溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關如何使用Antlr構建用戶篩選的DSL,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
隨著業務的發展,我們會積攢越來越多的用戶,為了能夠對用戶更精準的進行營銷,挖掘,或者統計,我們會對用戶進行打標,打標可以包含諸多維度,例如:
基礎信息:包括年齡段,性別等
訂單信息:例如,首次訂單時間,近30日訂單量,近7天訂單量等
券信息:近7日使用券次數
有了這些用戶標簽之后,我們可以對用戶進行篩選,創建人群,然后針對人群做一些有針對性的營銷活動,例如:
烏魯木齊低頻-滿送:((常駐城市==烏魯木齊)and (近7日成單數>0)and (近7日成單數 <6))
上海新注冊用戶-拉新:((注冊城市==上海) and (注冊時間距今天數 < 3))
這些活動都必須按照某些標簽來篩選用戶,因此,我們設計了一個用戶畫像系統,讓運營可以很方便的進行人群的創建和過濾,整體的結構如下:
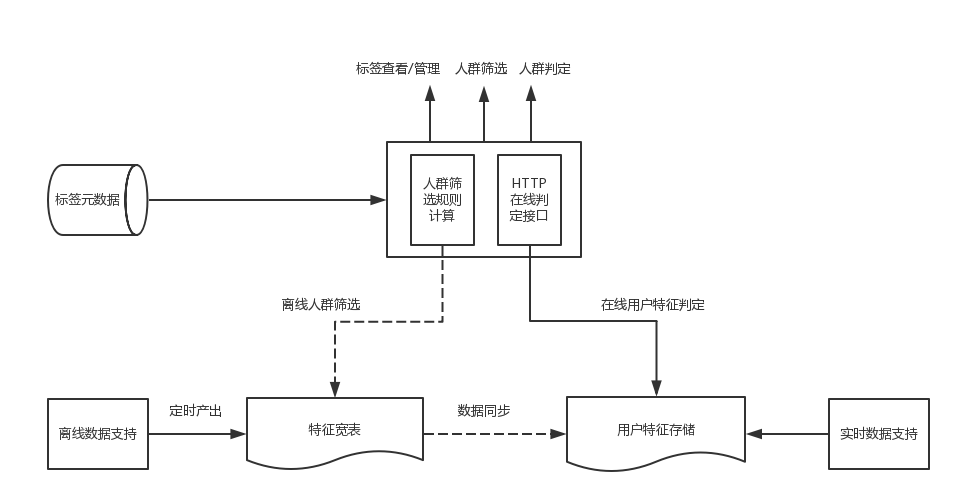
整個架構分為兩部分:
離線數據篩選:根據用戶輸入的各種規則篩選用戶,例如篩選規則:((常駐城市==烏魯木齊)and (近7日成單數>0)and (近7日成單數 <6))
在線用戶判定:給定一個用戶,判定該用戶是否滿足特定規則,例如,判斷當前用戶的注冊時間距今天數是否小于3天。
今天,我們就講一下用戶篩選的核心處理流程:篩選規則的解析和處理,整體流程如下圖:

規則處理模塊簡單說來就是將前端運營輸入的規則轉化為SQL。運營輸入的篩選規則就是我們的定制的DSL(domain-specific language),雖然簡單,但是可以依此為例,講一下借助于Antlr4來處理DSL的一般過程。
本文主要分為兩個部分:
第一部分講一下語法分析的基礎,里面會大概講一下自定義一個DSL的基本步驟,如何使用Antlr達到事半功倍的效果;
