{
sensor_id: 12345,
start_date: ISODate("2019-01-31T10:00:00.000Z"),
end_date: ISODate("2019-01-31T10:59:59.000Z"),
measurements: [
{
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
},
{
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
},
…
{
timestamp: ISODate("2019-01-31T10:42:00.000Z"),
temperature: 42
}
],
transaction_count: 42,
sum_temperature: 2413
}
我們在程序寫入文檔時,可以做一些簡單的計算和整理,按時間分段,根據業務需要,將一個時間斷內的大量文檔合并,避免數據使用時的隨機聚合和查詢。這樣的時間段,可以理解為桶。
在處理時間序列數據時,知道2018年7月13日加利福尼亞州康寧市下午2:00至3:00的平均溫度通常比知道下午2:03那一時刻的溫度更有意義也更重要。通過用桶組織數據并進行預聚合,我們可以更輕松地提供這些信息。
官方有一篇關于Iot使用場景的推薦文章 https://www.mongodb.com/customers/bosch,可以作為參考。
https://docs.mongodb.com/ecosystem/use-cases/storing-comments/ Hybrid Schema Design節點下說明了評論中的分桶操作場景。
首先我們看數據集模式
_id: ObjectId(...),
discussion_id: ObjectId(...),
bucket: 1,
count: 42,
comments: [ {
slug: '34db',
posted: ISODateTime(...),
author: { id: ObjectId(...), name: 'Rick' },
text: 'This is so bogus ... ' },
... ]
}
我在數據集設計的文章中提到分桶模式的設計場景,主要用于時間序列的數據預處理和分塊存儲。時間序列也就是按照時間的先后排序,依次寫入。分塊的標準可以是時間,比如一天,一個小時,或者是評論數目。
Also, 100 comments is a soft limit for the number of comments per bucket. This value is arbitrary: choose a value that will prevent the maximum document size from growing beyond the 16MB BSON documentsize limit,
以上總體含義是說每個桶內的元素個數不是固定的,是應用開發時,根據實際情況評估后的一個度量。但是需要考慮MongoDB本身每個文檔最多16M的限制。
對于應用程序來說,這樣的設計模式在寫入操作是需要做一些簡單的邏輯,來確定寫入哪個桶,以及簡單計算,如下
if bucket['count'] > 100:
db.discussion.update(
{ 'discussion_id: discussion['_id'],
'num_buckets': discussion['num_buckets'] },
{ '$inc': { 'num_buckets': 1 } } )
借助2019年MongoDB中國用戶大會的一張PPT更加清晰的認識下分桶范式
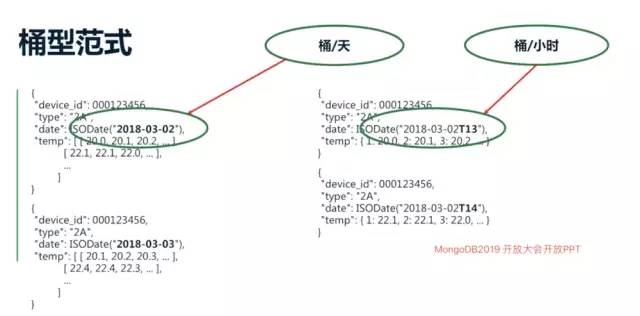
buckets.png
文章中的觀點有不嚴謹之處,歡迎評論溝通。邊學習,邊實踐,邊參考,邊改進,在問題中成長。
看完上述內容,你們對MongoDB開發系中什么是數據集設計分桶范式有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





