溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
文 | 潘國慶 攜程大數據平臺實時計算平臺負責人
 本文主要從攜程大數據平臺概況、架構設計及實現、在實現當中踩坑及填坑的過程、實時計算領域詳細的應用場景,以及未來規劃五個方面闡述攜程實時計算平臺架構與實踐,希望對需要構建實時數據平臺的公司和同學有所借鑒。
本文主要從攜程大數據平臺概況、架構設計及實現、在實現當中踩坑及填坑的過程、實時計算領域詳細的應用場景,以及未來規劃五個方面闡述攜程實時計算平臺架構與實踐,希望對需要構建實時數據平臺的公司和同學有所借鑒。
攜程大數據平臺結構分為三層:
應用層:開發平臺Zeus(分為調度系統、Datax數據傳輸系統、主數據系統、數據質量系統)、查詢平臺(ArtNova報表系統、Adhoc查詢)、機器學習(基于tensorflow、spark等開源框架進行開發;GPU云平臺基于K8S實現)、實時計算平臺Muise;
中間層:基于開源的大數據基礎架構,分為分布式存儲和計算框架、實時計算框架;
離線主要是基于Hadoop、HDFS分布式存儲、分布式離線計算基于Hive及Spark、KV存儲基于HBase、Presto和Kylin用于Adhoc以及報表系統;
實時計算框架底層是基于Kafka封裝的消息隊列系統Hermes, Qmq是攜程自研的消息隊列, Qmq主要用于定單交易系統,確保百分之百不丟失數據而打造的消息隊列。
底層:資源監控與運維監控,分為自動化運維系統、大數據框架設施監控、大數據業務監控。

1.Muise平臺介紹
1)Muise是什么
Muise,取自希臘神話的文藝女神繆斯之名,是攜程的實時數據分析和處理的平臺;Muise平臺底層基于消息隊列和開源的實時處理系統JStorm、Spark Streaming和Flink,能夠支持秒級,甚至是毫秒級延遲的流式數據處理。
2)Muise的功能
數據源:Hermes Kafka/Mysql、Qmq;
數據處理:提供Muise JStorm/Spark/FlinkCore API消費Hermes或Qmq數據,底層使用Jstorm、Spark或實時處理數據,并提供自己封裝的API給用戶使用。API對接了所有數據源系統,方便用戶直接使用;
作業管理:Portal提供對于JStorm、Spark Streaming和Flink作業的管理,包含新建作業,上傳jar包以及發布生產等功能;
監控和告警:使用Jstorm、Spark和Flink提供的Metrics框架,支持自定義的metrics;metrics信息中心化管理,接入Ops的監控和告警系統,提供全面的監控和告警支持,幫助用戶在第一時間內監控到作業是否發生問題。
2.Muise平臺現狀
平臺現狀:
Jstorm 2.1.1、Spark 2.0.1、Flink1.6.0、Kafka 2.0;
