溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Flink在快手實時多維分析場景的應用是什么,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
Flink 在快手應用場景及規模




快手實時多維分析平臺

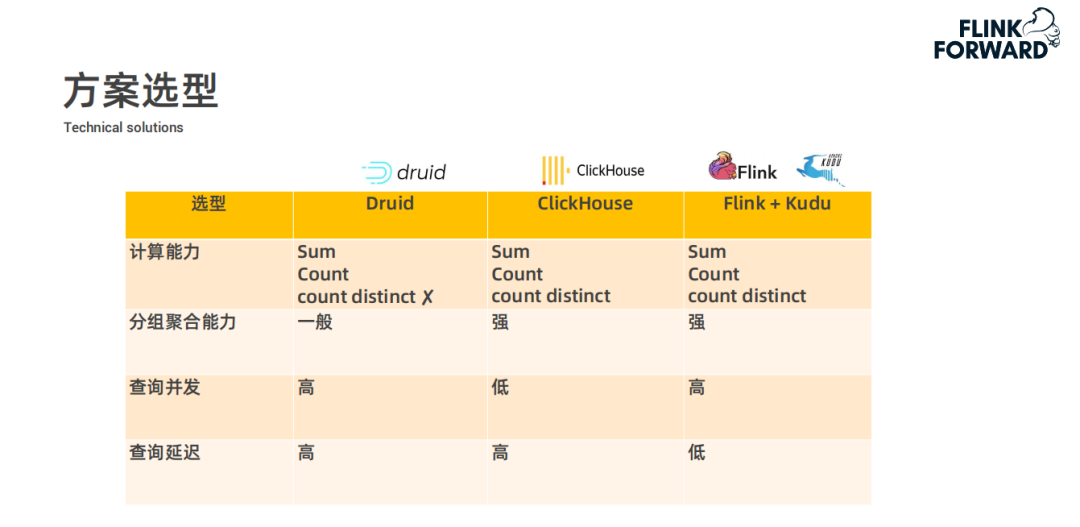

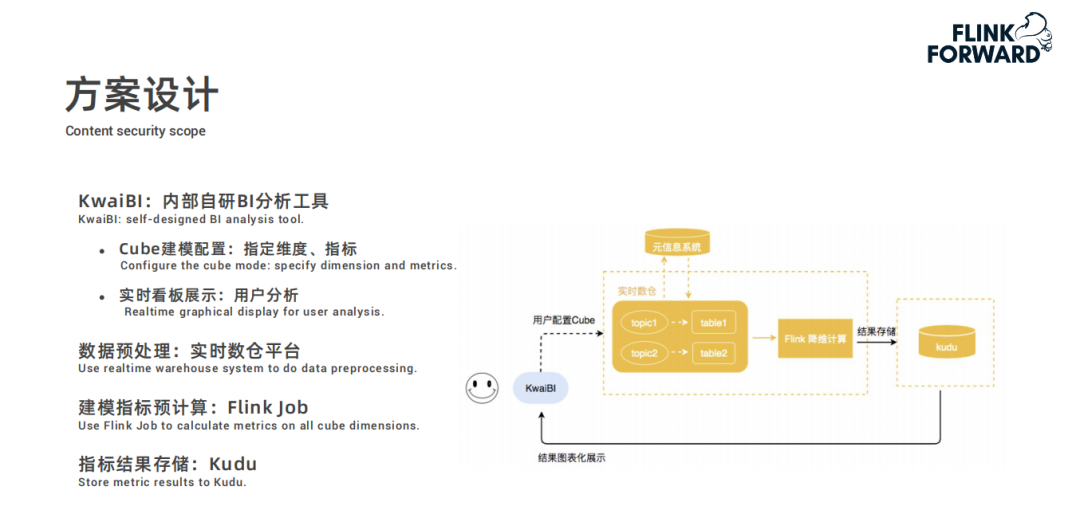
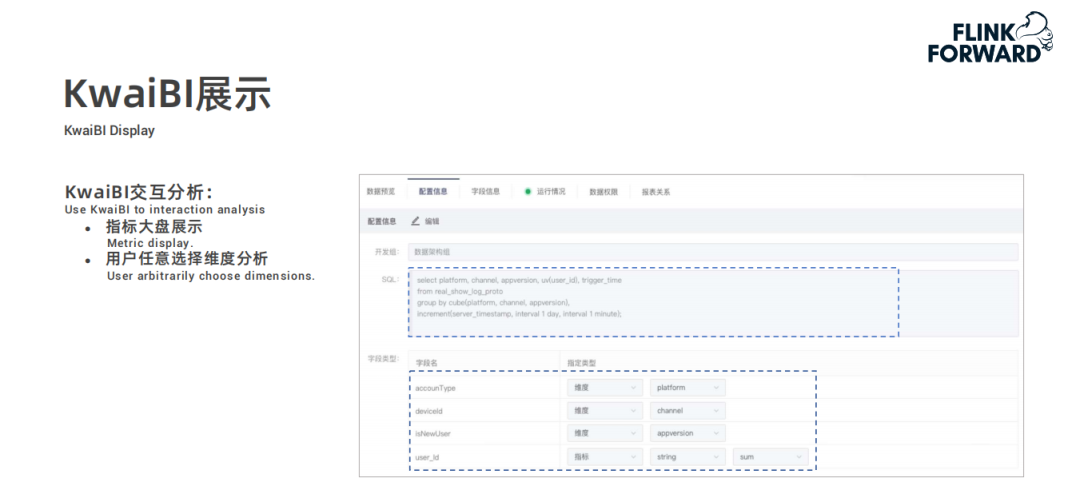
用戶在快手自研的 BI 分析工具 KwaiBI 上配置 Cube 數據立方體模型,指定維度列和指標列以及基于指標做什么樣的計算;
