溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了如何進行MYSQL Skip Scan Range小功能的分析,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
正文
用過MYSQL的都會被別的數據庫的operation 吐槽,索引的建立與使用方面的需要掌握的知識是比較“矯情的”。為什么這么說,在MYSQL 5.X中如果一個表中 有這樣的索引,和這樣的查詢,索引的效率就會大打折扣。
我們來看一下,根據官方的文檔我們創建下面的數據
請準備MYSQL 8.013以上版本 以及 MYSQL 5.7 版本的兩臺機器,并執行下面的操作
CREATE TABLE t1 (f1 INT NOT NULL, f2 INT NOT NULL, PRIMARY KEY(f1, f2));
INSERT INTO t1 VALUES
(1,1), (1,2), (1,3), (1,4), (1,5),
(2,1), (2,2), (2,3), (2,4), (2,5);
INSERT INTO t1 SELECT f1, f2 + 5 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 10 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 20 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 40 FROM t1;
ANALYZE TABLE t1;
EXPLAIN SELECT f1, f2 FROM t1 WHERE f2 > 40;
set session optimizer_trace=’enabled=on';
然后我們通過optimizer_trace 來查看這兩個服務器上查詢上面的給出的分析結果
下面的圖形僅僅只給出不同的截圖(這里就不贅述了)
1 MYSQL 5.7 的 row_estimation ,我看可以看到很簡單

2 下面是MYSQL 8.017 的圖,從下圖看,明顯的MYSQL 8 在查詢計劃的分析要比 MYSQL 5.7 復雜的多,其中第二張圖已經顯示走了skip_scan


既然看到不同,但問題是這樣有什么用,首先如果是MYSQL 5.7 上基本上走的是 INDEX Scan 而, 而在MYSQL 8 上做的事情要遠遠多于 MYSQL5.7 從上圖可以看出,首先查詢先將索引中的前邊的字段,進行了group by 的操作,將需要進行掃描的數據通過第一個字段劃分了塊,然后在每個塊中掃描range 的數據。
這樣的好處也是顯而易見的,如果將數據掃描進行分塊處理,有些不包含range 的數據塊將不被掃描,或者不包含range 的行也將不被掃描。
這項功能也是有一定要求的
1 必須單表
2 不能有group distinct 的操作
3 索引兩邊的字段都可以包含NULL ,但中間的字段不可以有NULL
下面在做一個測試確認一下前邊有兩個字段的情況下,是不是也是可以走skip scan index
CREATE TABLE t2 (f1 INT NOT NULL, f2 INT NOT NULL,f3 int not null);
INSERT INTO t2 VALUES
(1,1,2), (1,2,3), (1,3,4), (1,4,5), (1,5,6),
(2,1,3), (2,2,4), (2,3,6), (2,4,2), (2,5,4);
INSERT INTO t2 SELECT f1, f2 + 5,f3 + 2 FROM t2;
INSERT INTO t2 SELECT f1, f2 + 10,f3 + 4 FROM t2;
INSERT INTO t2 SELECT f1, f2 + 20, f3 + 5 FROM t2;
INSERT INTO t2 SELECT f1, f2 + 4, f3 + 6 FROM t2;
ANALYZE TABLE t1;
create index ix_t2_f2_f3 on t2 (f1,f2,f3);
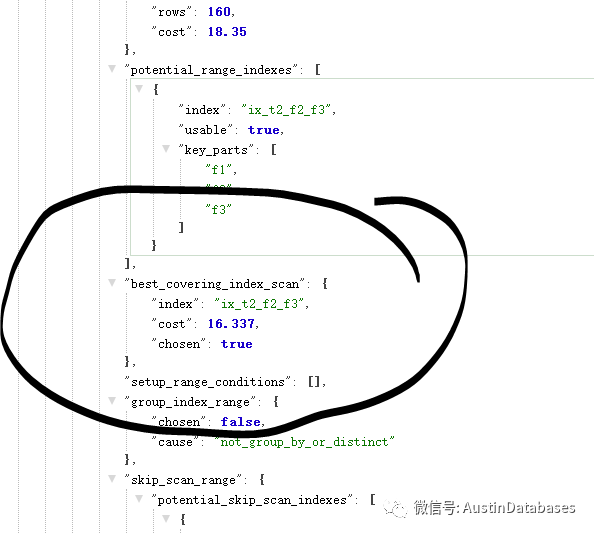
最終的結果還是可以走的,其實可以理解為,前邊將兩個沒有條件的字段都變為有具體值的條件匹配后面的字段的范圍查詢。
這個做法在ORACLE 早就是有的功能,目前MYSQL 也繼承了這個功能。
上述內容就是如何進行MYSQL Skip Scan Range小功能的分析,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