第二部分講一下我們是如何具體設計的,包括我們的DSL是怎么定義的,整個流程包含哪些步驟,以及一些我們的總結。
回憶一下大學的編譯原理,一門語言的處理流程基本包括:
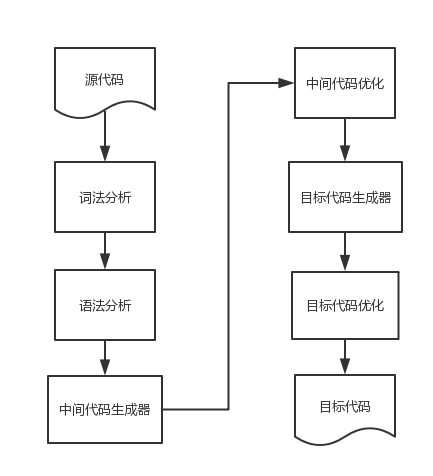
整個流程還是很復雜的,幸好我們不需要自己創造一門目標代碼,我們只需要將我們的DSL轉化為SQL,那么,流程會簡化很多。通過使用Antlr之后,前面的詞法分析和語法分析也可以節省大量工作:

借助于Antlr我們只需要定義文法文件,然后,通過對應的開發插件可以自動生成Antlr的處理程序,Antlr會完成詞法分析和語法分析,并提給給我們兩種遍歷抽象語法樹的能力:
Listener模式:Antlr默認的模式,被動的按照深度遍歷的方式訪問整個抽象語法樹
Visitor模式:需要顯式告訴Anltr創建Visitor,開發者可以主動控制遍歷整棵樹的過程
通過上面這兩種方式,我們就可以獲得抽象語法樹的結果,接下來,我們可以接收一個節點處理一個節點,類似于解釋執行,或者翻譯生成中間表示形式,類似于Java的Class文件。
這個地方有必要簡單說一下Antlr的文法文件,Antrl文法使用EBNF的方式定義,不支持左遞歸。一個文法文件的例子(不完整):

在定義文法文件的時候,可以自頂向下設計,逐漸拆分更細粒度的“語法”,然后,注意消除歧義,避免左遞歸。不過幸運的是,我們基本不需要自己從頭開始寫這么一個文法文件,Antlr已經給我們列舉了常見語言的文法文件,我們可以直接搬來使用,后面講到的我們的DSL,也是參考了JSON的文法文件。
更多的Antlr技術資料可以查看官方文檔,下面重點介紹下我們是如何定義DSL以及如何處理的。
既然是DSL,那么在設計的時候就必須考慮自己的業務場景,我們所面臨的需求主要包括:
方便運營通過拖拽的形式組合查詢規則
方便前端模塊化的組合查詢規則
方便跟公司其他業務線的規則進行整合