集群規模:
13個集群、200+臺機器150+Jstorm、50+Yarn、100+ Kafka;
作業規模:
11個業務線、350+Jstorm作業、120+SS/Flink作業;
消息規模:
Topic 1300+、增量 100T+ PD、Avg 200K TPS、Max 900K TPS;
消息延時:
Hermes 200ms以內、Storm 20ms以內;
消息處理成功率:
99.99%。
3.Muise平臺演進之路
2015 Q2~2015 Q3 :基于Storm開發實時計算平臺;
2016 Q1~2016 Q2 :Storm遷移JStorm、引入StreamCQL;
2017 Q1~2017 Q2 :Spark Streaming調研與接入;
2017 Q3~2018 Q1 :Flink調研與接入。
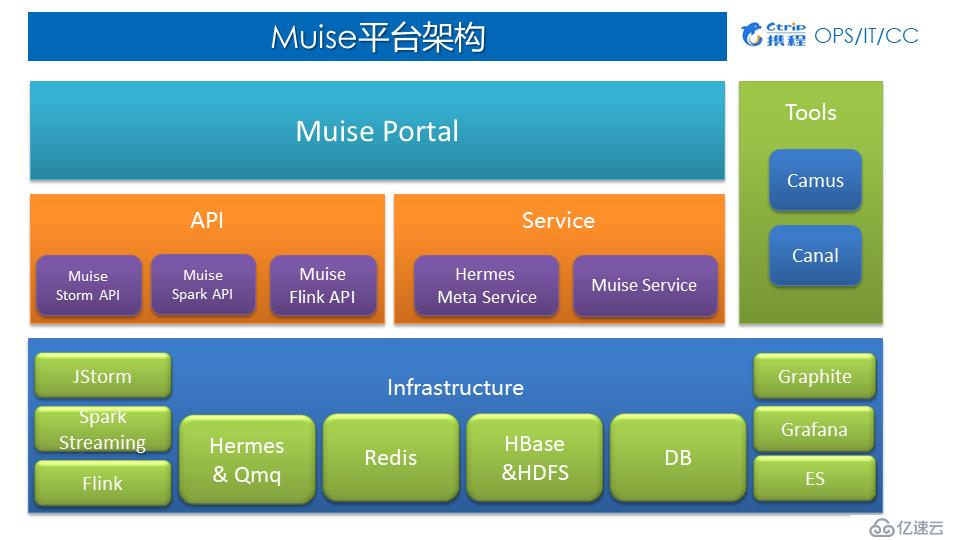
4.Muise平臺架構
1)Muise平臺架構
應用層:Muise Portal 目前主要支持了 Storm 與 Spark Streaming兩類作業,支持新建作業、Jar包發布、作業運行與停止等一系列功能;
中間層:對底層Infrastructure做了封裝,為用戶提供基于Storm、Spark、Flink相對應的API以及各方面Services;
底層:Hermes & Qmq是數據源、Redis、HBase、HDFS、DB等作為外部的數據存儲、Graphite、Grafana、ES主要用于監控。
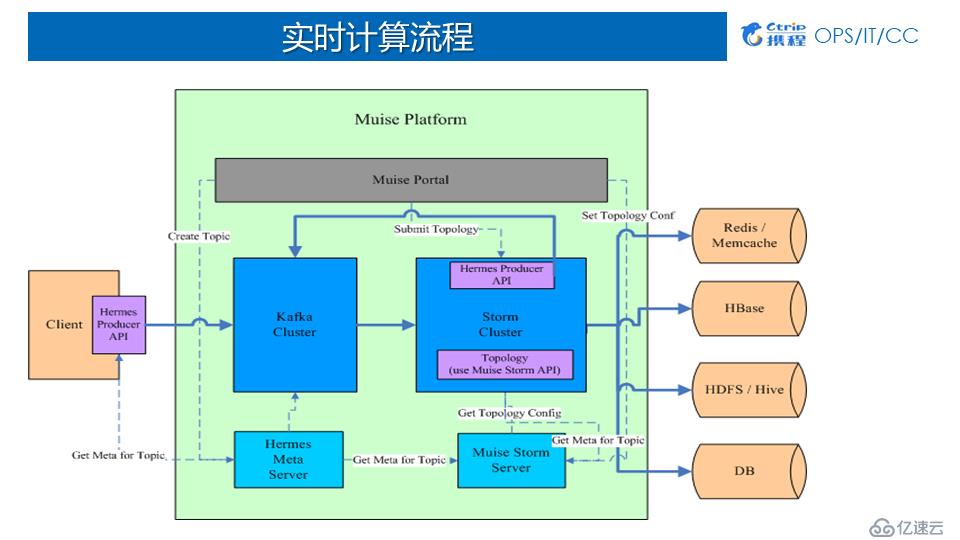
2)Muise實時計算流程
Producer端:用戶先申請Kafka的topic,然后將數據實時寫到Kafka中;
Muise Portal端:用戶基于我們提供的API做開發,開發完以后通過Muise Portal配置、上傳和啟動作業;作業啟動后,jar包會分發到各個對應的集群消費Kafka數據;
存儲端:數據在被消費之后可以寫回QMQ或Kafka,也可以存儲到外部系統Redis、HBase、HDFS/Hive、DB。
5.平臺設計 ——易用性
首先:作為一個平臺設計第一要點就是要簡單易用,我們提供綜合的Portal,便于用戶自己新建管理它的作業,方便開發實時作業第一時間能夠上線;
其次:我們封裝了很多Core API,支持多套實時計算框架:
支持HermesKafka/MySQL 、QMQ;
集成Jstorm、Spark Streaming、Flink;
作業資源管控;
提供DB、Redis、HBase和HDFS輸出組件;
基于內置Metric系統定制多項metric進行作業預警監控;
用戶可自定義Metric用于監控與預警;
支持AtLeast Once 與Exactly Once語義。
上文講到平臺設計要易用,下面講平臺的容錯,確保數據一定不能出問題。
