溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹BiLSTM上的CRF層是如何工作,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
看了許多的CRF的介紹和講解,這個感覺是最清楚的,結合實際的應用場景,讓你了解CRF的用處和用法。
你需要知道的惟一的事情是什么是命名實體識別。如果你不知道神經網絡,CRF或任何其他相關知識,請不要擔心。我會盡可能直觀地解釋一切。
對于命名實體識別任務,基于神經網絡的方法非常普遍。我將以文中的模型為例來解釋CRF層是如何工作的。
如果你不知道BiLSTM和CRF的細節,請記住它們是命名實體識別模型中的兩個不同的層。
我們假設,我們有一個數據集,其中有兩個實體類型,Person和Organization。但是,事實上,在我們的數據集中,我們有5個實體標簽:
此外,x是一個包含5個單詞的句子,w0,w1,w2,w3,w4。更重要的是,在句子x中,[w0,w1]是一個Person實體,[w3]是一個Organization實體,其他都是“O”。
我將對這個模型做一個簡單的介紹。
如下圖所示:
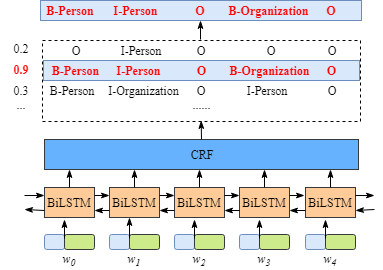
雖然不需要知道BiLSTM層的細節,但是為了更容易的理解CRF層,我們需要知道BiLSTM層輸出的意義是什么。
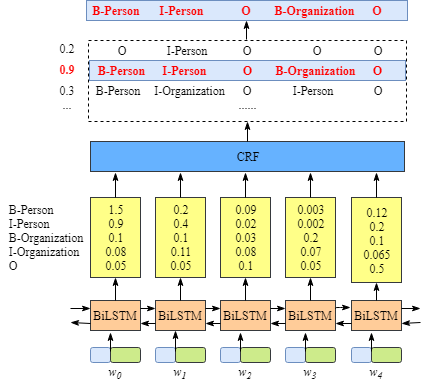
上圖說明BiLSTM層的輸出是每個標簽的分數。例如,對于w0, BiLSTM節點的輸出為1.5 (B-Person)、0.9 (I-Person)、0.1 (B-Organization)、0.08 (I-Organization)和0.05 (O),這些分數將作為CRF層的輸入。
然后,將BiLSTM層預測的所有分數輸入CRF層。在CRF層中,選擇預測得分最高的標簽序列作為最佳答案。
你可能已經發現,即使沒有CRF層,也就是說,我們可以訓練一個BiLSTM命名實體識別模型,如下圖所示。
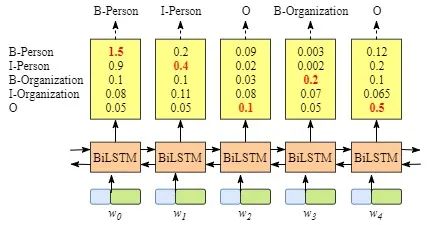
因為每個單詞的BiLSTM的輸出是標簽分數。我們可以選擇每個單詞得分最高的標簽。
例如,對于w0,“B-Person”得分最高(1.5),因此我們可以選擇“B-Person”作為其最佳預測標簽。同樣,我們可以為w1選擇“I-Person”,為w2選擇“O”,為w3選擇“B-Organization”,為w4選擇“O”。
雖然在這個例子中我們可以得到正確的句子x的標簽,但是并不總是這樣。再試一下下面圖片中的例子。
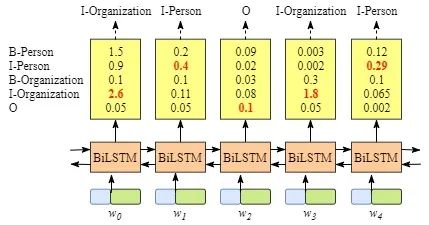
顯然,這次的輸出是無效的,“I-Organization I-Person”和“B-Organization I-Person”。
CRF層可以向最終的預測標簽添加一些約束,以確保它們是有效的。這些約束可以由CRF層在訓練過程中從訓練數據集自動學習。
約束條件可以是:
有了這些有用的約束,無效預測標簽序列的數量將顯著減少。
關于BiLSTM上的CRF層是如何工作就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





