溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“如何構建Uber的預警生態系統”,在日常操作中,相信很多人在如何構建Uber的預警生態系統問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”如何構建Uber的預警生態系統”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
Uber的軟件架構包含數千種微服務,這些微服務使團隊能夠快速迭代并支持我們公司的全球增長。這些微服務支持各種解決方案,例如移動應用程序,內部和基礎結構服務以及產品,以及會影響城市和郊區的這些產品的復雜配置。
為了維持我們的增長和架構,Uber的Observability團隊建立了一個強大的,可擴展的指標和警報管道,負責在服務出現問題時立即檢測,緩解并通知工程師。具體來說,我們構建了兩個數據中心警報系統,分別稱為uMonitor和Neris,它們流入同一通知和警報管道。uMonitor是我們基于指標的警報系統,它針對指標數據庫M3運行檢查,而Neris主要在主機級基礎架構中尋找警報。
Neris和uMonitor都利用公共管道發送通知和重復數據刪除。我們將深入研究這些系統,并討論如何采取更多的緩解措施,新的警報重復數據刪除平臺Origami,以及在創建高信噪比警報方面的挑戰。
此外,我們還開發了黑匣子警報系統,可以在內部系統出現故障或數據中心完全中斷的情況下檢測數據中心外部的高級別中斷。未來的博客文章將討論此設置。
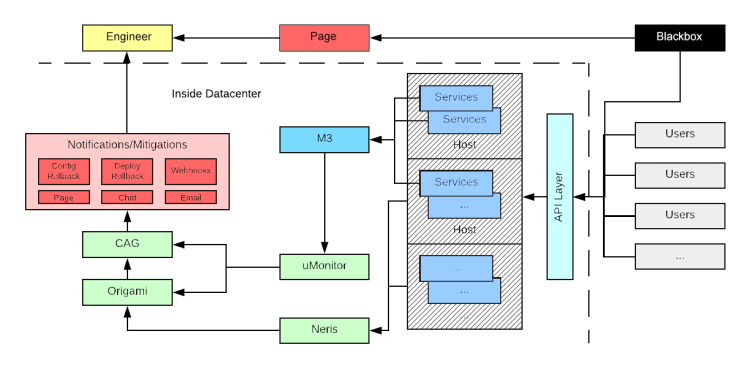
在我們的警報體系結構中,服務將指標發送到M3。uMonitor檢查M3是否存在基于指標的警報。主機檢查將發送到Neris進行匯總和警報。Blackbox從Uber外部測試API基礎結構。
在Uber的規模上,監視和警報需要在傳統的現成解決方案之外進行思考。Uber的警報始于Nagios,使用源代碼控制腳本針對指標發布Graphite閾值檢查。由于我們的Carbon指標集群存在可擴展性問題,我們決定構建自己的大型指標平臺M3。為了提高警報系統的可用性,我們開發了uMonitor,這是我們自己開發的基于時間序列指標的警報系統,用于存儲在M3中的指標。對于未存儲在M3中的指標,我們構建了Neris以執行主機級警報檢查。
uMonitor的構建考慮了靈活性和用例多樣性。某些警報是根據標準指標自動生成的,例如端點錯誤和CPU /內存消耗。其他警報由各個團隊創建,這些警報與特定于其需求的指標有關。我們將uMonitor構建為處理這些不同用例的平臺,特別是:
輕松管理警報:迭代確定警報的適當功能和閾值
靈活的操作:諸如尋呼,電子郵件和聊天之類的通知。支持自動緩解措施,例如回滾部署和配置更改
處理高基數:能夠在最小范圍內的關鍵問題上發出警報,但不能為團隊提供大量中斷通知
uMonitor具有三個獨立的組件:具有警報管理API并封裝我們的Cassandra警報和狀態存儲的存儲服務;以及調度程序,用于跟蹤所有警報,并為每個警報每分鐘將警報檢查任務分派給工作人員;以及根據警報定義的基礎指標執行警報檢查的工作人員。
工作人員在Cassandra存儲中維護警報檢查狀態,并確保通過主動重試機制至少發送一次通知。工人還負責每隔一段時間(通常每小時一次)重新發出警報,以繼續發出警報。目前,uMonitor具有125,000個警報配置,每秒可在140萬個時間序列中檢查7億個數據點。

