溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Data Lake架構是怎么樣的,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
為在組織的數據環境中創造最大價值,傳統的決策支持系統架構難以滿足該需求。需要開發新的架構模式以釋放數據的價值。為了充分利用大數據的價值,組織需要擁有靈活的數據架構,并能夠從其數據生態系統中獲取最大價值。
Data Lake概念已經存在了一段時間。但是,我還是看到很多組織結構很難理解這個概念,因為他們對其的理解仍然禁錮在傳統的企業數據倉庫范式中。
本文將深入研究Data Lake架構模式的概念并設計一個架構模式。
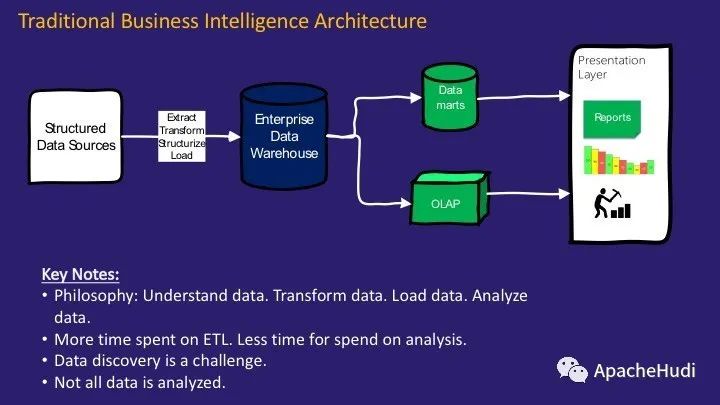
傳統的企業DWH架構模式已經使用了很多年。包括數據源、數據提取、轉換和加載(ETL),并且在此過程中,會進行某種結構的創建,清理等。在EDW中需要預先定義數據模型(尺寸模型或3NF模型),然后創建數據集市,以用于OLAP多維數據分析以及自助式BI。
這種架構已經服務了很多年。
但是,這種架構存在一些固有的挑戰,并且在大數據時代無法解決。其中一些如下:
這種架構需要我們先了解數據。源系統的數據結構是什么,它擁有什么樣的數據,基數是什么,應該如何根據業務需求對其進行建模,數據中是否存在異常等等?這是一項繁瑣而復雜的工作,進行需求分析或數據分析都需要花費數月時間。并且項目期限往往需要幾個月甚至幾年。
我們還必須對要存儲的數據和要丟棄的數據做出選擇和權衡。前期花費大量時間來決定引入什么,如何引入,如何存儲,如何轉換等。只有較少的時間花費在實際執行數據發現,數據挖掘以及增值業務上。
