溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何使用scrapy-redis做簡單的分布式,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
每次項目重新啟動的時候不可能再去把相同的內容重新采集一次,所以增量爬取很重要
使用分布式scrapy-redis可以實現去重與增量爬取。因為這個庫可以通過redis實現去重與增量爬取,爬蟲停止以后下次運行會接著上次結束的節點繼續運行.
缺點是,Scrapy-Redis調度的任務是Request對象,里面信息量比較大(不僅包含url,還有callback函數、headers等信息),可能導致的結果就是會降低爬蟲速度、而且會占用Redis大量的存儲空間,所以如果要保證效率,那么就需要一定硬件水平。
總結一下:
1. Scrapy-Reids 就是將Scrapy原本在內存中處理的 調度(就是一個隊列Queue)、去重、這兩個操作通過Redis來實現
多個Scrapy在采集同一個站點時會使用相同的redis key(可以理解為隊列)添加Request 獲取Request 去重Request,這樣所有的spider不會進行重復采集。效率自然就嗖嗖的上去了。
3. Redis是原子性的,好處不言而喻(一個Request要么被處理 要么沒被處理,不存在第三可能)
建議大家去看看崔大大的博客,干貨很多。
然后就是安裝redis了,
安裝redis自行百度網上全是,或者點這里https://blog.csdn.net/zhao_5352269/article/details/86300221
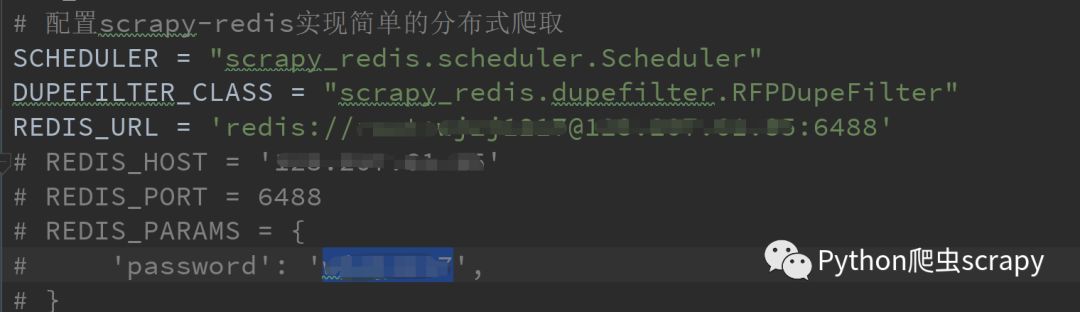
第二步就是setting.py 的配置
master的配置沒密碼的話去掉:后的
| # 配置scrapy-redis實現簡單的分布式爬取 |
| SCHEDULER = "scrapy_redis.scheduler.Scheduler" |
| DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" |
| REDIS_URL = 'redis://root:123456@192.168.114.130:6379' |
Slave的配置
| # 配置scrapy-redis實現簡單的分布式爬取 |
| SCHEDULER = "scrapy_redis.scheduler.Scheduler" |
| DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" |
| REDIS_HOST = '192.168.114.130' |
| REDIS_PORT = 6379 |
| REDIS_PARAMS = { |
| 'password': '123456', |
| } |
安裝scrapy-redis
pip3 install scrapy-reids
安裝完之后就可以實現簡單的分布式,兩個可以隨意啟動。
看完上述內容,你們掌握如何使用scrapy-redis做簡單的分布式的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





