溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下python spider成交數據及在售數據爬取方法是什么的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
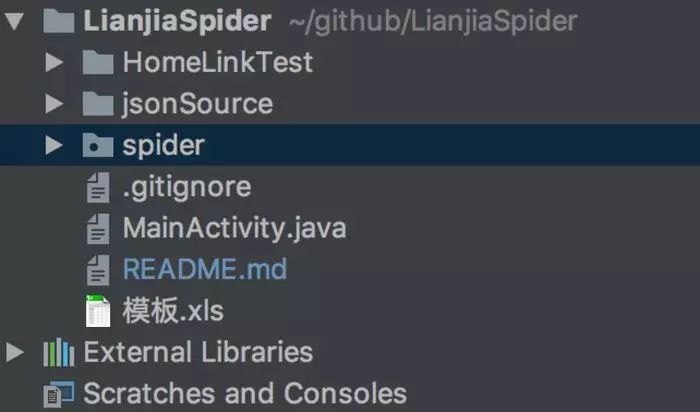
HomeLinkTest : Android 工程(用于破解鏈家App簽名驗證內容)
jsonSource: 鏈家客戶端json傳內容樣本,包含(成交商品列表頁,成交商品詳情頁,成交商品更多內容頁)(在售商品列表頁,在售商品詳情頁,在售商品更多內容頁)
spider:鏈家爬蟲腳本(python腳本)(爬取PC端在線數據,移動端在售數據和成交數據)
爬取web界面在售內容 https://bj.lianjia.com/ershoufang/ 僅爬取在售內容(使用正則表達式進行內容匹配,進行結果輸出)(常用爬蟲方法,分析界面html進行內容獲取,使用動態代理偽裝客戶端進行訪問具體內容進參考代碼)
python LianjiaSpider/spider/salingInfoSpider.py
使用代理服務器(開源地址):
https://raw.githubusercontent.com/fate0/proxylist/master/proxy.list
(工程內代理服務器內容可用于其他工程)
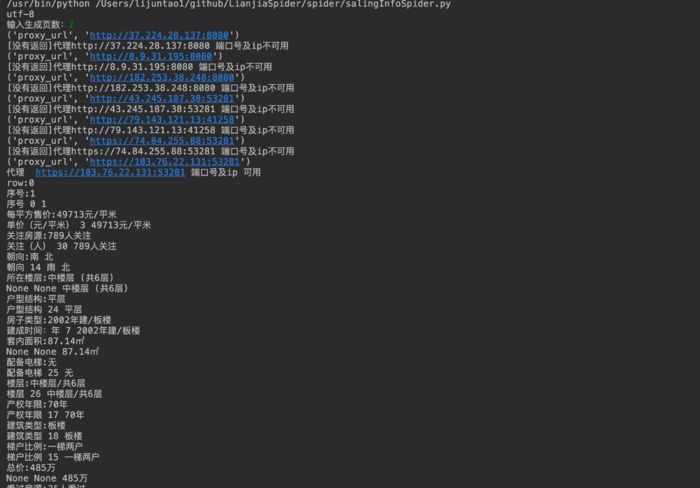
進行代理服務器設置,抓取到內容后進行相對目錄excle目錄內容存儲,運行圖如圖所示:
(輸入頁數為鏈家PC頁面當前第幾頁內容)
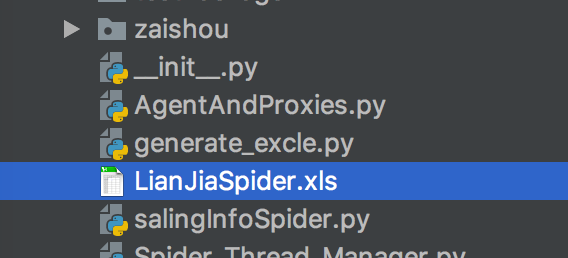
爬取結果圖如圖所示(在相對salingInfoSpider.py目錄生成LianJiaSpider.xls excle表格):

基于鏈家app:https://bj.lianjia.com/ 針對其簽名校驗進行破解
獲取對應的json內容,進行自動爬取(僅做技術交流,請勿進行商業應用或其他侵權行為)
在售數據爬取:
python LianjiaSpider/spider/zaishou/zaiShouSpider.py
設置爬取頁數和一頁多少數據
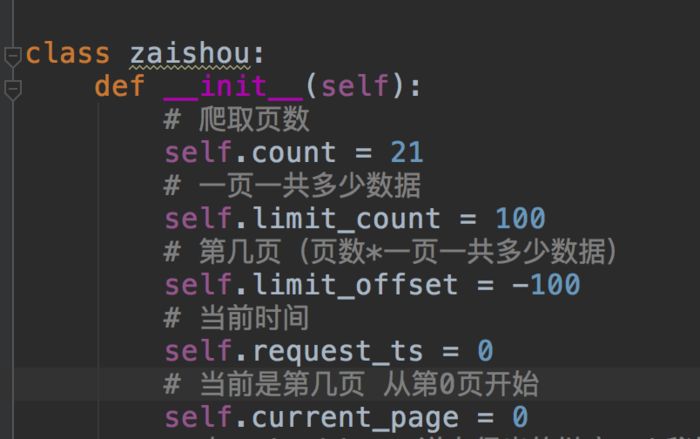
結果生成在同級目錄中生成excle,如圖所示:
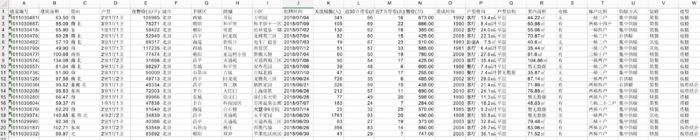
成交數據爬取:
python LianjiaSpider/spider/zaishou/chengJiaoJiaSpider.py
修改全局設置,注銷手動輸入,或使用手動輸入:
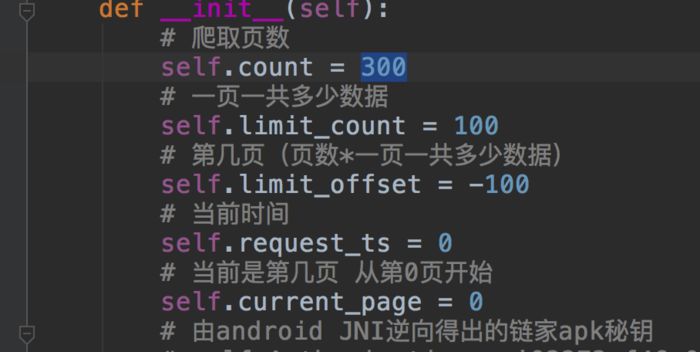
chengJiaoJiaSpider.py中可設置爬取頁數,其實位置,從第0頁開始,所以是-100開始
成交數據如圖所示:
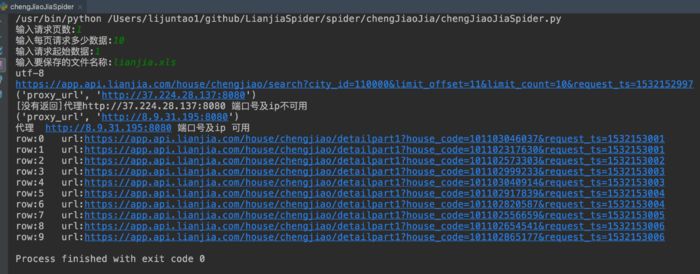

在售及成交數據自動爬取:
python LianjiaSpider/spider/Spider_Thread_Manager.py
以上就是“python spider成交數據及在售數據爬取方法是什么”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