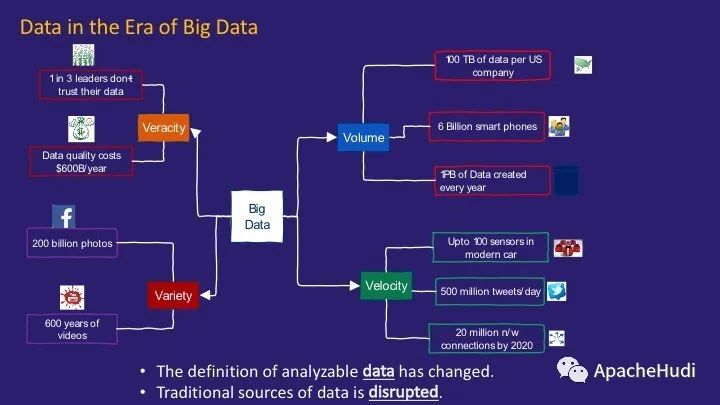
現在讓我們簡要地討論一下對數據定義是如何變化的。大數據的4V已經眾所周知,即Volume,Velocity,Variety和veracity。其背景如下:
自iPhone革命以來,數據量激增。全球有60億部智能手機,每天創建近1PB的數據。
數據不僅僅是靜止的。有流數據,支持IoT的設備。
還與數據的多樣性有關。視頻,照片都成為需要分析和利用的數據。
數據的爆炸式增長對數據質量也帶來了挑戰。在大數據時代,哪一個應該被信任而哪個不應該被信任是一個更大的挑戰。
簡而言之,可分析的數據定義在變化。現在不僅是結構化的數據,還包括各種非結構化數據。面臨的挑戰是如何將這些數據融合在一起并使得它們變得更有意義。
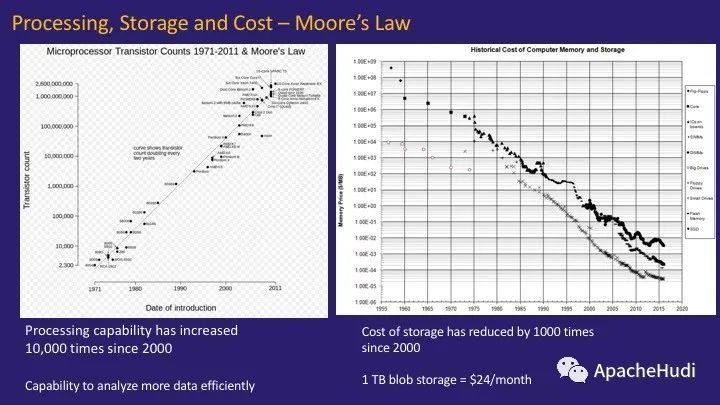
自2000年以來,處理能力,存儲和相應的成本結構發生了巨大變化,它受到了摩爾定律的約束。關鍵點如下:
自2000年以來,處理能力提高了約10,000倍。這意味著有效分析更多數據的能力得到了提高。
存儲成本下降了很多。自2000年以來,存儲成本下降了1000倍以上。

用一個類比來解釋Data Lake的概念。
游覽大湖總是一種非常愉快的感覺。湖中的水以其最純凈的形式存在,不同的人在湖上進行不同的活動。有些人在釣魚,有些人喜歡乘船游覽,這個湖還為生活在安大略省的人們提供飲用水。簡而言之,同一個湖有多種用途。
