溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“JVM+Redis+SpringBoot的面試題有哪些”,在日常操作中,相信很多人在JVM+Redis+SpringBoot的面試題有哪些問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”JVM+Redis+SpringBoot的面試題有哪些”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
加載:把.java文件編譯成.class文件,生成Class對象 驗證:驗證字節碼的準確性 準備:給類的靜態變量做分配內存,并賦予默認值 解析:符號引用和動態鏈接都變為直接引用 初始化:給類的靜態變量初始化為指定的值,執行靜態代碼塊
1、根類加載器(Bootstrap classLoader):負責加載lib下的核心類庫2、擴展加載器(ExtClassLoader):負責加載lib目錄下的ext的jar類包3、應用加載器(AppClassLoader):負責加載ClassPath路勁下的類包(自定義的類)4、自定義類加載器:繼承ClassLoader,重寫loadClass(),findClass(),一般是只需要重寫findClass
雙親加載機制中源碼有兩個方法:1、loadClass 1)先檢查指定的類是否已經加載過了,若已經加載過,則直接返回加載的類 2)若沒有加載,則判斷有沒有父類,有的話則調用父類加載器,或者調用根類加載器(Bootstrap)加載。 3)若父類加載器與Bootstrap加載器都沒有找到指定的類,則調用下面的方法(findClass)來完成類加載2、findClass
1、保證類的唯一性2、沙箱安全機制
如果沒有顯示的使用其他類加載器,則類下的所有依賴與及引用的類都將會有加載該類的類加載器加載
1、CommonLoader:Tomcat最基本的類加載器,加載路徑中的class可以被Tomcat容器本身以及各個Webapp訪問;2、CatalinaLoader:Tomcat容器私有的類加載器,加載路徑中的class對于Webapp不可見;3、SharedLoader:各個Webapp共享的類加載器,加載路徑中的class對于所有Webapp可見,但是對于Tomcat容器不可見;4、WebappClassLoader:各個Webapp私有的類加載器,加載路徑中的class只對當前Webapp可見,比如加載war包里相關的類, 每個war包應用都有自己的WebappClassLoader,實現相互隔離,比如不同war包應用引入了不同的spring版本,這樣實現就能加載各自的spring版本;5、模擬實現Tomcat的JasperLoader熱加載 原理:后臺啟動線程監聽jsp文件變化,如果變化了找到該jsp對應的servlet類的加載器引用(gcroot),重新生成新的JasperLoader加載器賦值給引用,然后加載新的jsp對應的servlet類,之前的那個加載器因為沒有gcroot引用了,下一次gc的時候會被銷毀 =>總結:每個webappClassLoader加載自己的目錄下的class文件,不會傳遞給父類加載器,打破了雙親委派機制。
私有: 程序計時器:記錄當前線程執行到字節碼行號 虛擬機棧:內部有許多棧幀,每個棧幀里面包括局部變量表,操作數棧,動態鏈接,方法出口。 本地方法棧:執行本地的Native方法 共享: 堆:內部分為eden區,s0,s1,老年代,保存對象和數組 方法區/永久代(1.8后元空間):保存類信息、常量、靜態變量、即時編譯器編譯后的代碼;內部有個運行時常量池,用于保存類的版本、字段、方法、接口等; 擴展=>直接內存:通過unsafe,或者netty的DirectByteBuffer申請
1、類加載檢查
虛擬機遇到一條new指令時,首先將去檢查這個指令的參數是否能在常量池中定位到一個類的符號引用,并且檢查這個符號引用代表的類是否已被加載、解析和初始化過。如果沒有,那必須先執行相應的類加載過程。 new指令對應到語言層面上講是,new關鍵詞、對象克隆、對象序列化等2、分配內存