配置過程中選擇的數據表是經過處理過后存儲在實時數倉平臺中的數據表;
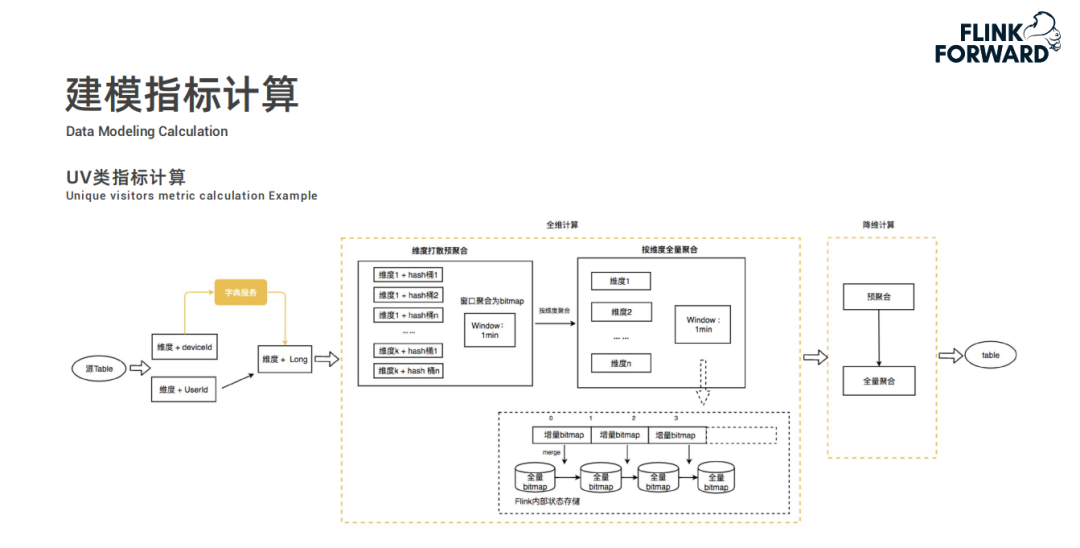
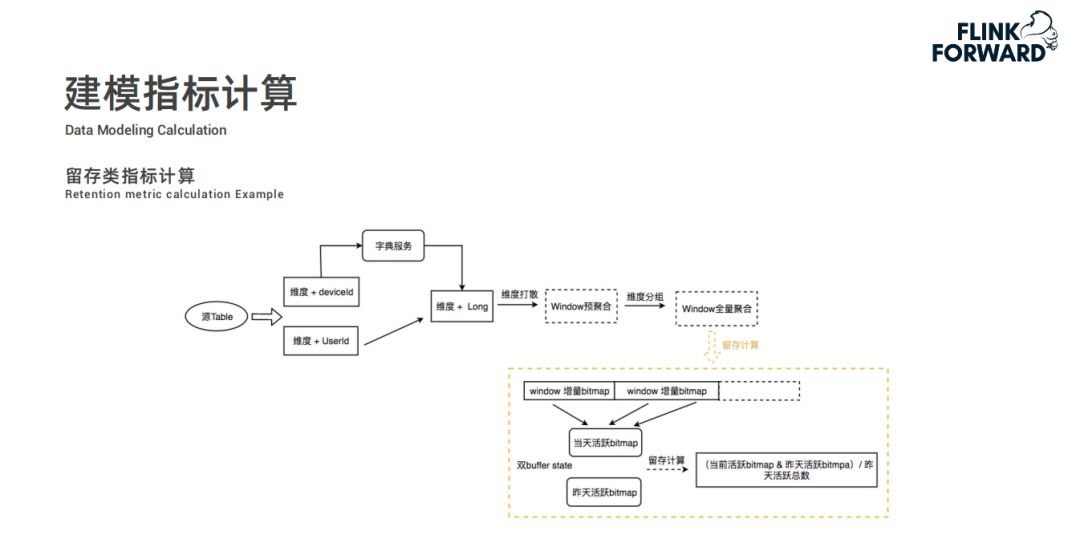
然后根據配置的計算規則通過 Flink 任務進行建模指標的預計算,結果存儲到 Kudu 中;
最后 KwaiBI 從 Kudu 中查詢數據進行實時看板展示。
