溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
TXT文本文件是我們常用的在應用之間傳遞數據的途徑之一,因為它具有通用、靈活、易維護等諸多優點。不過并不是所有應用都提供了生成txt文件的功能,往往需要額外的程序設計和開發工作才能獲得。這時如果能夠有一個通用的工具軟件,靈活地根據需要生成目標格式的文本,將能夠極大地助力我們的業務工作。本文介紹的集算器就正是這樣一款高效、靈活的通用工具軟件,能夠從不同數據源讀取、計算并導出txt文件。
本文將著重介紹集算器的數據導出能力,而集算器本身強大的計算能力不是本文重點,因此文中沒有刻意介紹數據源訪問和計算過程。文中用到的函數請參看集算器在線文檔《函數參考》。
我們首先從簡單的數據導出開始介紹:
下面這個例子中,通過兩行簡單讀入和輸出,完成了從數據源到TXT文件的導出。
A1單元格讀入excel文件中的5年1班學生成績,用來模擬可能通過計算得到的數據。
A2中的表達式將A1的數據導出到一個新的 “學生成績表.txt”文件中。例子中使用了導出函數export。不過在這個最簡單的例子中,我們沒有指定額外的參數。由于沒有指定x和F,因此將導出A1中的所有字段,同時保持字段名不變。由于沒有指定列分隔符參數s,所以會用默認的tab分隔。不過函數使用了選項@t,因此會將字段名(excel文件的標題行)導出到第一行。
A | |
1 | =file("51.xlsx").xlsimport@t() |
2 | =file( "學生成績表.txt" ).export@t(A1) |
下圖中就是導出的txt文件:
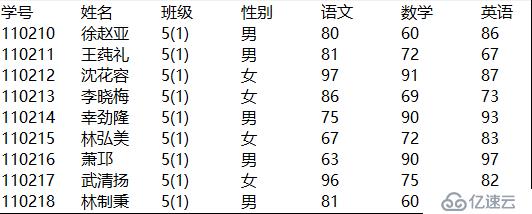
假如“學生成績表.txt”文件已經存在,我們需要在文件中再增加另一個班的成績,那么應該怎么做呢?
與上例類似,在A1中讀入要追加的5年2班的學生成績,數據結構保持相同
A2中把數據導出到已有的“學生成績表.txt”文件中,不過這時因為文件中已有標題,只需導出數據,因此不要加函數選項@t。同時,通過選項@a指明追加數據。
A | |
1 | =file("52.xlsx").xlsimport@t() |
2 | =file( "學生成績表.txt" ).export@a(A1) |
csv文件也是常見的純文本文件,其中存儲的表格數據以逗號分隔。如果要導出csv文件,有兩種方式:
l 在導出時象下圖那樣加選項@c,或者
l 增加分隔參數,寫成export@t(A1;",")
兩種方式結果都是一樣的。
A | |
1 | =file("51.xlsx").xlsimport@t() |
2 | =file( "學生成績表.txt" ).export@tc(A1) |
導出結果如下:
學號,姓名,班級,性別,語文,數學,英語
110210,徐趙亞,5(1),男,80,60,86
110211,王莼禮,5(1),男,81,72,67
110212,沈花容,5(1),女,97,91,87
110213,李曉梅,5(1),女,86,69,73
現在,我們看一下略為復雜的導出操作:
在上面的例子中我們引入一些新的需求:
l 在結果文件中增加一個序號列
l 在最后增加一個平均成績列,并對平均成績進行格式化保留一位小數
l 不導出學號
l 列間分隔符采用“\t| ”。
A | |
1 | =file("51.xlsx").xlsimport@t() |
2 | =file( "學生成績表.txt" ).export@t(A1,#: 序號, 姓名, 班級, 性別, 語文, 數學, 英語,string(( 語文 + 數學 + 英語)/3,"#.0"): 平均;"\t| ") |
導出結果如下圖所示:
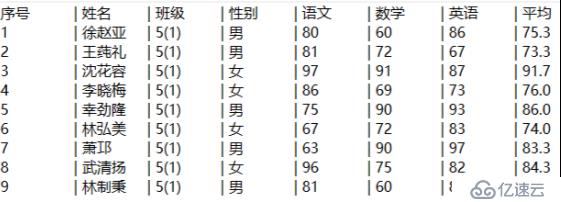
還是兩行搞定!A1不用再說了,我們來看看A2的變化:#號在序表中表示記錄編號,將它導出為結果中的序號列;指明導出姓名、班級、性別、語文、數學、英語列;表達式“string((語文 + 數學 + 英語 )/3,"#.0"): 平均”中,求出語文、數學、英語的平均數并格式化成只保留一位小數,命名導出的新列名為“平均”;最后一個參數指定列間分隔符為“\t| ”。
數據導出時還常常要面臨另一個重要問題:如果數據量很大時又該怎么辦?
