溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Python中怎么實現一個爬蟲功能,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
運行結果
Python 2.6.6 (r266:84292, Jun 20 2019, 14:14:55) [GCC 4.4.7 20120313 (Red Hat 4.4.7-23)] on linux2Type "help", "copyright", "credits" or "license" for more information.>>> import requestsTraceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/lib/python2.6/site-packages/requests/__init__.py", line 43, in <module> import urllib3 File "/usr/lib/python2.6/site-packages/urllib3/__init__.py", line 7, in <module> from .connectionpool import HTTPConnectionPool, HTTPSConnectionPool, connection_from_url File "/usr/lib/python2.6/site-packages/urllib3/connectionpool.py", line 100 _blocking_errnos = {errno.EAGAIN, errno.EWOULDBLOCK} ^SyntaxError: invalid syntax
由于Linux服務器上的Python版本為2.6.6,import requests就已經報錯了,這個庫是沒法用了。這個錯誤我試了幾種辦法,都宣告失敗。之前文章是在windows環境Python2.7下完成的。
你可能會說升級Python版本吧?我有過升級glibc把服務器搞死的慘痛教訓,不敢再亂升級了,而且我試驗的機器是24小時運行著其它系統的生產服務器,一旦升級出問題,會釀成生產事故的。所以我只能在2.6的Python下開發爬蟲。使用urllib2庫代替requests庫,實現過程基本是一樣的簡單明了。代碼如下
#coding=utf-8import urllib2exact_url='https://news.qq.com/zt2020/page/feiyan.htm'try: r=urllib2.urlopen(exact_url) #抓取設定url的數據,可以改成你想獲取的任意地址except urllib2.URLError,e: print e.code exit() r.encoding='utf8'html=r.read() print html #打印抓取的結果
所以如果你的服務器Python版本是2.6或者更低,嘗試使用urllib2庫吧!
低版本的Python還會出現無法安裝mongodb的驅動包pymongo的情況,如下
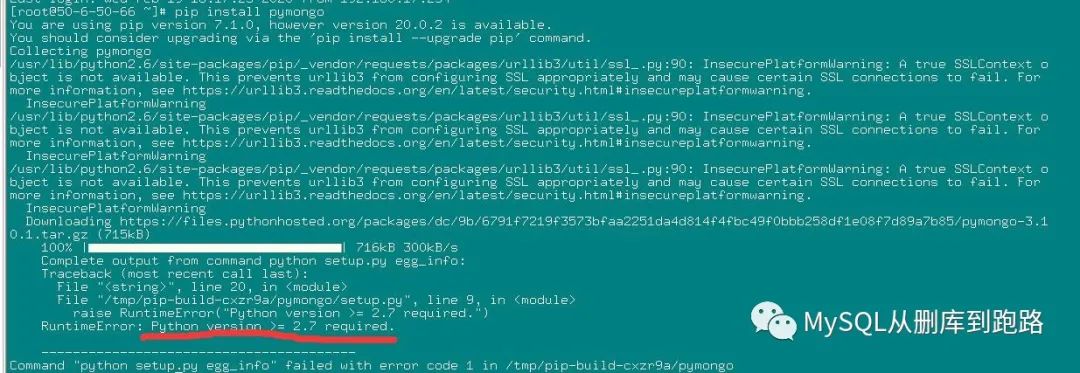
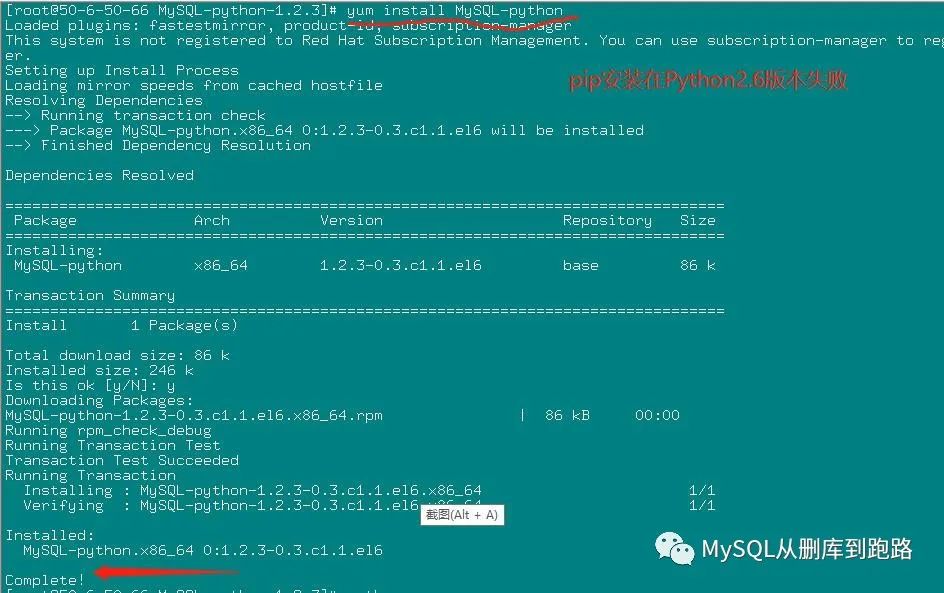
這種情況可以選擇MySQL的Python驅動包代替,pip安裝MySQL的Python驅動包也不一定成功,我最后用yum安裝成功的。
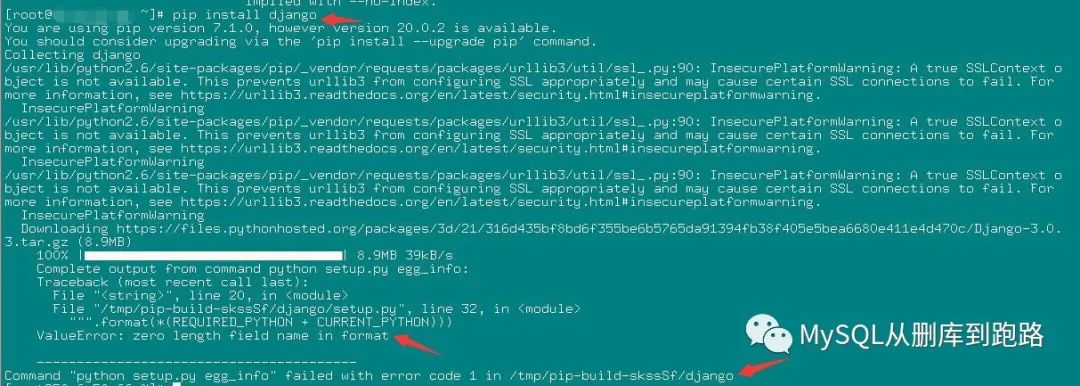
更奇葩的是2.6下,django也無法安裝成功,
看完上述內容,你們對Python中怎么實現一個爬蟲功能有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