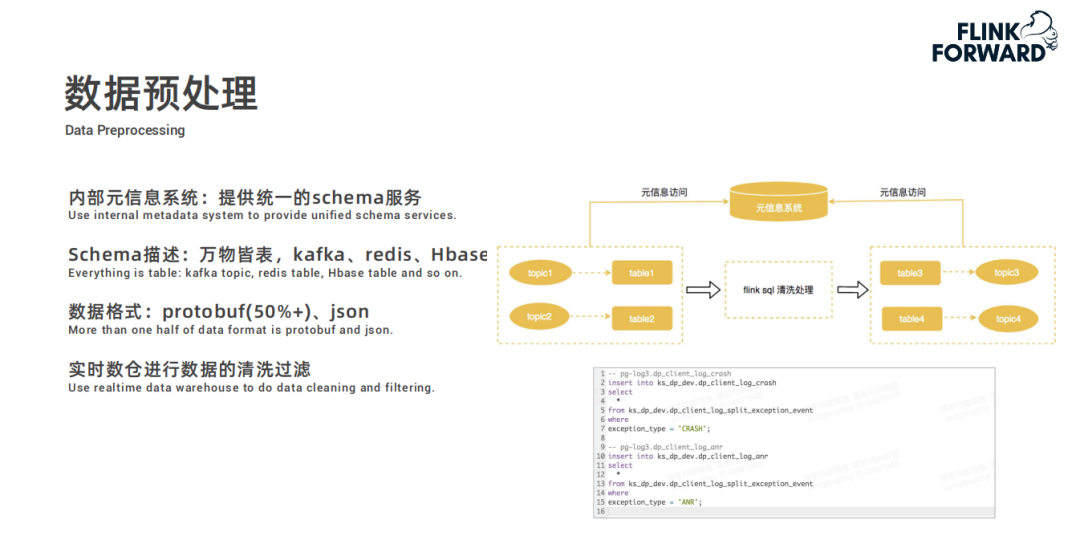
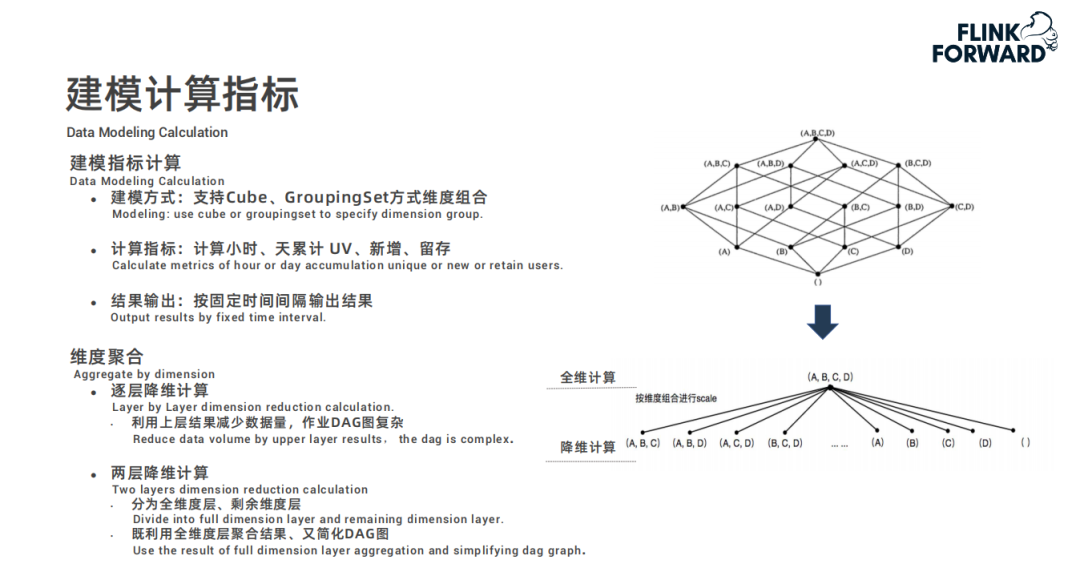



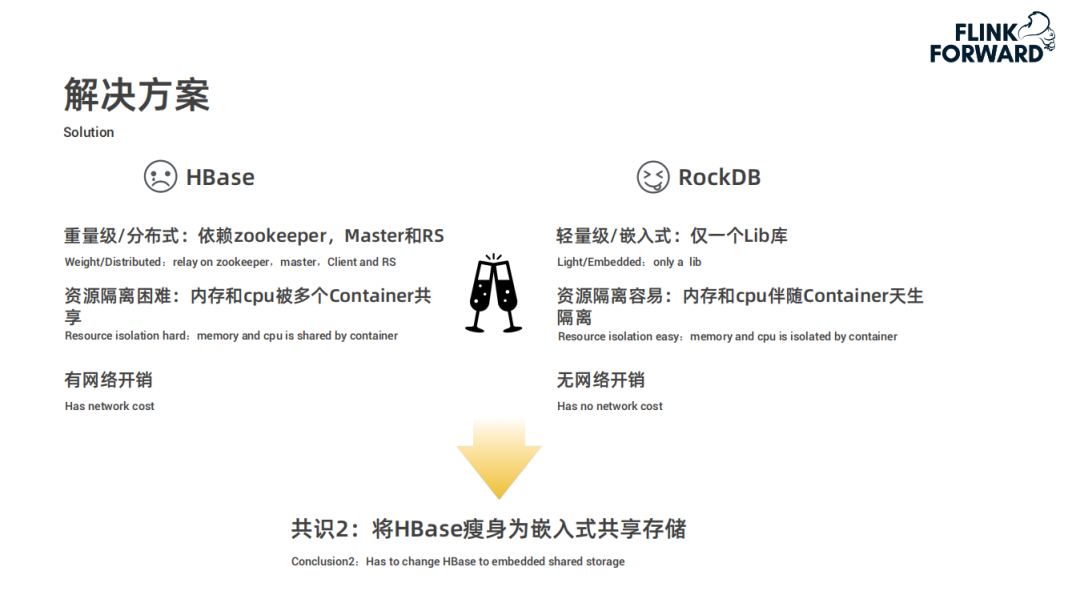
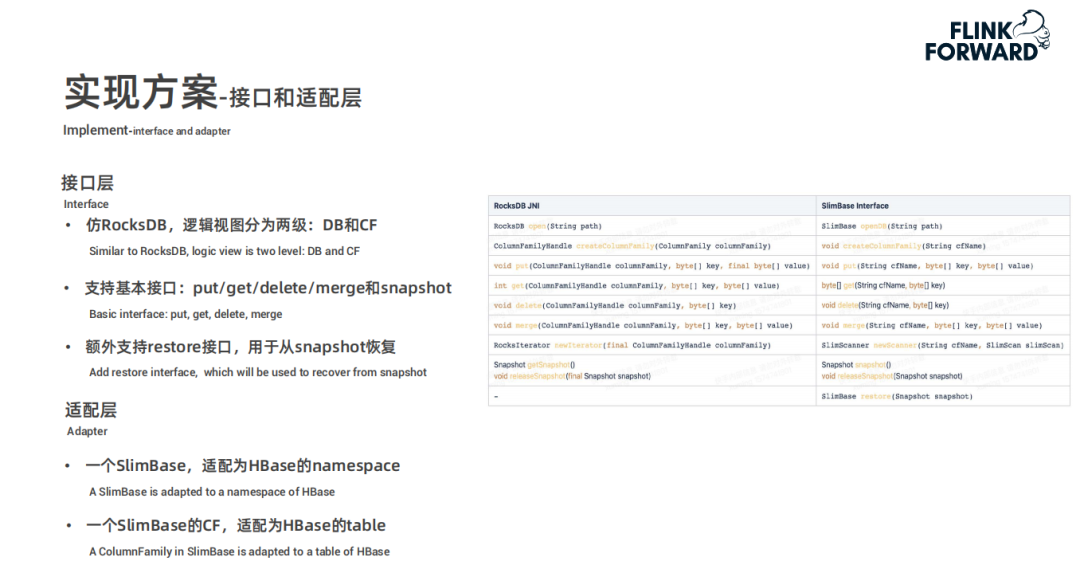
