溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“python怎么找出數據相關性”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“python怎么找出數據相關性”吧!
首先,我們需要討論競賽本身。DengAI的目標是(目前是,因為Driventa管理局決定將其設為“持續的”比賽,因此你可以現在加入)根據天氣數據和地點預測特定一周的登革熱病例數。
每個參與者都得到了一個訓練數據集和測試數據集(不是驗證數據集)。MAE(平均絕對誤差)是一種用于計算分數的指標,訓練數據集涵蓋了2個城市(1456周)28年的每周的數值。測試數據較小,有跨越5年和3年的(這取決于城市)。
登革熱是一種蚊子傳播的疾病,發生在世界熱帶和亞熱帶地區。因為它是由蚊子攜帶的,該疾病的傳播與氣候、天氣變化有關。
如果我們看一下訓練數據集,它有多個特征:
城市和日期指標:
city :sj代表San Juan(圣胡安),iq代表Iquitos
week_start_date -以yyyy-mm-dd格式給出的日期
NOAA的GHCN每日氣候數據氣象站測量:
station_max_temp_c-最高溫度
station_min_temp_c-最低溫度
station_avg_temp_c-平均溫度
station_precip_mm-總降水量
station_diur_temp_rng_c-晝間溫度范圍
衛星降水測量(0.25x0.25度的標度):
precipitation_amt_mm-總降水量
NOAA的NCEP氣候預報系統分析測量(0.5x0.5度的標度):
reanalysis_sat_precip_amt_mm-總降水量
reanalysis_dew_point_temp_k-平均露點溫度
reanalysis_air_temp_k-平均氣溫
reanalysis_relative_humidity_percent-平均相對濕度
reanalysis_specific_humidity_g_per_kg-平均特定濕度
reanalysis_precip_amt_kg_per_m2-總降水量
reanalysis_max_air_temp_k=最大空氣溫度
reanalysis_min_air_temp_k-最低空氣溫度
reanalysis_avg_temp_k-平均氣溫
reanalysis_tdtr_k-白天溫度范圍
NOAA的CDR歸一化差異植被指數(NDVI)(0.5x0.5度的標度):
ndvi_se-城市質心東南的NVDI
ndvi_sw-城市質心西南的NVDI
ndvi_ne-城市質心東北的NVDI
ndvi_nw-城市中心西北的NVDI
此外,我們還有每周總病例數的信息。
很容易發現,對于數據集中的每一行,我們都有多個描述類似數據的特征。有四類:
溫度
降水
濕度
ndvi(這四個特征指的是城市的不同點,因此它們不是完全相同的數據)
因此,我們應該能夠從輸入中刪除一些冗余數據。
week_start_date 1994-05-07 total_cases 22 station_max_temp_c 33.3 station_avg_temp_c 27.7571428571 station_precip_mm 10.5 station_min_temp_c 22.8 station_diur_temp_rng_c 7.7 precipitation_amt_mm 68.0 reanalysis_sat_precip_amt_mm 68.0 reanalysis_dew_point_temp_k 295.235714286 reanalysis_air_temp_k 298.927142857 reanalysis_relative_humidity_percent 80.3528571429 reanalysis_specific_humidity_g_per_kg 16.6214285714 reanalysis_precip_amt_kg_per_m2 14.1 reanalysis_max_air_temp_k 301.1 reanalysis_min_air_temp_k 297.0 reanalysis_avg_temp_k 299.092857143 reanalysis_tdtr_k 2.67142857143 ndvi_location_1 0.1644143 ndvi_location_2 0.0652 ndvi_location_3 0.1321429 ndvi_location_4 0.08175
city,year,weekofyear,total_cases sj,1990,18,4 sj,1990,19,5 ...