警報定義具有M3查詢(Graphite或M3QL)和閾值,這些閾值確定警報是否違反閾值。查詢從M3返回一個或多個時間序列,并且將閾值應用于每個基礎序列。如果查詢違反閾值,則發送警報操作。工作人員在存儲在Cassandra中的狀態的幫助下維護著一個狀態機,該狀態機確保至少在觸發警報后發送通知,在觸發警報時定期重新發送,并在問題緩解后解決。
閾值有兩種類型:靜態閾值和異常閾值。對于具有特定穩態的指標,或者我們可以通過計算成功/失敗百分比等值來構造返回一致值的查詢,通常使用靜態閾值。對于諸如每個城市的旅行計數和其他業務指標之類的周期性指標,uMonitor利用我們的異常檢測平臺Argos來生成動態閾值,用于根據歷史數據來代表指標的異常值。
Neris是我們的基于主機的內部警報系統,旨在為我們的M3指標系統中不提供的高分辨率的每個主機高基數指標。主機指標不在M3中的原因有兩個。首先,檢查每個數據中心每40,000個主機每分鐘生成的150萬個主機指標中的每個指標,在主機上執行效率比在中央指標存儲中查詢要高。這樣,就不需要攝取和存儲指標的開銷。其次,直到最近,M3的保留策略導致10秒鐘的度量標準被存儲48小時,而一分鐘的度量標準被存儲30天,并且不需要使用該保留和解決方案來存儲主機度量標準。由于Nagios要求為每張支票編寫和部署代碼,但隨著我們基礎架構的增長而無法擴展,因此我們決定在內部構建一個系統。
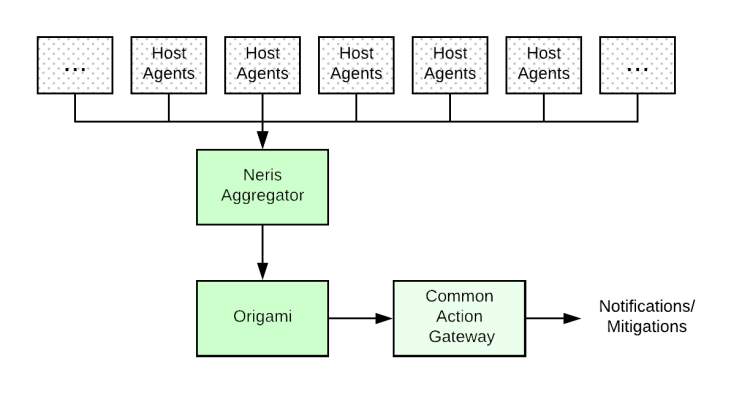
Neris的代理可在我們數據中心的每臺主機上運行,并定期(每分鐘)對主機本身執行警報檢查。然后,代理將檢查結果發送到聚合層,聚合層又將聚合結果發送到Origami。Origami負責根據查看失敗警報數量和基礎警報的嚴重性的規則來決定要發送什么警報。利用Origami,Neris在每個數據中心的主機主機中每分鐘運行約150萬個檢查。
在每臺主機上啟動代理時,Neris會從名為Object Config的中央配置存儲中提取主機的警報定義信息,該存儲被Uber的低級基礎架構服務廣泛使用。確定哪些警報將在給定主機上運行取決于其角色。例如,運行Cassandra的主機將進行與Cassandra的狀態,磁盤使用情況和其他指標有關的檢查。大多數此類主機級別檢查是由基礎架構平臺團隊創建和維護的。
高基數一直是我們警報平臺的最大挑戰。傳統上,這是通過使警報查詢返回多個序列并僅在序列的某個百分比以上違反閾值時才觸發警報周圍的簡單規則來處理的。uMonitor還允許用戶將警報設置為依賴于其他警報-跟蹤更大范圍問題的警報取決于更大范圍的警報,并且如果觸發更大范圍的警報,則從屬警報將被抑制。
只要查詢返回有限數量的序列,上述技術就可以很好地工作,并且可以輕松定義依賴項。但是,隨著Uber越來越多地在數百個城市中運營許多不同的產品線,基數挑戰已要求一種更通用的解決方案。我們使用Origami來協助處理高基數。Neris將Origami用作其主要的重復數據刪除和通知引擎,并啟用了uMonitor警報的合并通知。
對于業務指標,當我們需要針對每個城市,每個產品,每個應用版本發出警報時,Origami非常有用。Origami允許用戶為城市,產品和應用程序版本的組合創建基礎的警報/檢查,并在匯總策略上發出警報,以基于每個城市/產品/應用程序的版本接收通知。在停電較大的情況下(例如,當許多城市同時出現問題時),Origami將發送匯總通知,指示觸發的底層警報列表。
在主機警報方案中,Origami使我們能夠基于警報的匯總狀態發送各種嚴重性的通知。我們來看一個有關Cassandra群集上磁盤空間使用情況的示例。在這種情況下,對此的Origami通知政策可能類似于:
如果少于三臺的主機使用了70%的磁盤,則發送電子郵件通知
