溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Pig
一種操作hadoop的輕量級腳本語言,最初又雅虎公司推出,不過現在正在走下坡路了。當初雅虎自己慢慢退出pig的維護之后將它開源貢獻到開源社區由所有愛好者來維護。不過現在還是有些公司在用,不過我認為與其使用pig不如使用hive。:)
Pig是一種數據流語言,用來快速輕松的處理巨大的數據。
Pig包含兩個部分:Pig Interface,Pig Latin。
Pig可以非常方便的處理HDFS和HBase的數據,和Hive一樣,Pig可以非常高效的處理其需要做的,通過直接操作Pig查詢可以節省大量的勞動和時間。當你想在你的數據上做一些轉換,并且不想編寫MapReduce jobs就可以用Pig.
Hive
不想用程序語言開發MapReduce的朋友比如DB們,熟悉SQL的朋友可以使用Hive開離線的進行數據處理與分析工作。
注意Hive現在適合在離線下進行數據的操作,就是說不適合在掛在真實的生產環境中進行實時的在線查詢或操作,因為一個字“慢”。相反
起源于FaceBook,Hive在Hadoop中扮演數據倉庫的角色。建立在Hadoop集群的最頂層,對存儲在Hadoop群上的數據提供類SQL的接口進行操作。你可以用 HiveQL進行select,join,等等操作。
如果你有數據倉庫的需求并且你擅長寫SQL并且不想寫MapReduce jobs就可以用Hive代替。
HBase
HBase作為面向列的數據庫運行在HDFS之上,HDFS缺乏隨即讀寫操作,HBase正是為此而出現。HBase以Google BigTable為藍本,以鍵值對的形式存儲。項目的目標就是快速在主機內數十億行數據中定位所需的數據并訪問它。
HBase是一個數據庫,一個NoSql的數據庫,像其他數據庫一樣提供隨即讀寫功能,Hadoop不能滿足實時需要,HBase正可以滿足。如果你需要實時訪問一些數據,就把它存入HBase。
你可以用Hadoop作為靜態數據倉庫,HBase作為數據存儲,放那些進行一些操作會改變的數據。
Pig VS Hive
Hive更適合于數據倉庫的任務,Hive主要用于靜態的結構以及需要經常分析的工作。Hive與SQL相似促使 其成為Hadoop與其他BI工具結合的理想交集。
Pig賦予開發人員在大數據集領域更多的靈活性,并允許開發簡潔的腳本用于轉換數據流以便嵌入到較大的 應用程序。
Pig相比Hive相對輕量,它主要的優勢是相比于直接使用Hadoop Java APIs可大幅削減代碼量。正因為如此,Pig仍然是吸引大量的軟件開發人員。
Hive和Pig都可以與HBase組合使用,Hive和Pig還為HBase提供了高層語言支持,使得在HBase上進行數據統計處理變的非常簡單
Hive VS HBase
Hive是建立在Hadoop之上為了減少MapReduce jobs編寫工作的批處理系統,HBase是為了支持彌補Hadoop對實時操作的缺陷的項目 。
想象你在操作RMDB數據庫,如果是全表掃描,就用Hive+Hadoop,如果是索引訪問,就用HBase+Hadoop 。
Hive query就是MapReduce jobs可以從5分鐘到數小時不止,HBase是非常高效的,肯定比Hive高效的多。
介紹:
一、什么是hive???
1,hive是基于Hadoop的一個數據倉庫工具、
2,可以將結構化的數據文件映射為一張數據庫表,并提供類sql的查詢功能、
3,可以將sql語句轉換為mapreduce任務進行運行、
4,可以用來進行數據提取轉換加載(ETL)
5,hive是sql解析引擎,它將sql 語句轉換成M/R job然后在Hadoop中運行。
hive的表其實就是HDFS的目錄/文件夾。
hive表中的數據 就是hdfs目錄中的文件。按表名把文件夾分開。如果是分區表,則分區值是子文件夾,可以直接在M/R job里使用這些數據.
6,hive優點與缺點:
可以提供類SQL語句快速實現簡單的mapreduce統計,不需要開發專門的mapreduce應用
不支持實時查詢
7,hive數據分為真實存儲的數據和元數據
真實數據存儲在hdfs中,元數據存儲在mysql中
metastore 元數據存儲數據庫
Hive將元數據存儲在數據庫中,如MySQL、derby。
Hive中的元數據包括表的名字,表的列和分區及其屬性,表的屬性(是否為外部表等),表的數據所在目錄等。
二、hive的體系架構:
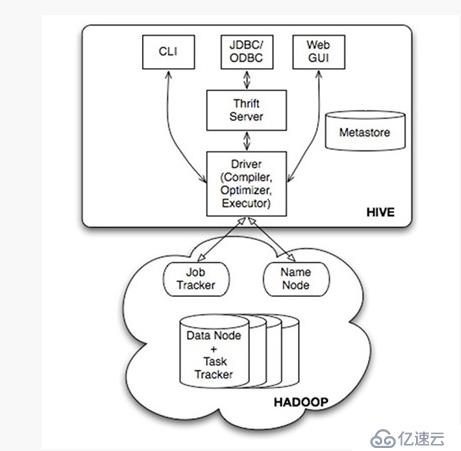
用戶接口,包括 CLI(shell),JDBC/ODBC,WebUI(通過瀏覽器)
元數據存儲,通常是存儲在關系數據庫如 mysql, derby 中
解釋器、編譯器、優化器、執行器完成HQL查詢語句從語法分析,編譯,優化以及查詢計劃的生成,生成的查詢計劃存儲在HDFS中,并隨后被mapreduce調用執行
Hadoop:用 HDFS 進行存儲,利用 MapReduce 進行計算 (帶 的查詢select from teacher不會生成mapreduce任務,只是進行全表掃描)
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