在開始設計模型之前,我們需要查看原始數據并加以修正。為了達到這個目的,我們將使用pandas庫。通常,我們可以直接導入.csv文件并處理導入的數據幀,但有時(特別是當第一行沒有列描述時),我們必須提供列列表。
import pandas as pd
pd.set_option("display.precision", 2)
df = pd.read_csv('./dengue_features_train_with_out.csv')
df.describe()Pandas有一個名為describe的內置方法,它顯示數據集中列的基本統計信息。
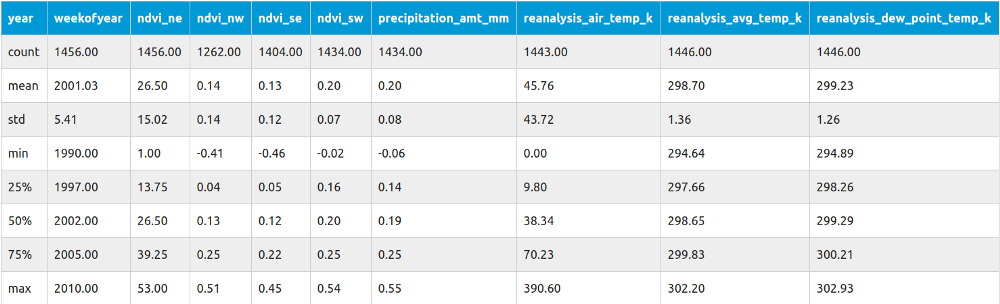
當然,這種方法只適用于數值數據。如果我們有非數值列,我們必須先做一些預處理。在我們的例子中,唯一的列是city。這個列只包含sj和iq兩個值,我們稍后將處理它。
回到主表。每行包含不同類型的信息:
count -描述非NaN值的個數
mean -整列的平均值(用于標準化)
std -標準差(也可用于標準化)
min ->max -顯示包含值的范圍(用于縮放)
讓我們從計數開始。知道數據集中有多少條記錄丟失了(一個或多個)并決定如何處理這些數據是很重要的。如果你看ndvi_nw值,它在13.3%的情況下是空的。如果你決定用諸如0之類的任意值替換缺少的值,這可能是個性能問題。通常,有兩種常見的解決方案:
設置平均值
插值法
當處理序列數據時(就像我們這個場景一樣),從它的鄰域中插值(僅從鄰域中取平均值)值,而不是用整個集合中的平均值來代替它,這樣比較合理。
通常,序列數據在序列中的值之間有一定的相關性,使用鄰域可以得到更好的結果。我給你舉個例子。
假設你正在處理溫度數據,并且你的整個數據集由一月到十二月的值組成。全年的平均值將是一年中大部分時間缺失天數的無效替代值。
如果從7月開始計算,則可能會有[28,27,-,-,30]。如果在倫敦的話,年平均氣溫是11攝氏度(或52華氏度)。在這種情況下使用11作為溫度填充就是錯誤的。這就是為什么我們應該使用插值而不是平均值。
有了插值(即使在有更大差距的情況下),我們應該能夠獲得更好的結果。如果你計算這些值,你應該得到(27+30)/2=28.5和(28.5+30)/2=29.25,所以最終我們的數據集看起來像是[28,27,28.5,29.25,30],遠遠好于[28,27,11,11,30]。
將數據集拆分為城市
因為我們已經討論了一些重要的事情,所以我們可以定義一種方法,該方法允許我們將分類列(city)重新定義為二進制列向量并對數據進行插值:
def extract_data(train_file_path, columns, categorical_columns=CATEGORICAL_COLUMNS, categories_desc=CATEGORIES,
interpolate=True):
# 讀取csv文件并返回
all_data = pd.read_csv(train_file_path, usecols=columns)
if categorical_columns is not None:
# 將分類映射到列
for feature_name in categorical_columns:
mapping_dict = {categories_desc[feature_name][i]: categories_desc[feature_name][i] for i in
