溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹如何進行MYSQL MGR崩潰后的修復和問題查找,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
MYSQL 的 GROUP REPLICATION 估計大多數的公司都沒有用,即使用也不是在主要的項目和關鍵的地方。所以網上相關MYSQL Group Replicaiton 的的修復的東西也不多。趕巧,最近我們的測試系統的 MGR 崩潰了。
我們的MGR 的測試系統是三臺MYSQL 5.7.23 + Proxysql 組成的,曾經壞過一臺機器(網絡原因),但MGR 穩穩的提供數據庫服務,這次的崩潰和上次比,沒有那么簡單。三臺機器掛了兩臺。其實和監控不到位有關,但因為是測試機,也都沒有上什么監控,才有了本次的探索)
從第二臺機器上(Secondary)上看primary 機器無法訪問,三號機根本就不在member list 中, 三號機,在本機看是ERROR 的狀態,主庫雖然看似活著,但是已經無法登陸了。
project manager 和 開發都要用這個測試系統,所以分析,解決問題只能要一個字,快。(其實我是想詳細的分析一下到底哪里出了問題)。
在保存了錯誤日志后,我嘗試恢復,主庫,重啟啟動后可以登錄,并且再次重新運行命令,一般你要重新來過,最好要知道,崩潰中的那個庫時最后的主庫,然后在那個主庫上操作下面的命令。(這點是很重要的和后面的恢復有關)
SET GLOBAL group_replication_bootstrap_group=ON;
start group_replication;
SET GLOBAL group_replication_bootstrap_group=OFF;
在操作命令后主庫已經啟動了,生成了下面的日志

到第二臺機器上進行恢復,
重新執行
CHANGE MASTER TO MASTER_USER='repl', MASTER_PASSWORD='password' FOR CHANNEL 'group_replication_recovery';
SET GLOBAL group_replication_allow_local_disjoint_gtids_join=ON; (此命令在MYSQL 8不在存在)
start group_replication;
SET GLOBAL group_replication_allow_local_disjoint_gtids_join=OFF;
執行完畢后,稍等片刻

兩臺機器已經恢復了,應該可以正常對外工作了,從proxysql 上已經可以訪問到集群了。
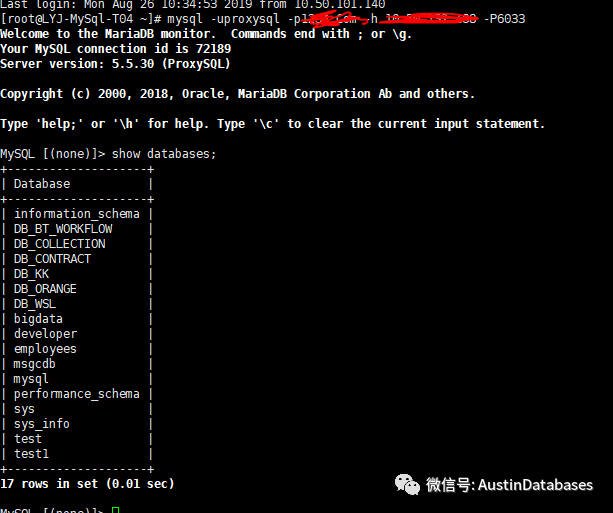
目前還差一臺機器,但這臺機器著實是恢復的過程沒有那么簡單,在重新將第三臺機器添加進集群的過程中,發現問題,
[ERROR] Error reading packet from server for channel 'group_replication_recovery': The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires. (server_errno=1236)
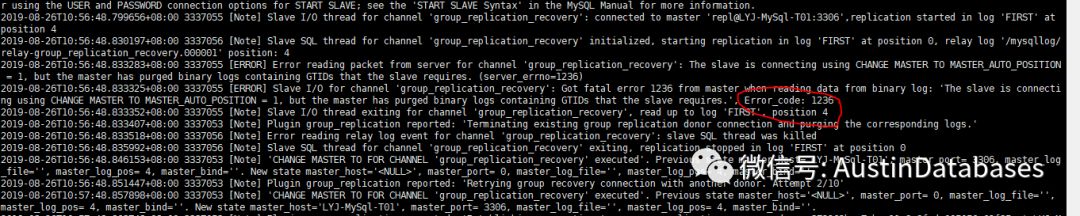
通過這個錯誤,我至少可以推斷出兩件事
1 這個服務器想直接加入到集群中,大概率是不大可能了,日志已經跟不上了
2 這個服務器和集群脫離的時間,一定早于集群出現故障的時間。
后面在分析錯誤日志的過程中,證明了我上面的猜測。
怎么進行恢復這第三臺機器,最快速的就是備份后再恢復了,XTRABACKUP 備份了主庫后,發現在perpare 的時候非常慢,并且備份的時候,在日志的備份顯示中,也是非常的慢,估計里面必有蹊蹺。
在恢復的過程中,很奇怪的是,將備份文件恢復到了第三臺機器后,提示

在回來翻看曾經的primary 的一號機,的確是crash了

并且 doublewrite 也有問題,有部分數據可能是沒有寫進去,這也就導致后面恢復第三號機的時候,使用主機的備份導致三號機還是起不來的問題。
后面因為2號機的數據庫還是正常的,所以直接resetart 1號MYSQL,下面的圖也就是后邊備份1號機在備份的時候,和XTRABACKUP PERPARE 的時候異常慢的一個原因。大部分數據要進行UNDO

目前的狀況是 1 2 號機都正常啟動的情況下,這里還是根據當時的狀態,來還讓 1號機作為primary (在配置文件中已經設置了MGR的權重), 這里重新操作MGR 初始化的操作就略去了(之前寫過MGR 安裝的文字),
很快1 和 2 號機,恢復了正常,集群也恢復正常,對外的訪問也正常了。
下面回到了最后的3號機怎么恢復的問題,通過備份和恢復,3號機已經正常了,在啟動后,3號機自動開始接入到集群中,但結果是失敗的,最后在經過10次的嘗試,被集群提了出來,錯誤原因也很簡單,就是數據有沖突,我們直接根據備份時候 XTRABAKCUP 文件中的 GTID 信息,直接將
這段GTID PURGED 掉就OK了

再次將三號機加入到集群當中,OK

整體的集群就恢復了。
通過錯誤日志和相關一些指導來看,大致問題是 3號機由于網絡原因已經有一段時間和集群脫離了,而集群不可用的問題,大致是測試人員對系統進行了壓測,上面圖上也貼出來,清理線程無法將內存的臟頁及時刷新到磁盤導致的。但當時具體執行了什么語句,估計是查不到了,后期會考慮安裝audit 功能,記錄相關的語句,為問題的處理提供更多的信息。
關于如何進行MYSQL MGR崩潰后的修復和問題查找就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