6.平臺設計——容錯
Jstorm:基于Acker機制確保At Least Once;
Spark Streaming:基于Checkpoint實現Exactly Once、基于Kafka Offset回溯實現At Least Once;
Flink:基于Flinktwo-phase commit + Kafka 0.11事務性支持實現Exactly Once。
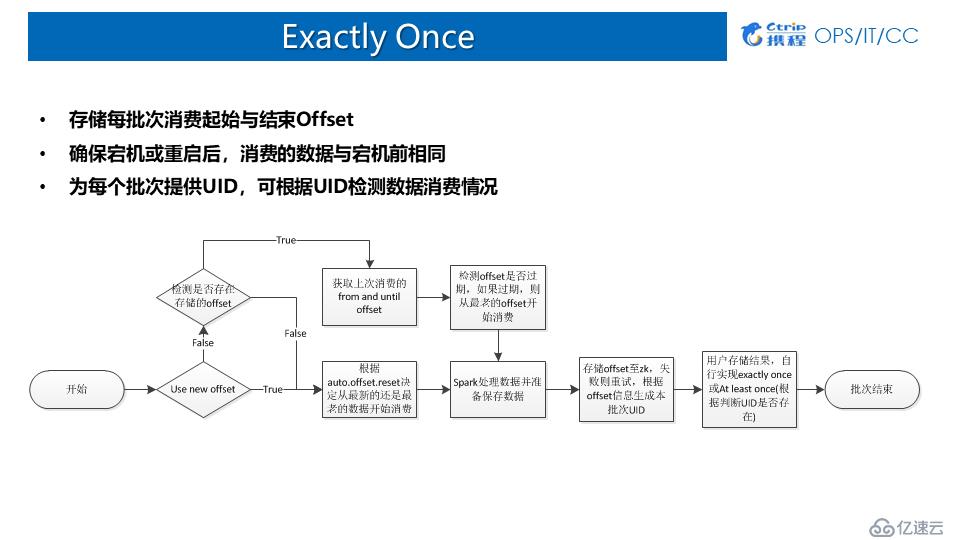
7.Exactly Once
1)Direct Approach
當前大部分拿Spark Streaming消費Kafka的話,都是用Direct Approach的方式:
優點:記錄每個批次消費的Offset,作業可通過offset回溯;
缺點:數據存儲與offset存儲異步:
數據保存成功,應用宕機,offset未保存 (導致數據重復);
offset保存成功,應用宕機,數據保存失敗 (導致數據丟失);
2)CheckPoint
優點:默認記錄每個批次的運行狀態與源數據,宕機時可從cp目錄恢復;
缺點:
1. 非100%保證ExactlyOnce;
https://www.iteblog.com/archives/1795 描述了無法保證Exactly once的場景;
https://issues.apache.org/jira/browse/SPARK-17606 也存在doCheckPoint時出現塊丟失的情況;
2. 啟用cp帶來額外性能影響;
3. Streaming作業邏輯改變無法從cp恢復。
適用場景:比較適合有狀態計算的場景;
使用方式:建議程序自己存儲offset,當發生宕機時,如果spark代碼邏輯沒有發生改變,則根據checkpoint目錄創建StreamingContext。如果發生改變,則根據實現自己存儲的offset創建context并設立新的checkpoint點。
8.平臺設計——監控與告警
如何能夠第一時間幫用戶發現作業問題,是一個重中之重。
集群監控
服務器監控:考量的指標有Memory、CPU、Disk IO、Net IO;
平臺監控:Ganglia;
作業監控
基于實時計算框架原生Metric系統;
定制Metrics反應作業狀態;
采集原生與定制Metrics用于監控和告警;
存儲:Graphite展 現:Grafana 告警:Appmon;
我們現在定制的很多Metrics當中比較通用的是:
Fail:定期時間內,Jstorm數據處理失敗數量、Spark task Fail數量;
Ack:定期時間內,處理的數據量;
Lag:定期時間內,數據產生與被消費的中間延遲(kafka 2.0基于自帶bornTime)。
