溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關Python中怎么使用 pivot_table()實現數據透視功能,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
pivot_table
pivot()函數沒有數據聚合功能,要想實現此功能,需要調用Pandas包中的第三個頂層函數:pivot_table(),在pandas中的工程位置如下所示:
pandas
|
pivot_table()
如下,構造一個df實例:
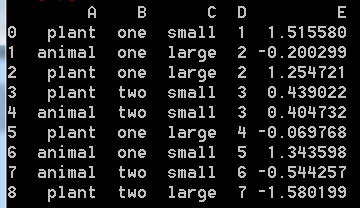
調用如下操作:
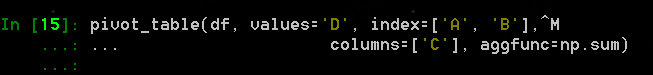
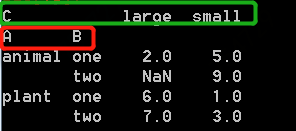
參數index指明A和B為行索引,columns指明C列取值為列,聚合函數為求和,values是在兩個軸(index和columns)確定后的取值用D列。得到結果如下:
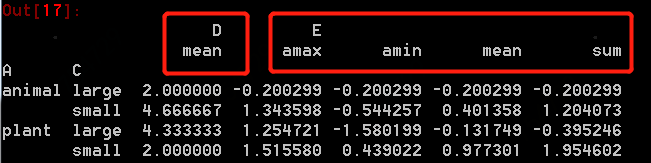
其中聚合函數可以更加豐富的擴展,使用多個。如下所示,兩個軸的交叉值選用D和E,聚合在D列使用np.mean(), 對E列使用np.sum, np.mean, np.max, np.min

得到結果如下所示:
函數原型

fill_value: 空值的填充值;
dropna: 如果某列元素都為np.nan, 是否丟棄;
margins: 匯總列, margins_name: 匯總名稱
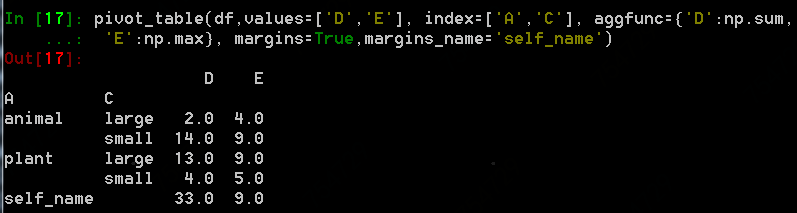
margins參數默認為False,如果設置為True,會得到每列的匯總,如下df實例

設置margins為True,匯總行索引為名稱自定義為self_name:
注意
margins設置為True后,目前pandas 0.22.3版本只支持聚合函數為單個元素,不支持為list的情況,如下:
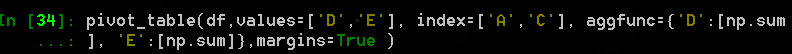
會報出異常:
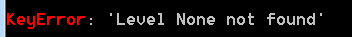
透過pivot_table聚合功能源碼(如下所示),我們發現它本身是通過調用groupby()及其agg()實現的。
grouped = data.groupby(keys, observed=False)agged = grouped.agg(aggfunc)
以上就是Python中怎么使用 pivot_table()實現數據透視功能,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





