溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“python聚類實例分析”,在日常操作中,相信很多人在python聚類實例分析問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”python聚類實例分析”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
聚類分析
將數據存儲為csv格式,導入python,查看前10行數據。
import pandas as pd
reviewsdata = pd.read_csv('reviewsdata.csv',index_col=0)#index_col=0第一列所為行索引
reviewsdata.head(10)
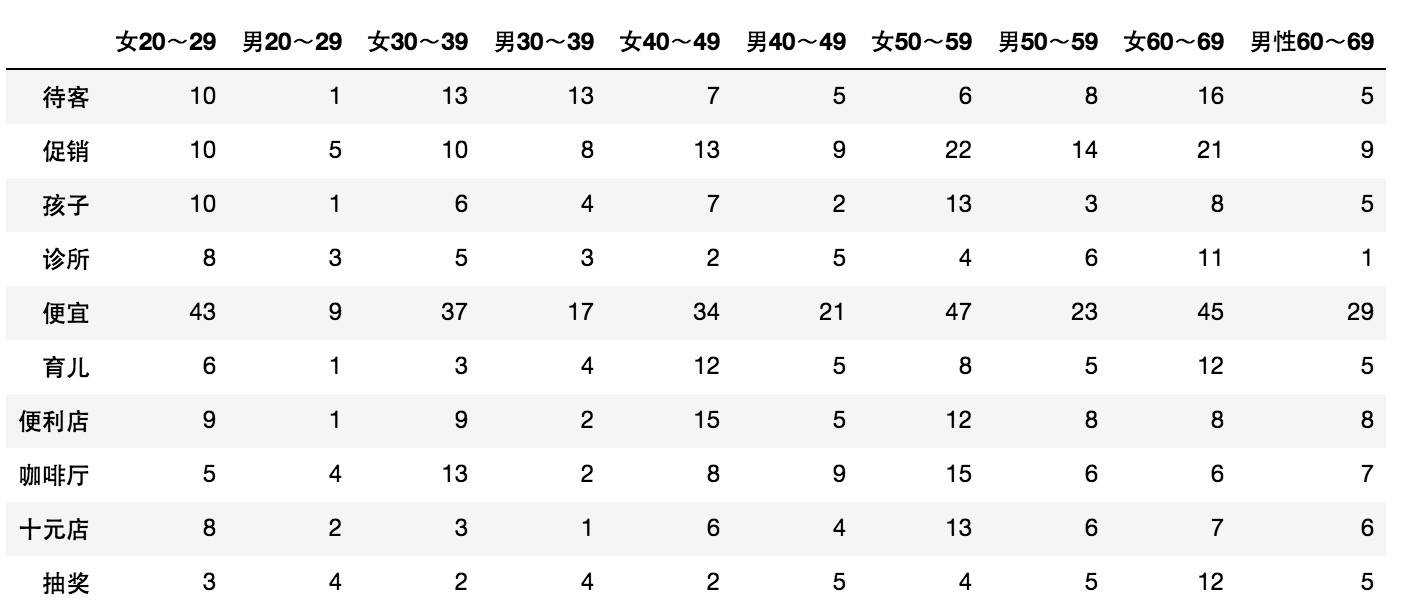
從表格中,可以看到不同性別、不同年齡使用不同單詞的頻數。對數據進行聚類分析,并畫出聚類樹形圖。
import scipy
import scipy.cluster.hierarchy as sch
import matplotlib.pylab as plt
import pylab
#生成點與點之間的距離矩陣,這里用的歐氏距離:
disMat = sch.distance.pdist(reviewsdata.T,'euclidean')
#進行層次聚類:
Z=sch.linkage(disMat,method='average')
#將層級聚類結果以樹狀圖表示出來并保存為plot_dendrogram.png
sch.dendrogram(Z,labels=reviewsdata.columns,leaf_font_size=7.5)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("口碑的聚類")
pylab.show()
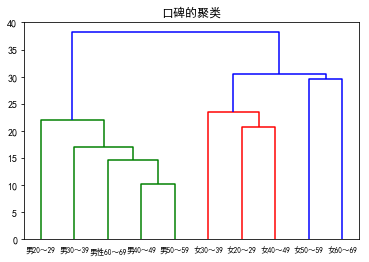
在聚類分析的過程中,是將不同性別年齡的人群使用詞的頻數生成向量,然后比較這些向量的距離,將距離較近的總結在一起。距離近意味著措辭相仿,聚類也就是不斷合并兩個最相近向量的過程。從圖顯示,40多歲男性和50多歲男性在使用單詞方面很接近,但跟60多歲女性明顯不同。整體上,能看出不同年齡段和不同性別之間存在意見差異。
幾個小概念
聚類分析:一種根據數據相似度將數據分組對手法,分組前,不能確定每一類的特征。數據相似度通過距離來判斷,求距離的方法有很多種,最簡單的為歐式距離。本文使用的是層次聚類,文章聚類(一):DBSCAN算法實現(r語言)中介紹了DBSCAN聚類方法。
到此,關于“python聚類實例分析”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





