溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

(1)MapReduce的發展:
MRv1的缺點:
早在 Hadoop1.x 版本,當時采用的是 MRv1 版本的 MapReduce 編程模型。MRv1 版本的實現 都封裝在 org.apache.hadoop.mapred 包中,MRv1 的 Map 和 Reduce 是通過接口實現的。
MRv1 只有三個部分: 運行時環境(JobTracker 和 TaskTracker)、編程模型(MapReduce)、 數據處理引擎(MapTask 和 ReduceTask)。可擴展性差:在運行時,JobTracker 既負責資源管理又負責任務調度,當集群繁忙時, JobTracker 很容易成為瓶頸,最終導致它的可擴展性問題。
可用性差:采用了單節點的 Master,沒有備用 Master 及選舉操作,這導致一旦 Master 出現故障,整個集群將不可用。(單點故障)
資源利用率低:TaskTracker 使用“slot”等量劃分本節點上的資源量。slot 分為 Map slot 和 Reduce slot 兩種,分別供 MapTask 和 ReduceTask 使用。有時會因為作業剛剛啟動等原因導致 MapTask 很多,而 Reduce Task 任 務還沒有調度的情況,這時 Reduce slot 也會被閑置。
不能支持多種MapReduce框架:無法通過可插拔方式將自身的 MapReduce 框架替換為其他實現,如 Spark、Storm 等。
2. MRv2的缺點:
MRv2中,重用了 MRv1 中的編程模型和數據處理引擎。但是運行時環境被重構了。JobTracker 被拆分成了通用的:資源調度平臺(ResourceManager,簡稱 RM)、節點管理器(NodeManager)、負責各個計算框架的任務調度模型(ApplicationMaster,簡稱 AM)。但是由于對 HDFS 的頻繁操作(包括計算結 果持久化、數據備份、資源下載及 Shuffle 等)導致磁盤 I/O 成為系統性能的瓶頸,因此只適用于離線數據處理或批處理,而不能支持對迭代式、交互式、流式數據的處理。
(2)Spark的優勢:
減少了磁盤的I/O:Spark 允許將 map 端的中間輸出和結果存儲在內存中,reduce 端在拉取中間結果時避免了大量的磁盤 I/O。Spark 將應用程序上傳的資源文件緩沖到 Driver 本地文件服務的內存中,當 Executor 執行任務時直接從 Driver 的內存 中讀取,也節省了大量的磁盤 I/O。
增加并行度:park 把不同的環節抽象為 Stage,允許多個 Stage 既可以串行執行,又可以并行執行。
避免重復計算:當 Stage 中某個分區的 Task 執行失敗后,會重新對此 Stage 調度,但在重新 調度的時候會過濾已經執行成功的分區任務,所以不會造成重復計算和資源浪費。
可選擇的shuffle:Spark 可以根據不同場景選擇在 map 端排序或者 reduce 端排序。
靈活的內存管理策略:Spark 將內存分為堆上的存儲內存、堆外的存儲內存、堆上的執行內存、堆外的執行內存 4 個部分。Spark 既提供了執行內存和存儲內存之間是固定邊界的實現,又提供了執行內存和存儲內存之間是“軟”邊界的實現。Spark 默認使用“軟”邊界的實現,執行內存或存儲內存中的任意一方在資源不足時都可以借用另一方的內存,最大限度的提高 資源的利用率,減少對資源的浪費。。Spark 由于對內存使用的偏好,內存資源的多寡和使用 率就顯得尤為重要,為此 Spark 的內存管理器提供的 Tungsten 實現了一種與操作系統的內存 Page 非常相似的數據結構,用于直接操作操作系統內存,節省了創建的 Java 對象在堆中占 用的內存,使得 Spark 對內存的使用效率更加接近硬件。Spark 會給每個 Task 分配一個配套 的任務內存管理器,對 Task 粒度的內存進行管理。Task 的內存可以被多個內部的消費者消費,任務內存管理器對每個消費者進行 Task 內存的分配與管理,因此 Spark 對內存有著更細粒度的管理
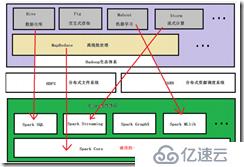
(3)spark生態:
Spark 生態圈以 SparkCore 為核心,從 HDFS、Amazon S3 或者 HBase 等持久層讀取數據,以 MESOS、YARN 和自身攜帶的 Standalone 為資源管理器調度 Job 完成 Spark 應用程序的計算。
SparkShell/SparkSubmit 的批處理
SparkStreaming 的實時處理應用
SparkSQL 的結構化數據處理/即席查詢
BlinkDB 的權衡查詢
MLlib/MLbase的機器學習、GraphX的圖處理和PySpark的數學/科學計算和SparkR的數據分析。
(4)spark特點:
Seed快速高效:Spark 允許將中間輸出和結果存儲在內存中,節省了大量的磁盤 IO。Apache Spark 使用最先進的 DAG 調度程序,查詢優化程序和物理執行引擎,實現批量和流式數據的高性能。同時 Spark 自身的 DAG 執行引擎也支持數據在內存中的計算。Spark 官網聲稱性能比 Hadoop 快 100 倍。即便是內存不足需要磁盤 IO,其速度也是 Hadoop 的 10 倍以上
Generality:全棧式數據處理:支持批處理、支持交互式查詢、支持交互式查詢、支持機器學習、支持圖計算。
Ease of Use 簡潔易用:Spark 現在支持 Java、Scala、Python 和 R 等編程語言編寫應用程序,大大降低了使用者的門檻。自帶了 80 多個高等級操作符(算子),允許在 Scala,Python,R 的 shell 中進行交互式查詢,可 以非常方便的在這些 Shell 中使用 Spark 集群來驗證解決問題的方法。
可用性高:Spark 也可以不依賴于第三方的資源管理和調度器,它實現了 Standalone 作為其 內置的資源管理和調度框架,這樣進一步降低了 Spark 的使用門檻,使得所有人都可以非常 容易地部署和使用 Spark,此模式下的 Master 可以有多個,解決了單點故障問題。當然,此模式也完全可以使用其他集群管理器替換,比如 YARN、Mesos、Kubernetes、EC2 等。
豐富的數據源支持:Spark 除了可以訪問操作系統自身的本地文件系統和 HDFS 之外,還可 以訪問 Cassandra、HBase、Hive、Tachyon(基于內存存儲) 以及任何 Hadoop 的數據源。這極大地方便了已經 使用 HDFS、HBase 的用戶順利遷移到 Spark。
(5)spark的應用場景:
① Yahoo 將 Spark 用在 Audience Expansion 中的應用,進行點擊預測和即席查詢等
② 淘寶技術團隊使用了 Spark 來解決多次迭代的機器學習算法、高計算復雜度的算法等。 應用于內容推薦、社區發現等
③ 騰訊大數據精準推薦借助 Spark 快速迭代的優勢,實現了在“數據實時采集、算法實時訓練、系統實時預測”的全流程實時并行高維算法,最終成功應用于廣點通 PCTR 投放 系統上。
優酷土豆將 Spark 應用于視頻推薦(圖計算)、廣告業務,主要實現機器學習、圖計算等 迭代計算。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。