攜程開發了自己告警系統,將Metrics代入系統之后基于規則做告警。通過作業監控看板完成相關指標的監控和查看,我們會把Flink作為比較關心的Metrics指標,全都導入到Graphite數據庫里面,然后基于前端Grafana做展現。通過作業監控看板,我們能夠直接看到Kafka to Flink Delay(Lag),相當于數據從產生到被Flink作業消費,中間延遲是62毫秒,速度相對比較快的。其次我們監控了每次從Kafka中獲取數據的速度。因為從Kafka獲取數據是基于一小塊一小塊去獲取,我們設置的是每次拉2兆的數據量。通過作業監控看板可以監控到每次從Kafka拉取數據時候的平均延遲是25毫秒,Max是 760毫秒。

接下來講講我們在這幾年踩到的一些坑以及如何填坑的。
坑1:HermesUBT數據量大,埋點信息眾多,服務端與客戶端均承受巨大壓力;
解決方案:提供統一分流作業,基于特定規則與配置將數據分流至不同topic。
坑2:Kafka無法保證全局有序;
解決方案:如果在強制全局有序的場景下,使用單Partition;如果在部分有序的情況下,可基于某個字段作Hash,保證Partition內部有序。
坑3:Kafka無法根據時間精確回溯到某時間段的數據;
解決方案:平臺提供過濾功能,過濾時間早于設定時間的數據(kafka 0.10之后每條數據都帶有自己的時間戳,所以這個問題在升級kafka之后自然而然的就解決了)。
坑4:最初,攜程所有的Spark Streaming、Flink作業都是跑在主機群上面的,是一個大Hadoop集群,目前是幾千臺規模,離線和實時是混布的,一旦一個大的離線作業上來時,會對實時作業有影響;其次是Hadoop集群經常會做一些升級改造,所以可能會重啟Name Node或者Node Manager,這會導致作業有時會掛掉;
解決方案:我們采用分開部署,單獨搭建實時集群,獨立運行實時作業。離線歸離線,實時歸實時的,實時集群單獨跑Spark Streaming跟Yarn的作業,離線專門跑離線的作業。
當分開部署后,會遇到新的問題,部分實時作業需要去一些離線作業做一些Join或 Feature的操作,所以也是需要訪問主機群數據。這相當于有一個跨集群訪問的問題。
坑5:Hadoop實時集群跨集群訪問主機群;
解決方案:Hdfs-site.xml配置ns-prod、ns雙重namespace,分別指向本地與主機群;
Spark配置spark.yarn.access.namenodes or hadoopFlieSystems
坑6:無論是Jstorm還是接Storm都會遇到一個CPU搶占的問題,當你上了一個大的作業,尤其是那種消耗CPU特別厲害的,可能我給它分開了一個Worker,一個CPU Core,但是它最后有可能會給我用到3個甚至4個;
解決方案:啟用cgroup限制cpu使用率。
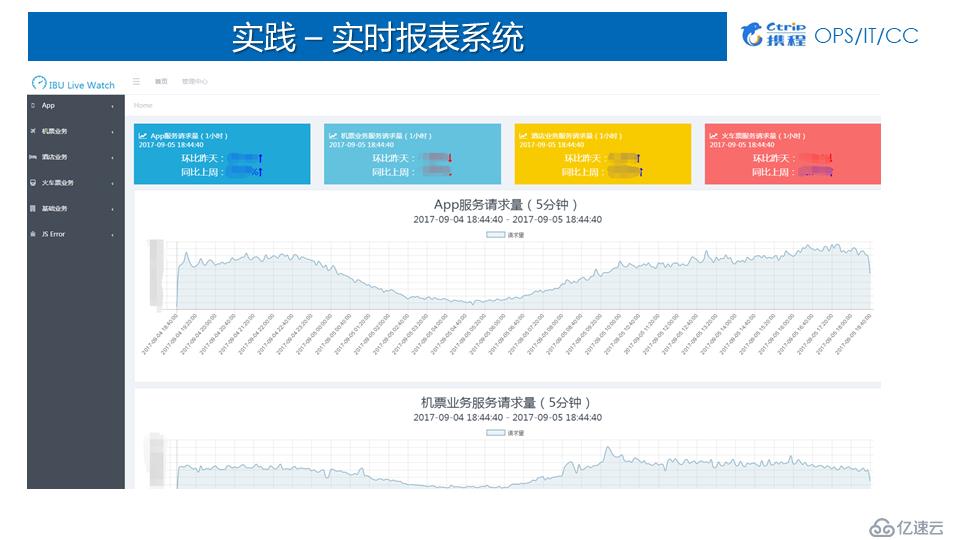
1.實時報表統計