//劃分內存 1、指針碰撞 內存規整,用過的內存放一邊,沒用過的放一邊2、空閑列表 內存不規整,使用的和空閑的相互交錯,需要一個列表進行存儲//并發問題解決1、CAS2、本地線程分配緩沖區(TLAB)把內存分配的動作按照線程劃分在不同的空間之中進行,即每個線程在Java堆中預先分配一小塊內存。通過XX:+/-UseTLAB參數來設定虛擬機是否使用TLAB(JVM會默認開啟XX:+UseTLAB),XX:TLABSize指定TLAB大小。3、初始化
為分配到的內存初始化為零值,不設置對象頭,若是呀TLAB,可以提前至TLAB分配時進行,保證對象即使不賦初始值也可以直接使用4、設置對象頭
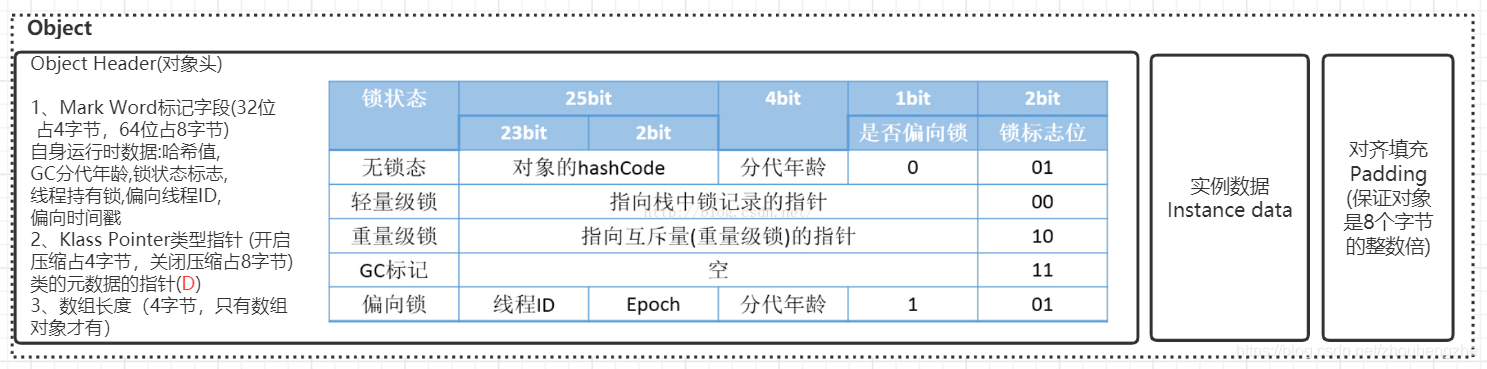
對象布局:1、對象頭(Header)2、實例數據(Instance Data)3、對齊填充(Padding)
5、執行方法
執行<init>方法,也就是所謂的屬性賦值與執行構造器
1、棧上分配 通過逃逸分析確定該對象不會被外部訪問。如果不會逃逸可以將該對象在棧上分配內存,這樣該對象所占用的內存空間就可以隨棧幀出棧而銷毀,就減輕了垃圾回收的壓力。/** *對象逃逸分析:分析對象動態作用域,當一個對象在方法中被定義后,它可能被外部方法所引用,例如作為調用參數傳遞到其他地方中 *標量替換:通過逃逸分析確定該對象不會被外部訪問,并且對象可以被進一步分解時,JVM不會創建該對象,而是將該對象成員變量分解若干個被這個方法使用的成員變量所 代替,這些代替的成員變量在棧幀或寄存器上分配空間,這樣就不會因為沒有一大塊連續空間導致對象內存不夠分配 */'結論:棧上分配依賴于逃逸分析和標量替換'2、堆上分配(eden區) 1、先eden區分配,滿了young GC,把存活的對象放入s02、再eden區分配,滿了young GC,把s0存活的對象和eden區存活的對象放入s1,3、重復1,2操作3、大對象進入老年代 大量連續的內存空間的對象4、長期存活對象進入老年代 在2(堆上分配)中,每次移動都會給當前對象設置個計數器,默認15,CMS默認6,則會young gc放入老年代5、對象動態年齡判斷 當一批對象的總大小大于s區內存大小的50%,則大于等于這批對象年齡最大值的對象,就可以進入老年代6、空間擔保機制 年輕代每次young gc之前JVM都會計算下老年代剩余可用空間,如果這個可用空間小于年輕代里現有的所有對象大小之和(包括垃圾對象),就會看一個“-XX:-HandlePromotionFailure”(jdk1.8默認就設置了) 的參數是否設置了,如果有這個參數,就會看看老年代的可用內存大小,是否大于之前每一次minor gc后進入老年代的對象的平均大小。小于或者之前說的參數沒有設置,那么就會觸發一次Full gc,對老年代和年輕代一起回收一次垃圾,如果回收完還是沒有足夠空間存放新的對象就會發生"OOM"。
1、該類所有的實例都已經被回收,也就是 Java 堆中不存在該類的任何實例。2、加載該類的 ClassLoader 已經被回收。3、該類對應的 java.lang.Class 對象沒有在任何地方被引用,無法在任何地方通過反射訪問該類的方法。
1. 第一次標記并進行一次篩選。 篩選的條件是此對象是否有必要執行finalize()方法。 當對象沒有覆蓋finalize方法,對象將直接被回收。2. 第二次標記 如果這個對象覆蓋了finalize方法,finalize方法是對象脫逃死亡命運的最后一次機會,如果對象要在finalize()中成功拯救 自己,只要重新與引用鏈上的任何的一個對象建立關聯即可,譬如把自己賦值給某個類變量或對象的成員變量,那在第 二次標記時它將移除出“即將回收”的集合。如果對象這時候還沒逃脫,那基本上它就真的被回收了。//注意:一個對象的finalize()方法只會被執行一次,也就是說通過調用finalize方法自我救命的機會就一次。
1、強引用:普通的變量引用2、軟引用(SoftReference):將對象用SoftReference軟引用類型的對象包裹,正常情況不會被回收,但是GC做完后發現釋放不出空間存放新的對象,則會把這些軟引用的對象回收掉。軟引用可用來實現內存敏感的高速緩存。 //使用場景:瀏覽器的后退按鈕3、弱引用(WeakReference):將對象用WeakReference軟引用類型的對象包裹,弱引用跟沒引用差不多,GC會直接回收掉,很少用4、虛引用:虛引用也稱為幽靈引用或者幻影引用,它是最弱的一種引用關系,幾乎不用
