溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在給大家講解Hive之前,我們要先熟悉下Hadoop的一些概念。
Hadoop可以分為一下幾個部分
HDFS hadoop的文件系統,用于數據存儲
MapReduce 用于數據處理
Yarn 用于資源管理
那Hadoop 中的MapReduce程序一般處理輸入都是一些標準化的日志,假設我們有如下的日志文件。
姓名 科目 成績
張三 語文 90
李四 語文 80
王五 語文 88
張三 數學 99
李四 數學 98
王五 數學 90
我們需要對這些數據進行處理,如獲取成績最高者、統計平均分等。
那么沒做一次處理我們就需要像寫八股文似的進行編寫MapReduce程序:
1、編寫Mapper
2、編寫Reducer
3、編寫main
4、在main中定義job
5、設置job的輸入、輸出以及參數
6、執行job
這樣就需要我們對MapReduce編程十分的熟悉,并且這種方式比較費時費力。同時,在一般的公司中,
對這種有固定格式的數據進行處理我們一般都交由專門的DB進行處理,但是DB又對MapReduce的編程不了解,
讓他們編寫MapReduce程序來處理數據就不太現實,那有沒有一種或者一個工具,
能讓他們使用類似sql的方式來清洗數據。
答案當然是有的,那就是我們的Hive。Hive是一個在hadoop基礎上來處理結構化數據的數據倉庫基礎工具。這里說它是一個工具,它主要的功能就是方便我們處理數據,但是數據的存儲等還是在HDFS上。
Hive是架構在Hadoop之上,可以提供類似SQL語言的查詢語句進行簡化大數據的處理以及清晰,
方便DB進行數據處理。
Hive開始是有Facebook開發,后由Apache軟件基金會開發,并將其Apache下的一個頂級項目。
Hive為一個開源項目,它用在好多不同的公司。
1、它不像關系型數據庫只能處理少量的數據,hive由于架構在Hadoop之上,本身就賦予了其處理大數據的能力。
2、它提供一種類似SQL的查詢語言,叫HQL或者HiveQL。
3、由于本身就是在MapReduce上進行的二次擴展,因此hive就具有了良好的可擴展型,
如果出現一個hive提供不了的處理,我們可以通過編寫mapreduce程序,將其封裝成hive的一個函數。HIve只是一個工具,他將HQL轉換成MapReduce程序運行在Yarn上面,進行處理HDFS上存儲的數據,
這樣就可以讓我們對于簡單的數據處理,只是編寫一下HQL就可以了,不用在編寫MapReduce程序。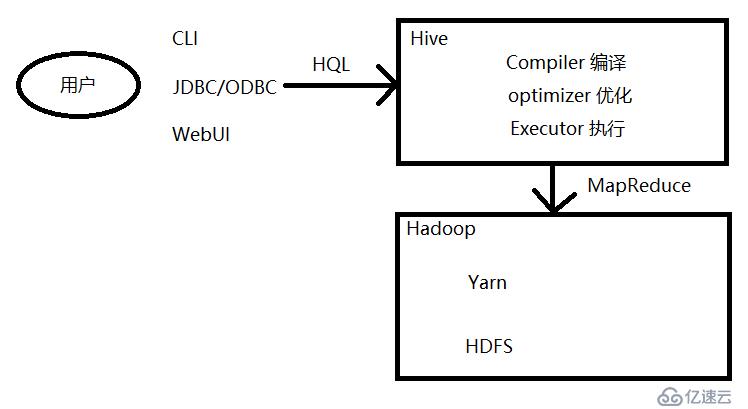
用戶在使用Hive的過程中,通過CLI、JDBC/ODBC、WebUI等方式,提供HQL語句到hive中,hive通過編譯、優化、執行,將經過優化的HQL語句進行轉換成MapReduce程序放到yarn上運行。
針對開始提出的查詢成績最高的那一行,我們只需要寫如下的HQL就可以了:
select * from table order by sorce desc limit 0,1
到此,整個hive的介紹就個大家講解完成了,在下一篇中,我們講會講解hive的安裝
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