實時報表統計與展現也是Spark Streaming使用較多的一個場景,數據可以基于Process Time統計,也可以基于Event Time統計。由于本身Spark Streaming不同批次的job可以視為一個個的滾動窗口,某個獨立的窗口中包含了多個時間段的數據,這使得使用SparkStreaming基于Event Time統計時存在一定的限制。一般較為常用的方式是統計每個批次中不同時間維度的累積值并導入到外部系統,如ES;然后在報表展現的時基于時間做二次聚合獲得完整的累加值最終求得聚合值。下圖展示了攜程IBU基于Spark Streaming實現的實時看板。
2.實時數倉
1)Spark Streaming近實時存儲數據
如今市面上有形形×××的工具可以從Kafka實時消費數據并進行過濾清洗最終落地到對應的存儲系統,如:Camus、Flume等。相比較于此類產品,Spark Streaming的優勢首先在于可以支持更為復雜的處理邏輯,其次基于Yarn系統的資源調度使得Spark Streaming的資源配置更加靈活,用戶采用Spark Streaming實時把數據寫到HDFS或者寫到Hive里面去。
2)基于各種規則作數據質量檢測
基于Spark Streaming,自定義metric功能對數據的數據量、字段數、數據格式與重復數據進行了數據質量校驗與監控。
3)基于自定義metric實時預警
基于我們封裝提供的Metric注冊系統確定一些規則,然后每個批次基于這些規則做一個校驗,返回一個結果。這個結果會基于Metric sink吐出來,吐出來基于metrics的結果做一個監控。當前我們采用Flink加載TensorFlow模型實時做預測。基本時效性是數據一旦到達兩秒鐘之內就能夠把告警信息告出來,給用戶非常好的體驗。

1.Flink on K8S
在攜程內部有一些不同的計算框架,有實時計算的,有機器學習的,還有離線計算的,所以需要一個統一的底層框架來進行管理,因此在未來將Flink遷移到了K8S上,進行統一的資源管控。
2.Muise平臺接入Flink SQL
Muise平臺雖然接入了Flink,但是用戶還是得手寫代碼,我們開發了一個實時特征平臺,用戶只需要寫SQL,即基于Flink的SQL就可以實時采集用戶所需要的模型里面或者用到的特征。之后會把實時特征平臺跟實時計算平臺做進行合并,用戶最后只需要寫SQL就可以實現所有的實時作業實現。
3.Jstorm全面啟用Cgroup
當前由于部分歷史原因導致現在很多作業跑在Jstorm上面,因此出現了資源分配不均衡的情況,之后會全面啟用Cgroup。
4.在線模型訓練
攜程部分部門需要實時在線模型訓練,通過用Spark訓練了模型之后,然后使用Spark Streaming的模型,實時做一個攔截或者控制,應用在風控等場景。
—end—
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