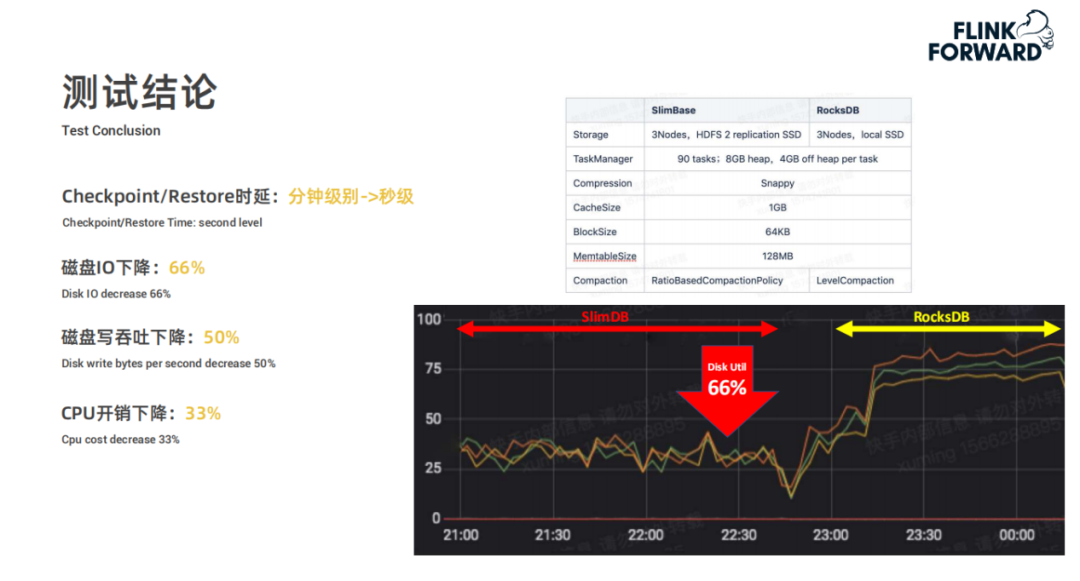
SlimBase-更省 IO、嵌入式共享 state 存儲








看完上述內容,你們掌握Flink在快手實時多維分析場景的應用是什么的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





