溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下POSTGRESQL如何解決LIKE %%的問題,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
題目比Big mouth, 在POSTGRESQL 進入視野前,如果我們看到有程序員這樣寫
Select name from employees where name like '%Chars%';
并且這個表的行數在幾百萬行到千萬行的水平,我們只能給寫這個語句的人一句。
Are you lost your mind , 換句話就是 你是瘋了嗎?
世界不同了,隊伍不好帶,以前 ORACLE , SQL SERVER , MYSQL 都統一口徑說,我們不支持這樣 SB 的查詢方式,你要不就 寫成
select name from emplyees where name like '%Chars'
要不就
select name from employees where name like 'Chars%'
如果非要如此,%% 的like查詢,你不如去做全文索引。 就此就將這樣的需求已 SB 的標簽貼了幾十年。 就連ORACLE 這樣已經神話的數據庫,也對此毫無作為。
“更多選擇,更多歡樂”, 當然這歡樂不是給 ORALCE ,SQL SERVER ,MYSQL 這幾個家伙的。因為到此為止,這幾位,還是只能 TABLE SCAN 對待 like %% 這樣的查詢,而走不了索引。
POSTGRESQL ,面對幾十年解決不了的問題,輕聲的說了句,我試試吧
來我們看看POSTGRESQL 怎么能將別的數據庫都做不到的事情,輕描淡寫的就做完了。
首先我們先做一個實驗,先建立一個表,

然后我們插入100的數據

我們看看我們插入了什么樣的數據,以NAME 為字段的一堆無序的字符。
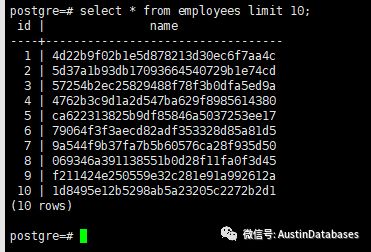
為了比較POSTGRESQL 在處理 LIKE %% 這樣的數據和全表掃描的區別,我們也建立一個不使用POSTGRESQL 索引的數據表,來做一個對比
名字里面有一個 2

通過POSTGRESQL 獨有的GIN 索引,(這只是其中一種解決 LIKE %%方法,還有幾種方法還可以面對更大無序的數據去做 like %%),至于更刺激的事情,還是找個機會下次說。
CREATE INDEX idx_employees_name_gin ON employees USING gin (name gin_trgm_ops);

索引建立完了,我們也需要開始做比較了
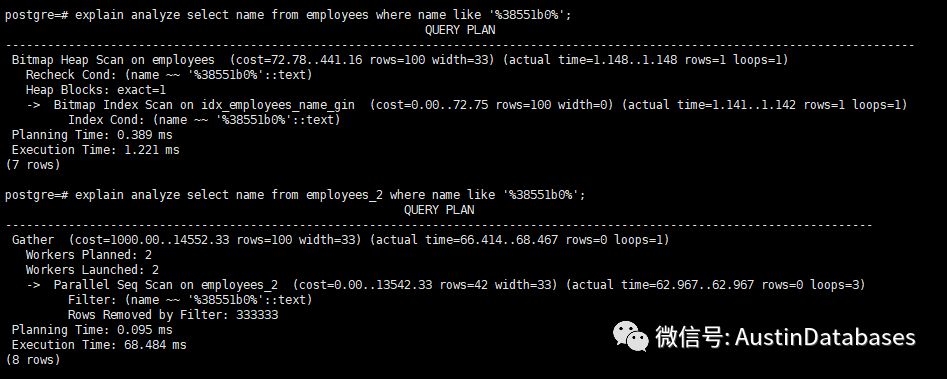
結果很明顯,employees 1 在使用了 gin 索引后,查詢的時間耗時 1.221ms ,而如果不使用索引的情況下 我們要使用 68.484 ms 的時間。
有人可能有異議,說你的比較光是在POSTGRESQL 本身上做的,這不公平,你應該在MYSQL , SQL SERVER , ORACLE 最新版上都做一遍。
我只想說,當我看到100萬的數據,在用LIKE %% 查詢還能走索引,在一個破筆記本上的時間是 1.221ms,我已經毫無愿望在去測那些數據庫了,毫無意愿, 而更可笑的是, 這樣一個數據庫他是免費的,比MYSQL 免費的還徹底。 面對 SQL SERVER ORACLE 收取巨額費用,幾十年了還解決不了這樣like %% 的問題。
看完了這篇文章,相信你對“POSTGRESQL如何解決LIKE %%的問題”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





