溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python3怎么爬取英雄聯盟所有英雄皮膚,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
打開英雄聯盟官網,點擊游戲資料,繼續按F12,按F5刷新,就會發現有一個champion.js文件,復制這個js文件的地址.和王者榮耀不同,這個是js而王者是json比較好處理。js中有英雄的編號和名字,將keys中的數據拿出來
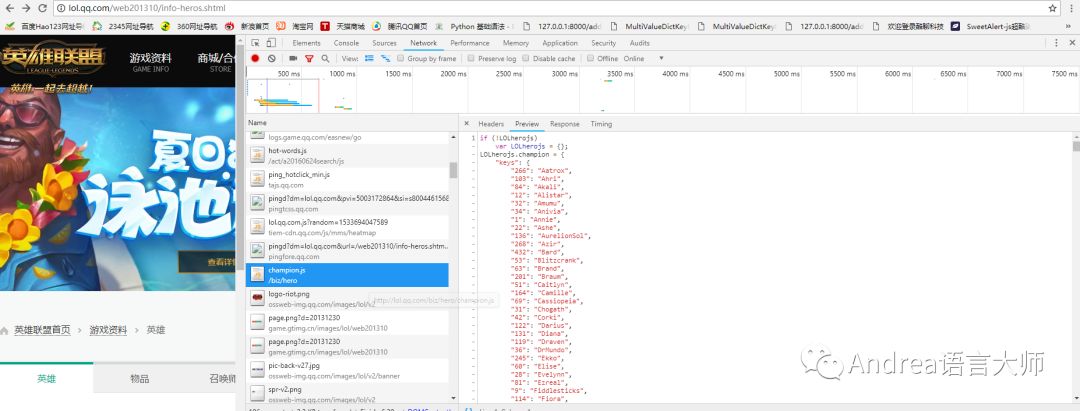
通過requests的get方法獲取到響應的內容,pat_js是正則的規則,compile函數將包含的正則表達式的字符串創建模式對象,直接調用findall方法。返回的就是匹配的字串以列表的形式顯示。eval將其轉換為字典
def path_js(url_js):
res_js = requests.get(url_js, verify= False).content
html_js = res_js.decode("gbk")
pat_js = r'"keys":(.*?),"data"'
enc = re.compile(pat_js)
list_js = enc.findall(html_js)
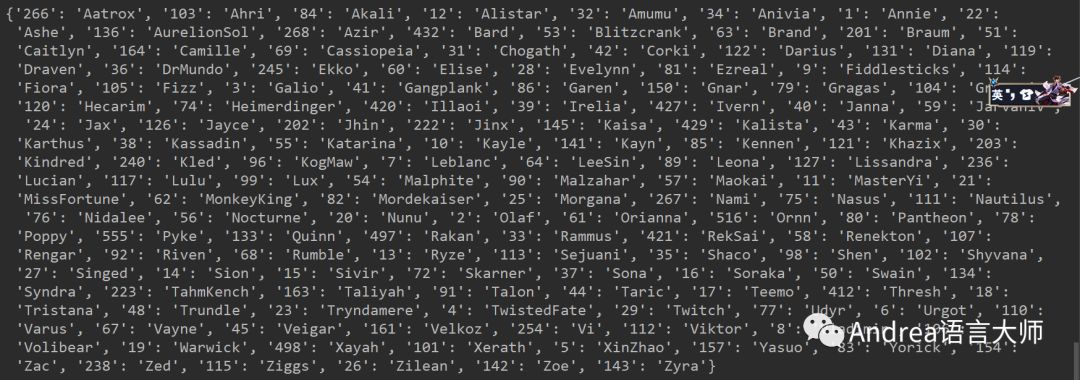
dict_js = eval(list_js[0])
print(dict_js)
--------------------------------------------------------------------------------------------------------
在頁面中點開英雄資料,沒有英雄的皮膚url,需要右鍵,在新標簽頁打開,獲取到連接http://ossweb-img.qq.com/images/lol/web201310/skin/big266000.jpg
根據獲取到的鏈接分析,big后前三個數字代表英雄的編號,后三個代表皮膚的個數,根據此來拼接獲取皮膚圖片的鏈接。每個英雄的皮膚不超過20個,以此來循環獲取拼接。(獲取的鏈接會有大量的沒有響應的鏈接)
def path_url(dict_js):
pic_list = []
for key in dict_js:
for i in range(20):
xuhao = str(i)
if len(xuhao) == 1:
num_houxu = "00" + xuhao
elif len(xuhao) == 2:
num_houxu = "0" + xuhao
numStr = key + num_houxu
url = r'http://ossweb-img.qq.com/images/lol/web201310/skin/big' + numStr + '.jpg'
pic_list.append(url)
print(pic_list)
return pic_list

鏈接獲取到之后,開始根據鏈接來下載皮膚
先生成文件的保存路徑
'''
根據字典的value值獲取英雄名字,將其作為文件名和保存路徑
'''
def name_pic(dict_js, path):
list_filePath = []
for name in dict_js.values():
for i in range(20):
file_path = path + name + str(i) + '.jpg'
list_filePath.append(file_path)
print(list_filePath)
return list_filePath

接下來就是下載圖片,將圖片寫入文件。(解決大量沒有響應的鏈接)還是通過requests的get方法獲取 響應,如果響應的text的內容是404,則結束本次循環,如果不是則將該圖片寫入文件保存。這樣就不會下載大量的不能打開的空圖片
def writing(url_list, list_filePath):
try:
for i in range(len(url_list)):
res = requests.get(url_list[i], verify=False)
if '404 page not found' in res.text:
print("該英雄皮膚下載完畢"), i
continue
with open(list_filePath[i], "wb") as f:
f.write(res.content)
except Exception as e:
print("下載圖片出錯,%s" % (e))
return False


獲取到996個皮膚
至此,皮膚獲取完畢。當然還可以優化,可以嘗試使用多線程改進該程序,圖片太多,單線程過慢。還有皮膚鏈接的生成問題,考慮是否有更好的解決辦法,不會去生成大量無用的鏈接。程序會去請求這些無用的鏈接,造成大量資源浪費。
關于Python3怎么爬取英雄聯盟所有英雄皮膚就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