range(0, len(categories_desc[feature_name]))}
all_data[feature_name] = all_data[feature_name].map(mapping_dict)
# 將映射的分類數據更改為0/1列
all_data = pd.get_dummies(all_data, prefix='', prefix_sep='')
# 修復丟失的數據
if interpolate:
all_data = all_data.interpolate(method='linear', limit_direction='forward')
return all_data此函數返回一個數據集,其中包含兩個名為sj和iq的二進制列,它們具有布爾值,其中city被設置為sj或iq。
繪制數據圖以直觀地了解值在序列中的分布是很重要的。我們將使用一個名為Seaborn的庫來幫助我們繪制數據。
sns.pairplot(dataset[["precipitation_amt_mm", "reanalysis_sat_precip_amt_mm", "station_precip_mm"]], diag_kind="kde")
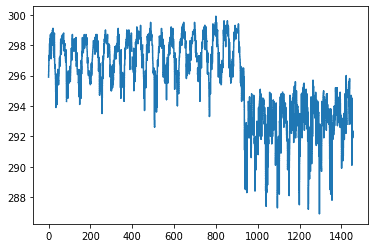
這里我們只有一個數據集的特征,我們可以清楚地區分季節和城市(平均值從~297下降到~292)。
另一件有用的事情是不同特征之間的關聯。這樣我們就可以從數據集中刪除一些冗余的特征。
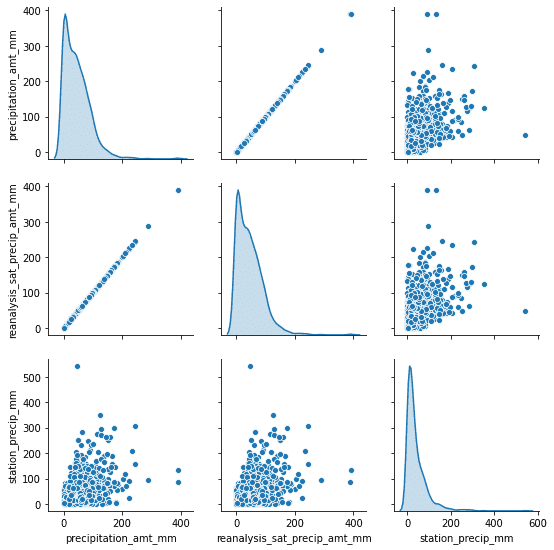
正如你所注意到的,我們可以立即刪除其中一個降水特征。一開始這可能是無意的,但因為我們有來自不同來源的數據,同一類數據(如降水量)并不總是完全相關的。這可能是由于不同的測量方法或其他原因造成的。
當我們使用很多特征時,我們不需要為每一對都繪制成對圖。另一個選擇就是計算所謂的相關性分數。不同類型的數據有不同類型的相關性。我們使用corr()的方法生成數據集的數值相關性。
如果有不應該被視為二進制的分類列,你可以計算Cramer的V關聯度量來找出它們和其他數據之間的“相關性”。
import pandas as pd
import seaborn as sns
# 導入我們的提取函數
from helpers import extract_data
from data_info import *
train_data = extract_data(train_file, CSV_COLUMNS)
# 獲取“sj”city的數據并刪除兩個二進制列
sj_train = train_data[train_data['sj'] == 1].drop(['sj', 'iq'], axis=1)
# 生成熱圖
corr = sj_train.corr()
mask = np.triu(np.ones_like(corr, dtype=np.bool))
plt.figure(figsize=(20, 10))
ax = sns.heatmap(
corr,
mask=mask,
vmin=-1, vmax=1, center=0,
cmap=sns.diverging_palette(20, 220, n=200),
square=True
)
ax.set_title('Data correlation for city "sj"')
