溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“L1、L2正則化項及其在機器學習中怎么用”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“L1、L2正則化項及其在機器學習中怎么用”這篇文章吧。
在機器學習任務中,常用損失函數(loss function)來衡量模型輸出值和真實值Y之間的差異,如下面定義的損失函數: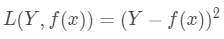 若數據
若數據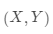 是服從聯合分布,則其損失函數的期望值為
是服從聯合分布,則其損失函數的期望值為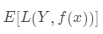 ,也稱為模型的真實風險,記作
,也稱為模型的真實風險,記作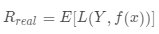 。我們的目標即是找到最優的模型或者概念來最小化真實風險,即:
。我們的目標即是找到最優的模型或者概念來最小化真實風險,即: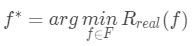 由于數據的分布是未知的,所以我們我們只能通過歷史數據訓練得到的模型在訓練集上的平均損失來代替這個真實風險,此時在訓練集上的平均損失稱為經驗風險(empirical risk),記作,其中
由于數據的分布是未知的,所以我們我們只能通過歷史數據訓練得到的模型在訓練集上的平均損失來代替這個真實風險,此時在訓練集上的平均損失稱為經驗風險(empirical risk),記作,其中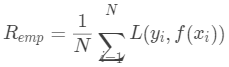 即我們的目標是通過訓練集上的數據最小化經驗風險以獲取最優模型或者最優概念:
即我們的目標是通過訓練集上的數據最小化經驗風險以獲取最優模型或者最優概念: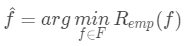
正則化項(regularization)也稱作懲罰項,常將其添加到損失函數中,用于組成我們的目標函數(object function)。正則化項的目的是為了對模型訓練的參數進行一些限制,常用的正則化項包括L1正則化,L2正則化,其分別常表示為和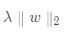 。其中,表示模型訓練的參數或者系數,則是求范數的計算操作。通常模型越復雜,懲罰項越大,模型越簡單,懲罰項越小。
。其中,表示模型訓練的參數或者系數,則是求范數的計算操作。通常模型越復雜,懲罰項越大,模型越簡單,懲罰項越小。
L1和L2的計算分別對應如下,其中表示調整的步長大小,其值越大,越會使得模型參數為0時取得最優解:
L1正則化表示權重向量中各個元素的絕對值之和。
L2正則化表示權重向量中各個元素的平方之和的平方根。
另外,除了L1和L2正則化項之外,還有L0正則化項,它的意義即是求非零參數的個數。
首先,關于L1和L2正則化的作用如下:
L1正則化可以產生稀疏解,即會使得很多參數的最優值變為0,以此得到的參數就是一個稀疏矩陣或者向量了。可以用于特征選擇。
L2正則化可以產生值很小的參數,即會使得很多參數的最優值很小。可以防止模型過擬合。
L1正則化可以得到稀疏解,所以可以用于模型特征選擇。以線性回歸的模型為例,很多特征的參數為0就意味著它們對于預測結果的貢獻為零,所以就可以保留不為零的特征,以此進行特征選擇。
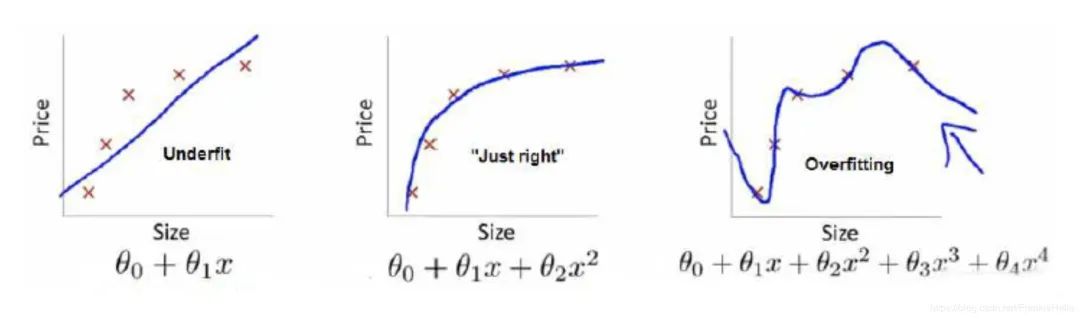
L2正則化可以防止模型過擬合,原因是在加入了L2正則化的目標函數中,參數優化的時會傾向于使得參數盡可能小,最后得到一個參數都比較小的模型。相比于參數很大的模型,樣本特征發生很小的變化就會導致模型的輸出發生很大的變化,如前面圖中的第三個模型,其中含有項,可想其對應的參數很大,其結果必然會有很大的變化。而如果參數很小,參數變化對于模型的輸出的影響就會很小,以此增強模型的泛化能力。
以上是“L1、L2正則化項及其在機器學習中怎么用”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