我們主要看看前面兩條的考慮,下面是我們產品設計的前端界面:
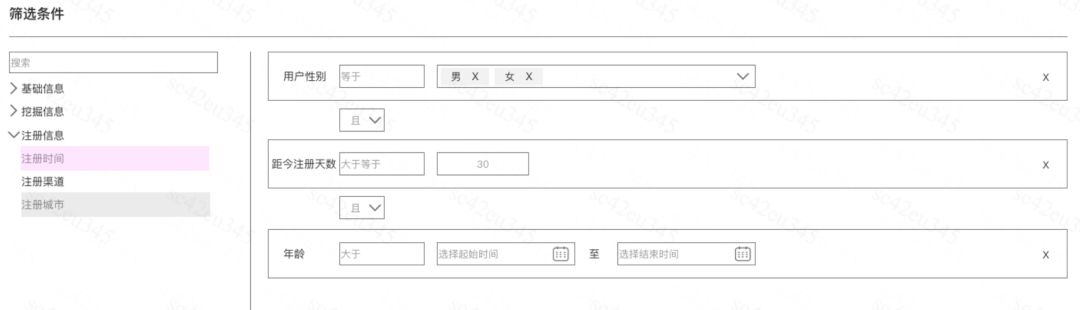
可以看出,整個規則篩選模塊也包括下面幾個部分:
條件組合:條件可以嵌套條件,或者嵌套一個具體規則對象
規則對象:具體的用戶標簽和標簽的取值范圍
基于上面的頁面組合方式,我們設計了我們的DSL,例如,我們想篩選出一線城市2018年來高頻用戶,組裝的規則如下:
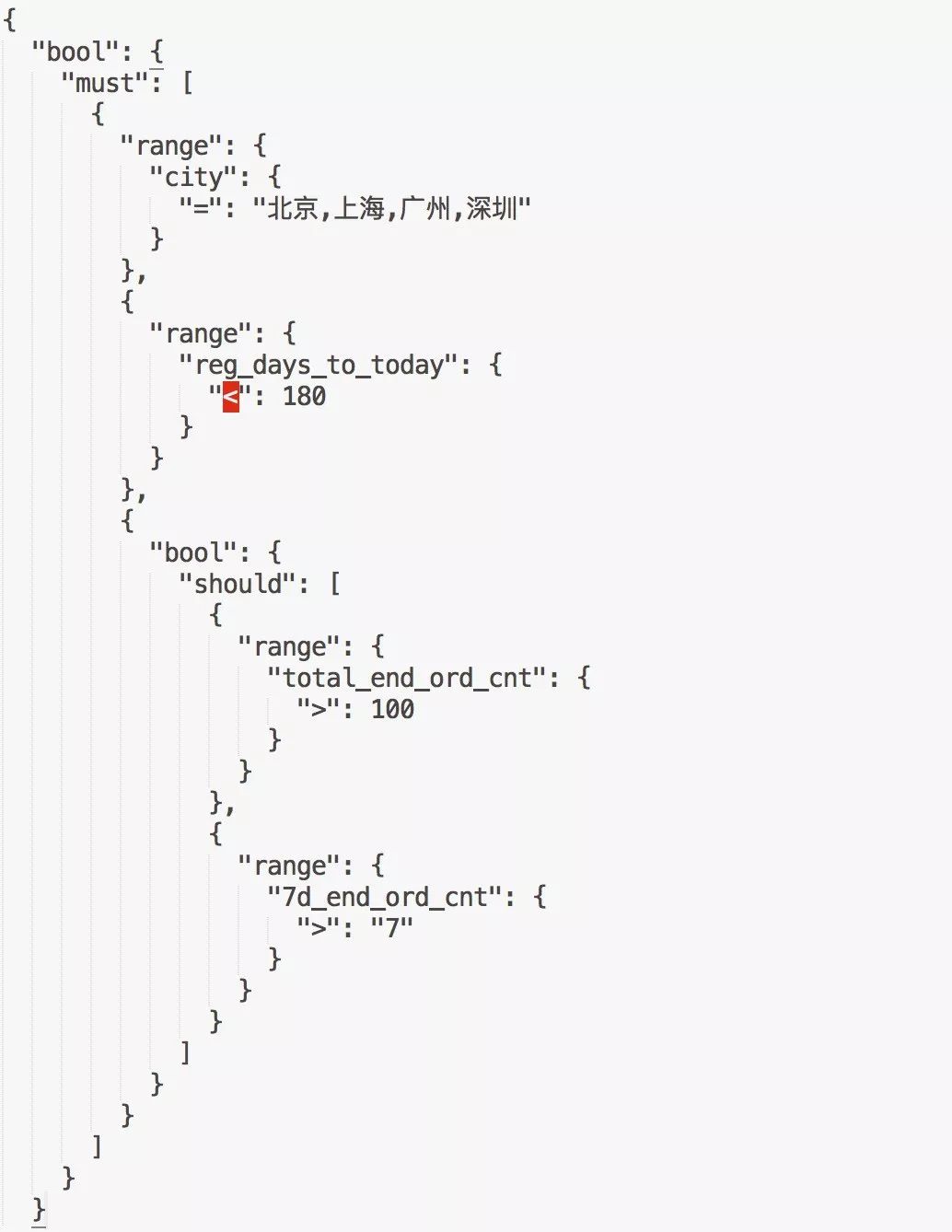
我們的文法文件如下(不完整):
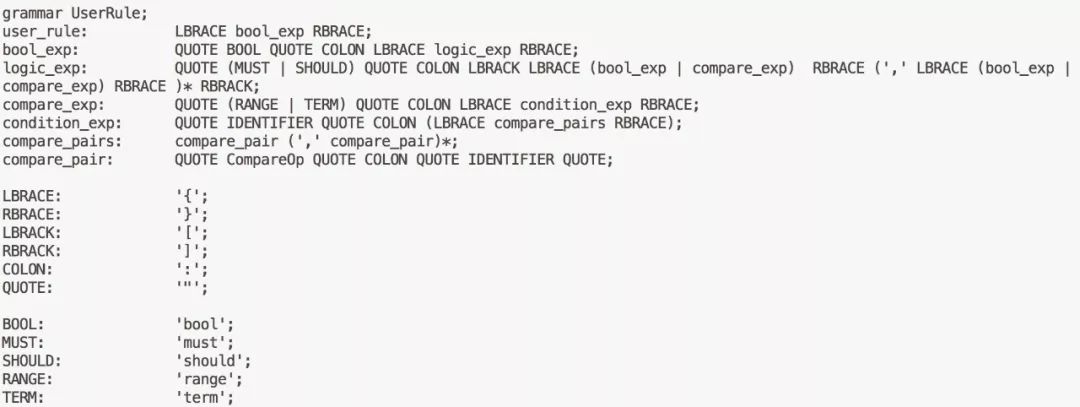
我們的DSL基于JSON語法,定義跟前端頁面的布局基本可以對應起來:
bool表達式:表示一個邏輯塊,可以是與的關系,也可以是或的關系,bool可以嵌套,也可以包含一個具體的篩選表達式
篩選表達式:包括篩選的標簽名字,篩選的條件,對應與頁面的一個篩檢模塊,不能包含子元素,必須按照特定的規則進行組裝
有了這套DSL之后,前端就可以比較方便的進行渲染和修改,最終會將運營通過拖拽創建的規則以JSON的形式交給后端處理。
接收到DSL規則后,系統按照下面的步驟進行處理:

在設計的時候,借助于語法分析的常規流程以及Java的編譯流程,我們抽象出來兩層中間結果的三層處理模型:
第一層:原始的Anltr處理模塊,將DSL規則轉化為GrammarNode。GrammarNode基本跟抽象語法樹保持一致,也是一顆樹形結構,里面包含了規則的原始信息:
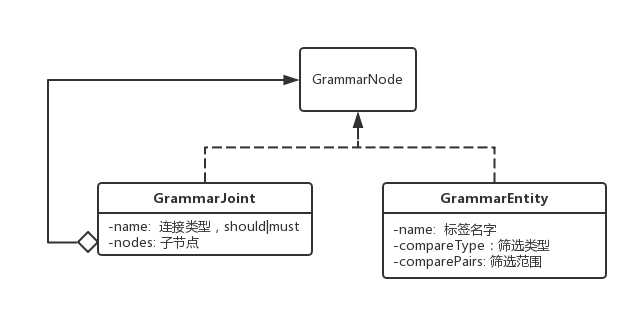
第二層:預處理模塊:預處理模塊反向依賴于一個MetaProvider。預處理模塊通過MetaProvider獲取每個標簽的Hive表信息,包括:表的名字,表的取數規則,字段類型等等,這一階段主要負責:
數據驗證:主要包括用戶輸入數據的合法性校驗
查詢條件的生成:基于單個標簽生成查詢條件,將最終的結果輸出成SqlNode的形式。

