溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Flink Table的三種Sink模式分別是什么,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
作為計算引擎 Flink 應用的計算結果總要以某種方式輸出,比如調試階段的打印到控制臺或者生產階段的寫到數據庫。而對于本來就需要在 Flink 內存保存中間及最終計算結果的應用來說,比如進行聚合統計的應用,輸出結果便是將內存中的結果同步到外部。就 Flink Table/SQL API 而言,這里的同步會有三種模式,分別是 Append、Upsert 和 Retract。實際上這些輸出計算結果的模式并不限于某個計算框架,比如 Storm、Spark 或者 Flink DataStream 都可以應用這些模式,不過 Flink Table/SQL 已有完整的概念和內置實現,更方便討論。
相信接觸過 Streaming SQL 的同學都有了解或者聽過流表二象性,簡單來說流和表是同一事實的不同表現,是可以相互轉換的。流和表的表述在業界不盡相同,筆者比較喜歡的一種是: 流體現事實在時間維度上的變化,而表則體現事實在某個時間點的視圖。如果將流比作水管中流動的水,那么表將是杯子里靜止的水。
將流轉換為表的方法對于大多數讀者都不陌生,只需將聚合統計函數應用到流上,流很自然就變為表(值得注意的是,Flink 的 Dynamic Table 和表的定義有細微不同,這將在下文講述)。比如對于一個計算 PV 的簡單流計算作業,將用戶瀏覽日志數據流安 url 分類統計,變成 (url, views) 這樣的一個表。然而對于如何將表轉換成流,讀者則未必有這么清晰的概念。
假設一個典型的實時流計算應用的工作流程可以被簡化為下圖:
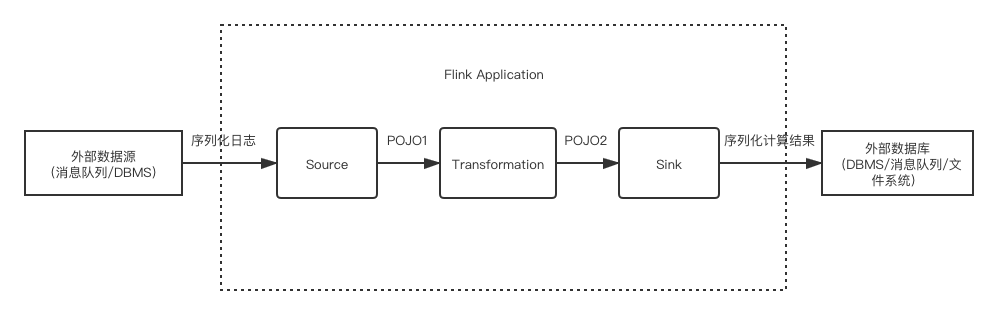
其中很關鍵的一點是 Transformation 是否聚合類型的計算。若否,則輸出結果依然是流,可以很自然地使用原本流處理的 Sink(與外部系統的連接器);若是,則流會轉換為表,那么輸出的結果將是表,而一個表的輸出通常是批處理的概念,不能直接簡單地用流處理的 Sink 來表達。
這時有個很樸素的想法是,我們能不能避免批處理那種全量的輸出,每次只輸出表的 diff,也就是 changelog。這也是表轉化為流的方法: 持續觀察表的變化,并將每個變化記錄成日志輸出。因此,流和表的轉換可以以下圖表示:
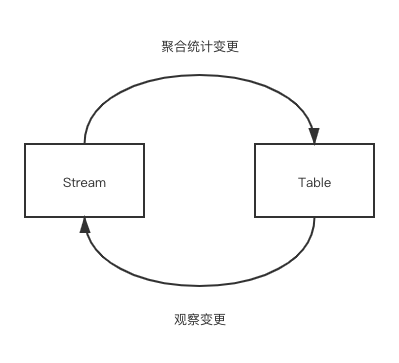
其中表的變化具體可以分為 INSERT、UPDATE 和 DELETE 三類,而 Flink 根據這些變化類型分別總結了三種結果的輸出模式。
| 模式 | INSERT | UPDATE | DELETE |
|---|---|---|---|
| Append | 支持 | 不支持 | 不支持 |
| Upsert | 支持 | 支持 | 支持 |
| Retract | 支持 | 支持 | 支持 |
通常來說 Append 是最容易實現但功能最弱的,Retract 是最難實現而功能最強的。下文分別談談三種模式的特點和應用場景。
Append 是最為簡單的輸出模式,只支持追加結果記錄的操作。因為結果一旦輸出以后便不會再有變更,Append 輸出模式的最大特性是不可變性(immutability),而不可變性最令人向往的優勢便是安全,比如線程安全或者 Event Sourcing 的可恢復性,不過同時也會給業務操作帶來限制。通常來說,Append 模式會用于寫入不方便做撤回或者刪除操作的存儲系統的場景,比如 Kafka 等 MQ 或者打印到控制臺。