隨著數據范例的變化,出現了一種新的架構模式。它被稱為數據湖架構。就像湖中的水一樣,數據湖中的數據也采用最原始的形式存放。就像湖泊一樣,它滿足了不同人的需要,那些想要釣魚的人或者想要乘船游覽的人,或者想要從湖中喝水的人,一個數據湖架構都可以滿足。它為數據科學家提供了探索數據和創建假設的途徑。它為業務用戶提供了探索數據的途徑。它為數據分析人員提供了分析數據和尋找模式的途徑。它為報告分析師提供了創建報告并呈現給利益相關者的途徑。
數據湖與數據倉庫或數據集市進行如下比較:
Data Lake以最原始的形式存儲數據,可以滿足多個利益相關者的需求,也可以用于打包數據,以供最終用戶使用。另一方面,數據倉庫是已經經過蒸餾和包裝(礦泉水)以用于特定目的數據存儲。
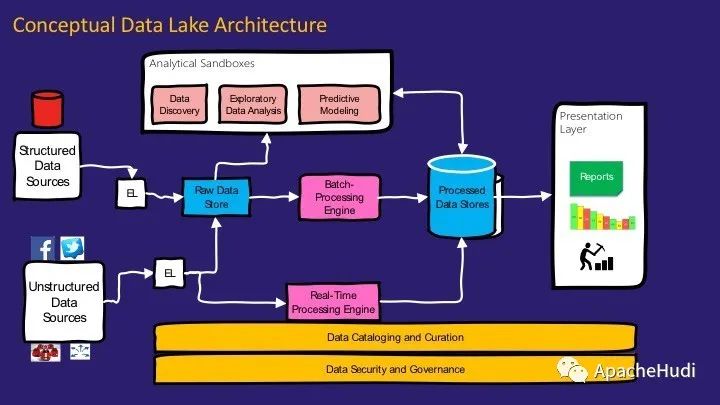
通過前面的背景介紹,現在讓我們了解數據湖的概念體系結構。數據湖體系結構中的關鍵組件有可以結構化和非結構化的數據源,它們都集成到原始數據存儲中,以最原始的方式存放數據,即不進行任何轉換。它是一種廉價的持久性存儲,可以大規模存儲數據。然后,我們使用分析沙箱來理解數據、創建原型、進行數據科學并探索數據以建立新的假設和用例。
然后我們有了批處理引擎,該引擎將原始數據處理成可被用戶直接使用的數據,即可以用于向最終用戶出報告的數據結構。我們稱其為已處理數據存儲。有一個實時處理引擎,可以獲取流數據并對其進行處理。此體系結構中的所有數據均已分類并整理。
下面讓我們了解此體系結構中的每個組件組。
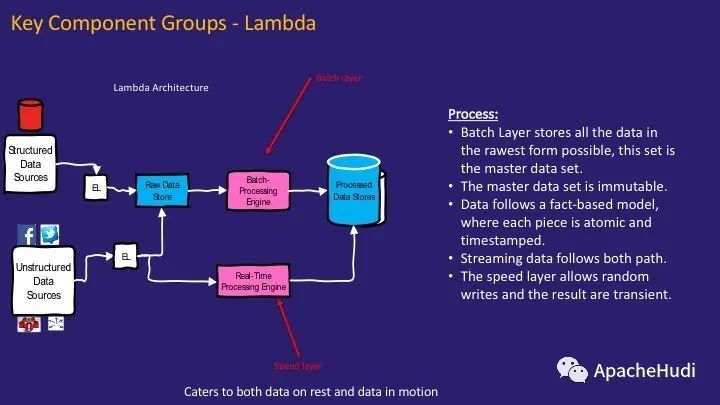
第一個組件組用于處理數據。它遵循Lambda架構,一般Lambda架構會采用兩條處理路徑:批處理層和實時處理層。批處理層以可能的最原始形式存儲數據,即原始數據存儲和實時處理層幾乎實時地處理數據。實時處理層將數據存儲到原始數據存儲中,并且可以在加載到已處理的數據存儲之前存儲瞬態數據。