如果三個以上的主機有70%的磁盤使用率,則發送頁面
如果一個或多個主機磁盤使用率達到90%,則發送頁面
有用的警報通知是擴展警報系統的主要挑戰。警報操作主要從通知開始,例如針對高優先級問題呼叫工程師,以及針對信息性問題使用聊天或電子郵件。現在,我們的重點已轉向制定緩解措施。大多數事件和中斷都是由于配置更改或部署而發生的。uMonitor為緩解操作提供了一流的支持,這些操作可以回滾最近的配置更改和部署。對于具有更復雜的緩解運行手冊的團隊,我們支持webhooks,這些Webhooks可針對具有警報完整上下文的端點進行POST調用,從而可以運行緩解運行手冊。此外,通過利用Origami中的重復數據刪除管道,我們可以在發生較大故障時抑制更精細的粒度通知。
除上述內容外,我們一直在努力使通知更加相關,并使通知針對合適的個人。最近的工作涉及識別配置/部署變更所有者,并在警報觸發他們已修改的服務時觸發他們。通過結合來自Jaeger的跟蹤信息和警報信息,我們在圍繞相關服務故障的警報通知中提供更多上下文方面做出了額外的努力。
如前所述,我們一直致力于將uMonitor構建為其他團隊可以針對特定用例建立的平臺。主機警報的設置和管理通常是專門的,主要用于維護自己專用硬件的團隊,以及正在為公司構建基礎架構平臺(包括存儲,指標和計算解決方案)的團隊。警報是在團隊的單獨git存儲庫中配置的,這些存儲庫已同步到Object Config。
從較高的角度來看,uMonitor具有三類警報:
根據所有服務的CPU,磁盤使用率和RPC統計信息的標準指標自動生成警報
通過UI創建的一次性警報以檢測特定問題
通過uMonitor之上的腳本和外部配置系統創建和管理警報
隨著團隊努力以可能的最佳粒度檢測可警報的問題,我們在最后一類警報中看到了最大的增長。對這種粒度的需求歸結于Uber的全球增長。支持Uber移動應用程序的服務的代碼更改通常會在幾個小時內推廣到特定的城市群體。我們非常重要的一點是,我們必須在城市一級監視平臺的運行狀況,以便在問題廣泛傳播之前找出問題所在。此外,每個城市的工程和本地操作團隊控制的配置參數也不同。例如,由于游行等正在進行的事件,城市中的騎手接送可能會被阻塞在街道上,或者其他事件可能會導致交通變化。
許多團隊已經在uMonitor上構建了警報生成解決方案來解決此類用例。這些工具解決的一些挑戰是:
遍歷各個維度迭代并生成警報
根據特定的業務信息(例如特定國家/城市的假期)確定警報時間表,并在uMonitor中配置該信息以防止虛假警報
如果靜態或當前異常閾值不起作用,請基于過去的數據或對適用于特定業務線的基礎指標的復雜查詢來確定閾值(更多有關以下警報查詢)
此外,這些解決方案中的許多解決方案都會生成與所生成的警報同步的儀表板。
uMonitor還提供了功能強大的編輯和根本原因UI。UI的編輯和實驗方面至關重要,因為由于變化和峰值,大多數指標無法按原樣用于警報。可觀察性團隊為如何創建更適合警報的查詢提供了指導。
Graphite查詢語言和M3QL提供了大量功能,可提供更多定制解決方案。下面,我們概述了一些示例,這些示例說明了如何使查詢返回更一致的值以使指標更易于警惕:
提醒您說幾分鐘內移動指標的平均值,以消除指標的任何峰值
將以上內容與維持期結合使用,僅在閾值違例持續了一定時間后才發送通知
對于具有上下模式的指標,請使用導數函數以確保任一方向的峰值都不會太突然
發出百分比/比率警報,以使度量標準不易受到度量標準大小變化的影響
到此,關于“如何構建Uber的預警生態系統”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





