溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關Spark-Alchemy中HyperLogLog如何使用,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
Reaggregation的成立存在先決條件, 預先計算的維度可以再次進行聚合, 在字典釋義中聚合表示可聚合性,通過進一步擴展該語義來解釋reaggregation - 具有可以再次進行聚合的聚合, 求和,最大值,最小值都是可以reaggregation的, 但是distinct count是不支持reaggregation的,主要因為存在二次計數的問題, 統計每個網站的訪問人數的總和并不等于訪問網站的總人數,這是由于單個訪問者可以訪問多個網站。
這種不可重新聚合的特性使得計算distinct count的系統必須訪問最細粒度的數據,因此每個查詢需要訪問每一行數據去統計distinct count。
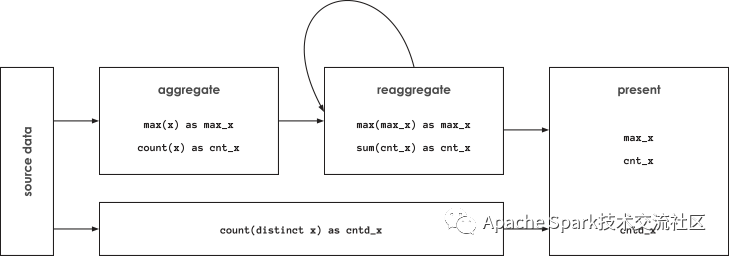
在大數據領域, distinct counts存在另外一個問題,在計算過程需要的內存大小是更需要統計不同結果集的大小成正比的,為了避免上述問題,近年來一些大數據平臺如Apache Spark 以及面向分析的數據庫如Amazon RedShift引入基數估計的算法,該算法使用HyperLogLog(HLL)去估計distinct counts, 在spark 中如果要使用基數估計算法,只要使用approx_count_distinct(x [, rsd])代替COUNT(DISTINCT x)就可以運行, 其中可選參數rsd代表可以容忍的誤差, 在databricks的測試報告, HLL的聚合性能可以達到精確計算distinct count性能的2-8倍,誤差率保持在1%以上,用戶可以追求更高精度,但是HLL算法的運行時間可能要比精確計算distinct count時間更長。
2-8倍性能的提升的代價是誤差率始終保持在1%以上, 這在某些場景下是不可接受的, 此外在預先聚合能帶來1000倍的性能提升面前, 2-8倍性能顯得微不足道, 對此我們能做些什么?下面首先介紹下HLL算法。
HLL算法在Spark 處理流程可以分為以下幾個部分
Map階段
初始化HLL sketch數據結構
為每個HLL sketch加入輸入
發送HLL sketch
Reduce
合并所有的HLL sketches到聚合的sketch
Finalize
HLL sketch是支持reaggreation, reduce階段合并產生的依舊是HLL sketch,用戶可以序列化該結果,并將該結果持久化存儲,作為預先聚合的一部分,為后續計算distinct count提供輸入,這樣就可以帶來1000倍的提升。
從聚合的sketch中計算出distinct count的估計值
這種方法還能另外一種好處,通過該方法用戶可以將誤差率控制1%以內,由于預先聚合可以帶來1000倍的提升,我們可以花費更長的時間來計算HLL以便達到更小的誤差率,在預先聚合階段,花費2-5倍的計算預先聚合時間是可以接受的, 對大多數用戶而言,性能提升的同時基本沒有任何其他方面的犧牲。
由于Spark社區不支持HLL功能,Swoop將這部分功能作為spark-alchemy庫的一部分進行開源,用戶可以參照HLL文檔提供的樣例, 相比BigQuery的HLL支持,Spark alchemy提供了更加豐富的功能。
下圖顯示spark alchemy HLL是如何處理聚合的初始化(hll_init_agg), 重新聚合(hll_merg) 以及最后結果的展示(hll_cardinality)
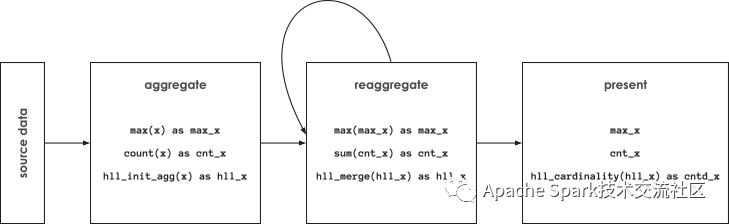
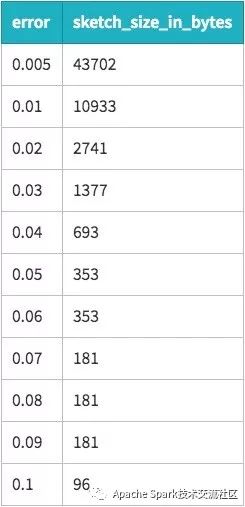
如果用戶擔心HLL sketches的存儲開銷, 通過以下規則可以進行簡單的估算:精度提高2倍, HLL sketches的存儲開銷將會提升4倍, 在大部分應用程序中,記錄數目的減少帶來的存儲開銷的減少遠遠超過HLL sketch增加的開銷
HyperLogLog互操作性
Distinct count精確計算以及估算模式的相互切換以及將HLL sketches保存為列式數據可以避免用戶在查詢的時候遍歷所有記錄數據, 但是系統在準備HLL數據的時候還是需要訪問所有的記錄數據。此外對于HLLsketches的序列化業界也沒有統一的標準,所以HLL的數據在不同的系統中不能夠共享, 這種互操作性的不便利性增加交互分析系統的分析成本以及復雜度。
交互式分析系統要求快速的響應時間,但是這個要求不是大數據系統核心的設計目標,這就是為什么現在交互式分析還運行在在關系型或者NoSQL數據庫上的原因,沒有HLL sketches的互操作性便利,用戶可能在交互式查詢還是使用原有的方式。
為了解決這個問題, spark alchemey在開發HLL相關功能時,提供了一種存儲格式以及原生支持Postgres兼容的數據庫, 這樣對于要求快速響應時間的系統而言, spark就可以作為數據預處理統一平臺, 這種架構的好處如下
99%以上的數據通過spark進行管理,沒有副本
99%以上處理發生在spark支持,包括預先聚合
交互式查詢性能更高以及需要的資源更少
以上就是Spark-Alchemy中HyperLogLog如何使用,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