ax.set_xticklabels(
ax.get_xticklabels(),
rotation=45,
horizontalalignment='right'
);
你可以對iq 城做同樣的事情,并將兩者進行比較(相關性是不同的)。
如果你看看這張熱圖,很明顯可以看出哪些特征相互關聯,哪些不相關。你應該知道有正相關和負相關(深藍色和深紅色)。沒有相關性的特征是白色的。
有幾組正相關的特征,毫不奇怪,它們指的是同一類型的測量(例如station_min_temp_c和station_avg_temp_c之間的相關性)。但在不同的特征之間也存在相關性(比如reanalysis_specific_humidity_g_per_kg和reanalysis_dew_point_temp_k)。我們還應該關注total_cases和其他特征之間的相關性,因為這是我們需要預測的。
這次我們走運了,因為沒有什么東西和我們的目標有很強的相關性。但是我們仍然應該能夠為我們的模型選擇最重要的特征。現在看熱圖沒什么用,讓我切換到條形圖。
sorted_y = corr.sort_values(by='total_cases', axis=0).drop('total_cases')
plt.figure(figsize=(20, 10))
ax = sns.barplot(x=sorted_y.total_cases, y=sorted_y.index, color="b")
ax.set_title('Correlation with total_cases in "sj"')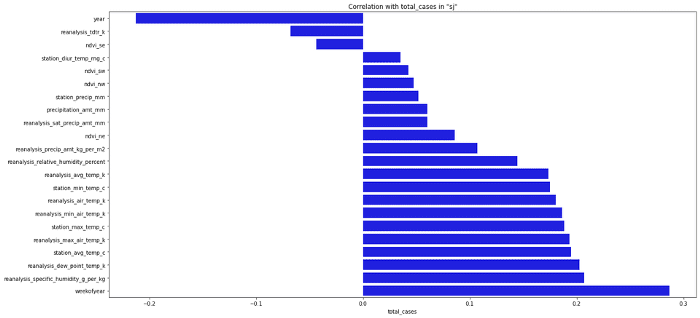
通常,在為模型選擇特征時,我們選擇的特征與目標的絕對相關值最高。這取決于你決定你選擇多少特征,你甚至可以選擇所有的特征,但這通常不是最好的主意。
觀察目標值在數據集中是如何分布的也是很重要的。我們可以很容易地用pandas做到:
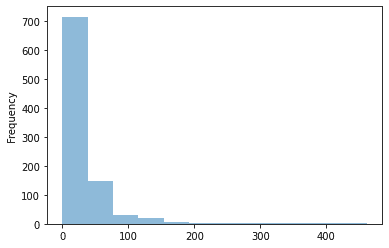
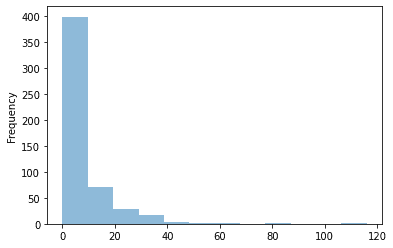
平均一周的病例數相當少。只是偶爾(一年一次),案件總數會跳到某個更高的數值。在設計我們的模型時,我們需要記住這一點,因為即使我們設法找到了“跳躍”,我們可能會在幾周內得分損失慘重,因為跳躍這種情況幾乎沒有樣本。
本文最后要討論的是NDVI指數(歸一化差異植被指數)。這個指數是植被的指標。高負值對應于水,接近0的值表示巖石/沙子/雪,值接近1熱帶森林。在給定的數據集中,每個城市有4個不同的NDVI值(每個值對應于地圖上不同的角落)。
即使總體NDVI指數對于了解我們正在處理的地形類型非常有用。如果我們需要為多個城市設計一個模型,地形類型的特征可能會很有用,但在這種情況下,我們只已知兩個城市的氣候和位置。我們不需要訓練我們的模型來判斷我們所處的環境,相反,我們可以為每個城市訓練不同的模型。
我花了一段時間嘗試使用這些值(尤其是在這種情況下插值很困難,因為我們在這個過程中使用了大量的信息)。使用NDVI指數也可能產生誤導,因為數值的變化并不一定與植被過程的變化相對應。
感謝各位的閱讀,以上就是“python怎么找出數據相關性”的內容了,經過本文的學習后,相信大家對python怎么找出數據相關性這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