其中在SqlTableNode節點中是組合好的部分條件語句,形如下面的形式:
datediff(from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss'), regis_time) < 180
第三層:目標代碼生成器:也就是SQL生成器,這一層的輸入除了第二部的SqlNode之外,還包括公共的上下文參數,例如:篩選的日期(用于分區),最終篩選的字段(也就是select出來的參數)等。最終,通過深度優先的算法,將每棵子樹進行轉化和拼裝,形成完整SQL。可以看出來,每個小的condition都會使用'()'括起來,防止出現條件間邏輯錯亂。

事實上,中間結果的設計并不是一蹴而就的,而是在實際編碼的過程中,逐步抽象出來,最終演化成這樣一個流程。采用中間結果的方式有下面幾點好處:
隔離性比較好:GrammarNode對后面兩層屏蔽了頁面規則的變化,SqlNode對最后一層屏蔽了表結構的變化
流程復用:一個典型的場景就是,需要事先判斷滿足運營輸入規則的用戶數有多少。基于上面的流程就很簡單的,可以擴展的目標代碼生成器用于生成select count的sql語句。
雖然前端支持的篩選規則有限,例如,嵌套層級的限制等,但是我們的DSL可以做的很強大,在預處理模塊我們甚至還可以做一些優化性的工作,比如:
跨表join的時候,根據歷史數據評估每個表的數據量,讓小表join大表
屬于統一個表的篩選字段自動合并,而不是使用join
借助于Antlr,我們可以很方便的構建符合自己業務場景的DSL,所以,我們可以多思考有哪些業務領域,有哪些操作可以標準化起來,然后使用DSL來實現業務的描述和執行,既可以讓代碼簡潔清晰,又可以提高生產力。
看完上述內容,你們對如何使用Antlr構建用戶篩選的DSL有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