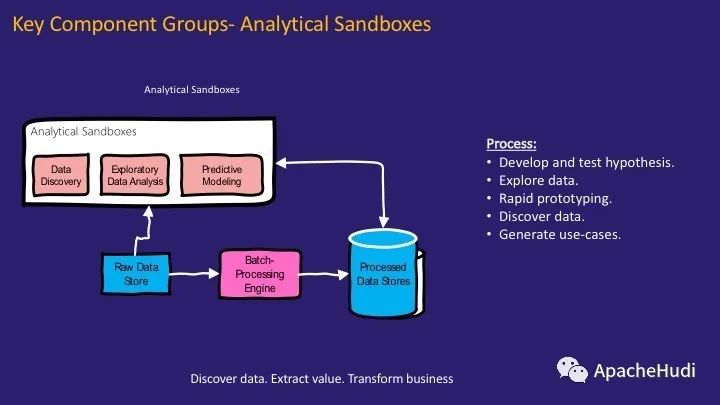
分析沙箱是數據湖架構中的關鍵組件之一。這些是數據科學家的探索性領域,他們可以在其中開發和測試新的假設、合并和探索數據以形成新的用例,創建快速的原型以驗證這些用例并意識到可以采取哪些措施從中提取價值。
簡單來說,它是數據科學家可以發現數據,提取價值并幫助轉變業務的地方。
數據編錄在傳統商業架構中經常被忽略。在大數據領域,編錄是非常重要的方面。讓我們舉個例子來說明它的重要性。
當我要求我的客戶在不提供編錄信息的情況下猜測這幅畫的潛在成本時,答案從100美元到100,000美元不等。當我提供目錄信息時,答案更接近于實際情況。順便說一句,這幅畫被巴勃羅·畢加索(Pablo Picasso)稱為“舊吉他手”,創作于1903年。估計造價超過1億美元。
數據編錄非常相似。不同的數據塊具有不同的值,并且該值根據數據的沿襲(lineage)、數據的質量、·創建的來源等而變化。需要對數據進行分類,以便數據分析師或數據科學家可以自己決定指向哪個數據用于特定分析。
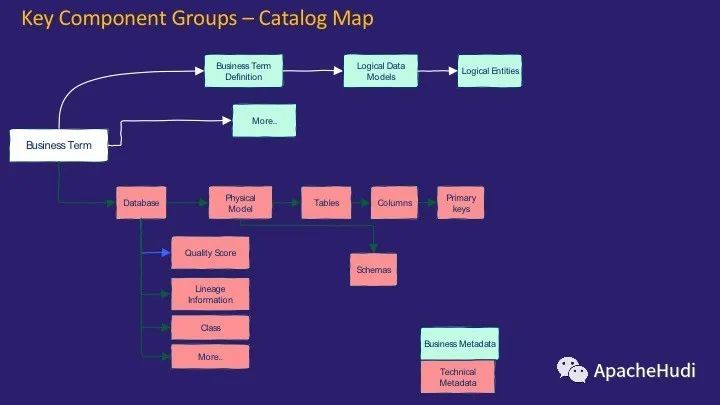
編錄圖提供了可以分類的元數據。編錄是捕獲有價值的元數據的過程,因此可以將其用于確定數據的特征并決定是否使用它。基本上有兩種類型的元數據:業務元數據和技術元數據。業務元數據更多地與定義、邏輯數據模型、邏輯實體等有關;而技術元數據則是捕獲與數據結構的物理實現有關的元數據。它包括數據庫、質量得分、列、架構等。