為此,可以利用集算器提供的游標功能來處理大數據量的情況,游標在讀取數據時從前向后遍歷一次,逐條從數據源讀取數據,而不是一次將所有數據讀入內存,因此不會受到內存不足的限制。而且,集算器游標不僅可以應用于數據庫,還可以應用于數據文件或者內存排列。
腳本如下圖所示:
A | |
1 | =connect("demo") |
2 | =A1.cursor("select * from 訂單表") |
3 | >n=0 |
4 | =file("big.txt").export@t(A2,n=n+1:序號, 訂單 ID, 公司名稱, 貨主地區, 訂購日期,string(訂單金額,"#.00"): 訂單金額 ) |
導出結果如下:
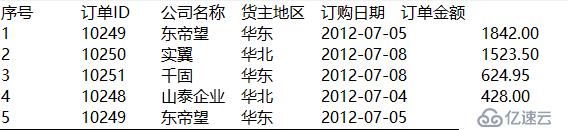
A1連接demo數據庫
A2打開訂單表作為游標
A3定義序號變量n,賦初值為0
A4是具體的導出過程,將游標所指的大數據導出到big.txt文件中。
對于大數據量的情況我們把游標作為導出數據源,而在前面的普通導出情況下則是把序表作為導出數據源。除了游標中不能以#代表記錄號自動產生序號以外,兩者用法完全相同。
為了產生序號,導出時利用A3中定義的變量n,在每導出一條數據時加1后導出為序號列即可。
最后,我們來看一個真正實戰的例子:
當今企業給員工發工資一般都通過銀行代發的方式。銀行都提供了網上服務,企業可以通過這個途徑來完成自助工資發放,具體的做法是:
銀行提供了一個代發工資的文本文件格式,企業用戶只要按格式編寫此文件,再通過網上銀行上載此文件,就可以完成工資發放。
下面我們就來看看如何利用集算器方便地完成代發工資文本文件的生成。
我們以民生銀行為例,其文件格式如下:
ATNU:0019999
MICN:
CUNM:北京 XXXX 技術有限公司
MIAC:0110014180030254
EYMD:1
TOAM:80576.39
COUT:5
---------------------------------------
6226220101871111|19944.65|趙愛潤 ||
6226220101872222|18349.08|孫學乾 ||
6226220101873333|15955.72|王老集 ||
6226220101874444|14360.15|張小算 ||
6226220101875555|11966.79|李大器 ||
此文件前 8 行是文件頭,第 1、2、5、8 行內容固定不變,第 3 行是企業名稱,第 4 行是企業在民生銀行的賬號,第 6 行是本次發工資的總金額,第 7 行是發工資的總筆數。從第 9 行開始是具體的工資信息,第一項是員工工資賬號,第二項是工資金額,第三項是員工姓名,第四、五項空著不填就行。各項之間用豎線分隔。
此文本文件的格式要求非常嚴格,不能出錯,因此不適合財務人員直接編輯,需要通過程序生成。
企業與工資相關的有兩個 excel 表,一個是員工表,另一個是工資表,如下兩圖所示。
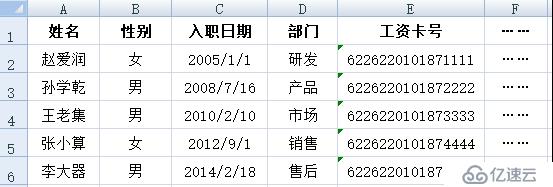
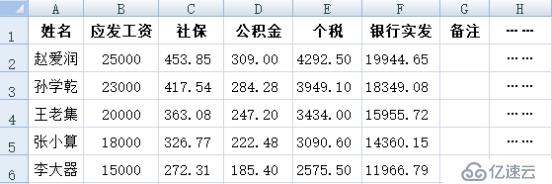
賬務人員負責填好員工工資表后,就可以打開集算器 ide,運行預先編寫好的 dfx 程序了:
A | B | |
1 | =file("員工表.xlsx").xlsimport@t() | =file("工資表.xlsx").xlsimport@t() |
2 | =A1.join(姓名,B1: 姓名, 銀行實發, 備注 ) | |
3 | =file("發工資.txt") | |
4 | =A3.write("ATNU:0019999") | =A3.write@a("MICN:") |
5 | =A3.write@a("CUNM:北京 XXXX 技術有限公司 ") | =A3.write@a("MIAC:0110014180030254") |
6 | =A3.write@a("EYMD:1") | =A3.write@a("TOAM:"+string(A2.sum(銀行實發 ),"#.00")) |
7 | =A3.write@a("COUT:"+string(A2.count())) | =A3.write@a("---------------------------------------") |
8 | =A3.export@a(A2,工資卡號,string(銀行實發,"#.00"), 姓名, 備注, 備注;"|") | |
A1中讀入編寫的員工表
B1中讀入編寫的工資表
A2中按姓名將兩張表合并成一張表
A3打開要保存的代發工資文件
從 A4 到 B7 中逐行寫入文件頭:其中:B6 是工資總額,從 A2 中算出銀行實發總額填入;A7 是本次代發的總筆數。
在 A8 中導出生成代發工資文件,分別是工資卡號、工資金額、姓名、空列、空列 (最后兩列是不需要填的,所以用備注列代表)。
腳本中除了 A4 格是用替換寫入以外,其它格都用了 @a 選項,表示是追加寫入。
至于其它銀行,過程大致與此類似。只要根據銀行對文本文件格式的說明,編寫好集算器 dfx 程序就可以了。
簡單總結一下,在數據導出過程中,集算器提供了 write()和 export() 兩個函數,前者是逐行寫入,后者是批量寫入。函數提供了參數和函數選項兩種控制方法,使用不同的參數或函數選項,我們可以指定是否導出字段名 / 標題、是否導出所有字段、是否使用新的字段名、追加還是替換文件、使用哪個字符做分隔參數等等選擇。
在見證了數據導出過程中集算器強大而靈活的能力后,是不是也有了莫名的沖動呢?趕快下載集算器,加入共同探索、一起變強的行列吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