在實時聚合統計中,聚合統計的結果輸出是由 Trigger 決定的,而 Append-Only 則意味著對于每個窗口實例(Pane,窗格)Trigger 只能觸發一次,則就導致無法在遲到數據到達時再刷新結果。通常來說,我們可以給 Watermark 設置一個較大的延遲容忍閾值來避免這種刷新(再有遲到數據則丟棄),但代價是卻會引入較大的延遲。
不過對于不涉及聚合的 Table 來說,Append 輸出模式是非常好用的,因為這類 Table 只是將數據流的記錄按時間順序排在一起,每條記錄間的計算都是獨立的。值得注意的是,從 DataFlow Model 的角度來看未做聚合操作的流不應當稱為表,但是在 Flink 的概念里所有的流都可以稱為 Dynamic Table。筆者認為這個設計也有一定的道理,原因是從流中截取一段出來依然可以滿足表的定義,即”某個時間點的視圖”,而且我們可以爭辯說不聚合也是一種聚合函數。
Upsert 是 Append 模式的升級版,支持 Append-Only 的操作和在有主鍵的前提下的 UPDATE 和 DELETE 操作。Upsert 模式依賴業務主鍵來實現輸出結果的更新和刪除,因此非常適合 KV 數據庫,比如
HBase、JDBC 的 TableSink 都使用了這種方式。
在底層,Upsert 模式下的結果更新會被翻譯為 (Boolean, ROW) 的二元組。其中第一個元素表示操作類型,true 對應 UPSERT 操作(不存在該元素則 INSERT,存在則 UPDATE),false 對應 DELETE 操作,第二個元素則是操作對應的記錄。如果結果表本身是 Append-Only 的,第一個元素會全部為 true,而且也無需提供業務主鍵。
Upsert 模式是目前來說比較實用的模式,因為大部分業務都會提供原子或復合類型的主鍵,而在支持 KV 的存儲系統也非常多,但要注意的是不要變更主鍵,具體原因會在下一節談到。
Retract 是三種輸出模式中功能最強大但實現也最復雜的一種,它要求目標存儲系統可以追蹤每個條記錄,而且這些記錄至少在一定時間內都是可以撤回的,因此通常來說它會自帶系統主鍵,不必依賴于業務主鍵。然而由于大數據存儲系統很少有可以精確到一條記錄的更新操作,因此目前來說至少在 Flink 原生的 TableSink 中還沒有能在生產環境中滿足這個要求的。
不同于 Upsert 模式更新時會將整條記錄重新輸出,Retract 模式會將更新分成兩條表示增減量的消息,一條是 (false, OldRow) 的撤回(Retract)操作,一條是 (true, NewRow) 的積累(Accumulate)操作。這樣的好處是,在主鍵出現變化的情況下,Upsert 輸出模式無法撤回舊主鍵的記錄,導致數據不準確,而 Retract 模式則不存在這個問題。
舉個例子,假設我們將電商訂單按照承運快遞公司進行分類計數,有如下的結果表。
那么如果原本一單為中通的快遞,后續更新為用順豐發貨,對于 Upsert 模式會產生 (true, (順豐, 4)) 這樣一條 changelog,但中通的訂單數沒有被修正。相比之下,Retract 模式產出 (false, (中通, 1)) 和 (true, (順豐, 1)) 兩條數據,則可以正確地更新數據。
Flink Table Sink 的三種模式本質上是如何監控結果表并產生 changelog,這可以應用于所有需要將表轉為流的場景,包括同一個 Flink 應用的不同表間的聯動。三種模式中 Append 模式只支持表的 INSERT,最為簡單;Upsert 模式依賴業務主鍵提供 INSERT、UPDATE 和 DELETE 全部三類變更,比較實用;Retract 模式同樣支持三類變更且不要求業務主鍵,但會將 UPDATE 翻譯為舊數據的撤回和新數據的累加,實現上比較復雜。
看完上述內容,你們掌握Flink Table的三種Sink模式分別是什么的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