根據編錄信息,分析人員可以選擇在正確的上下文中使用特定的數據點。舉個例子,想象一下,數據科學家想要對庫存周轉率及其在ERP和庫存系統中的定義方式進行探索性分析。如果對術語進行了分類,則數據科學家可以根據上下文決定使用來自ERP還是清單系統中的列。
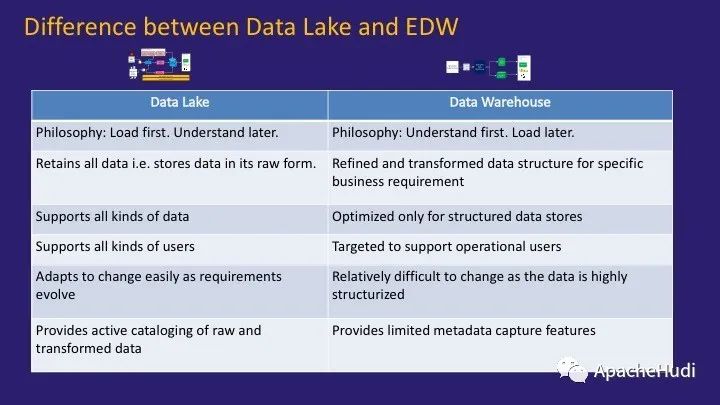
上圖表格試圖解釋差異
首先,哲學不同。在數據湖體系結構中,我們首先要原始加載數據,然后決定應如何處理。在傳統的DWH體系結構中,我們必須首先了解數據,對其進行建模,然后再將其加載。
數據湖中的數據以原始格式存儲,而DWH中的數據以結構化格式存儲,類比湖水和蒸餾水。
Data Lake支持各種用戶。
分析項目確實是敏捷項目。這些項目的本質是,一旦你看到輸出,便會思考更多并想要更多。Data Lake本質上是敏捷的。由于他們將所有數據存儲在編錄中,因此可以確保在出現新需求時可以輕松地進行調整。
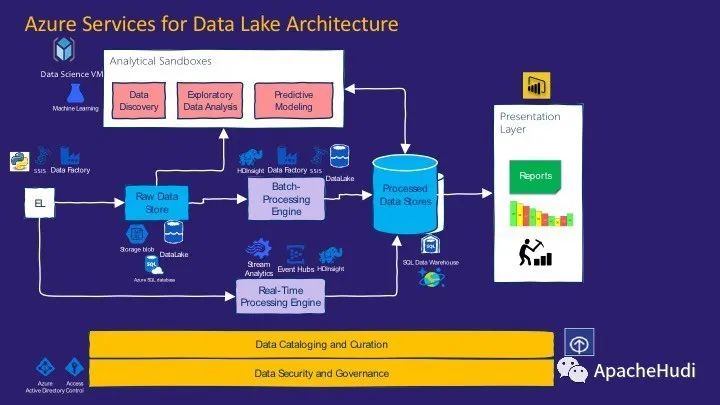
云平臺最適合實施數據湖架構.它們具有大量可組合的服務,可以將它們組合在一起以實現所需的可伸縮性。微軟的Cortana Intelligence Suite提供了一個或多個組件,可以將其映射為實現數據湖架構的組件。
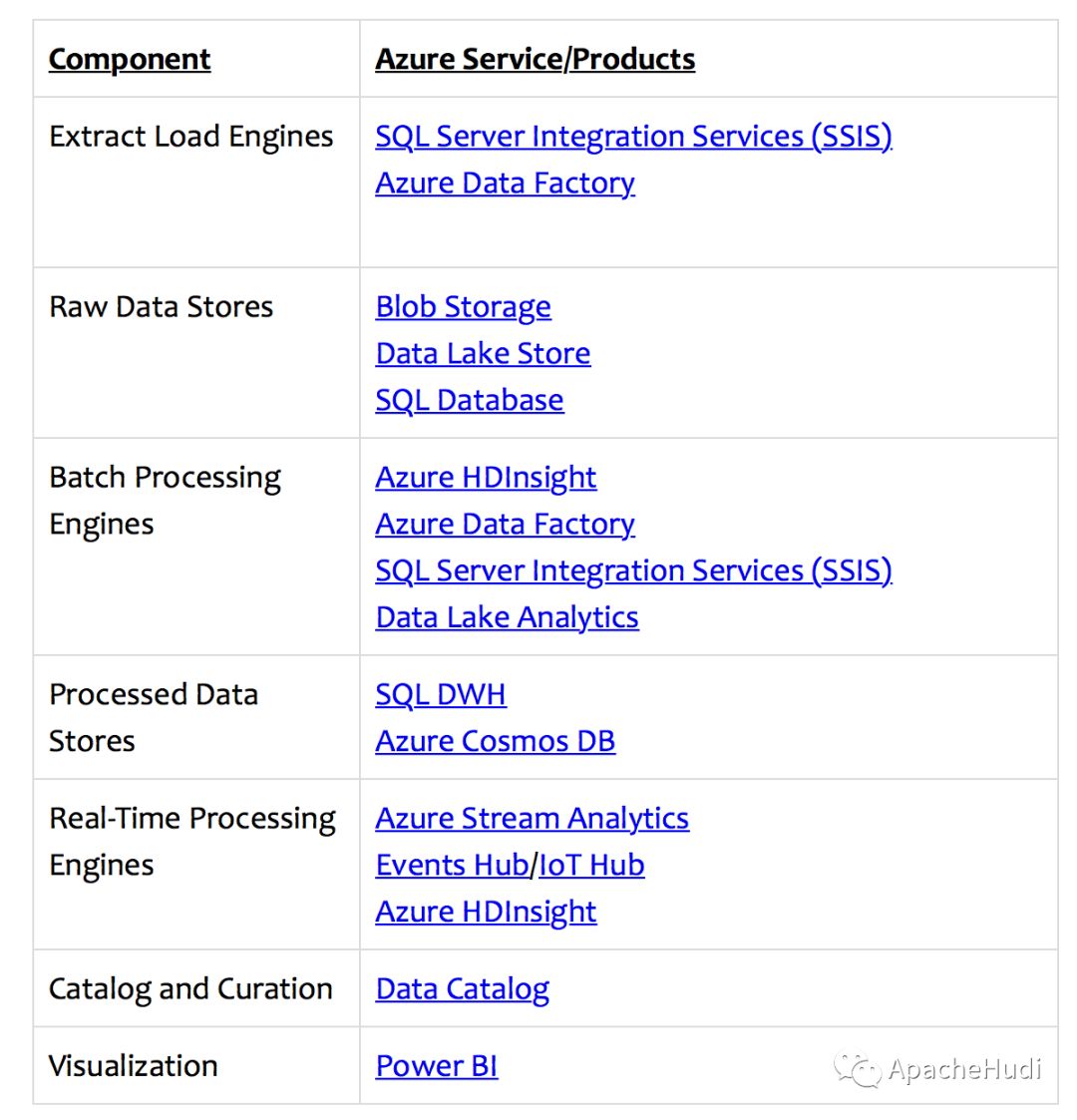
數據湖是大數據架構的新范式。
數據湖可以滿足各種數據的需求。以原始格式存儲數據,可以滿足用戶的廣泛需求,并能提供更快的洞察力。
細致的數據編錄和管理是成功實施數據湖的關鍵。
云平臺為實施經濟、可擴展的數據湖架構提供了端到端的端解決方案。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