1、引用計數法:循環引用無法解決2、Gc root算法 將“GC Roots” 對象作為起點,從這些節點開始向下搜索引用的對象,找到的對象都標記為非垃圾對象,其余未標記的對象都是垃圾對象 GC Roots根節點:線程棧的本地變量、靜態變量、本地方法棧的變量等等
1、標記復制算法//定義:將內存分兩塊,每使用一塊,都會在內存用完之后,將存活的對象復制到另一塊中,再把使用過的空間清理//問題:浪費空間,永遠浪費一半空間2、標記清除算法//定義:標記存活對象,統一回收未被標記的對象//問題:1、效率問題:效率不高,對象過多,就要浪費時間標記對象 2、空間問題:產生大量的不連續的碎片3、標記整理算法 跟標記清除一樣,多了個整理存活對象的過程4、分代收集算法 年輕代復制算法,老年代標記整理
1、初始標記: 暫停所有的其他線程(STW),并記錄下gc roots直接能引用的對象,速度很快。2、并發標記: 并發標記階段就是從GC Roots的直接關聯對象開始遍歷整個對象圖的過程, 這個過程耗時較長但是不需要停頓用戶線程, 可以與垃圾收集線程一起并發運行。因為用戶程序繼續運行,可能會有導致已經標記過的對象狀態發生改變。3、重新標記: 重新標記階段就是為了修正并發標記期間因為用戶程序繼續運行而導致標記產生變動的那一部分對象的標記記錄,這個階段的停頓時間一般會比初始標記階段的時間稍長,遠遠比并發標記階段時間短。主要用到'增量更新算法'做重新標記。4、并發清理: 開啟用戶線程,同時GC線程開始對未標記的區域做清掃。這個階段如果有新增對象會被標記為`三色標記法`里面的黑色不做任何處理5、并發重置:重置本次GC過程中的標記數據。
黑色:'表示對象已經被垃圾收集器訪問過',且這個對象的所有引用都已經掃描過。黑色的對象代表已經掃描過, 它是安全存活的,如果有其他對象引用指向了黑色對象,無須重新掃描一遍。黑色對象不可能直接(不經過灰色對象)指向某個白色對象。 灰色:'表示對象已經被垃圾收集器訪問過',但這個對象上至少存在一個引用還沒有被掃描過。 白色:'表示對象尚未被垃圾收集器訪問過'。顯然在可達性分析剛剛開始的階段,所有的對象都是白色的,若在分析結束的階段,仍然是白色的對象,即代表不可達。
1、增量更新(Incremental Update)+寫屏障 增量更新就是當黑色對象插入新的指向白色對象的引用關系時, 就將這個新插入的引用記錄下來, 等并發掃描結束之后, 再將這些記錄過的引用關系中的黑色對象為根, 重新掃描一次。 這可以簡化理解為, 黑色對象一旦新插入了指向白色對象的引用之后, 它就變回灰色對象了。2、原始快照(Snapshot At The Beginning,SATB)+寫屏障 原始快照就是當灰色對象要刪除指向白色對象的引用關系時, 就將這個要刪除的引用記錄下來, 在并發掃描結束之后,再將這些記錄過的引用關系中的灰色對象為根, 重新掃描一次,這樣就能掃描到白色的對象,將白色對象直接標記為黑色(目的就是讓這種對象在本輪gc清理中能存活下來,待下一輪gc的時候重新掃描,這個對象也有可能是浮動垃圾)以上無論是對引用關系記錄的插入還是刪除, 虛擬機的記錄操作都是通過寫屏障實現的。
初始標記(initial mark,STW):暫停所有的其他線程,并記錄下gc roots直接能引用的對象,速度很快 并發標記(Concurrent Marking):并發標記階段就是從GC Roots的直接關聯對象開始遍歷整個對象圖的過程, 這個過程耗時較長但是不需要停頓用戶線程, 可以與垃圾收集線程一起并發運行。因為用戶程序繼續運行,可能會有導致已經標記過的對象狀態發生改變。 最終標記(Remark,STW):重新標記階段就是為了修正并發標記期間因為用戶程序繼續運行而導致標記產生變動的那一部分對象的標記記錄,這個階段的停頓時間一般會比初始標記階段的時間稍長,遠遠比并發標記階段時間短。主要用到'增量更新算法'做重新標記。 篩選回收(Cleanup,STW):篩選回收階段首先對各個Region的==回收價值和成本進行排序,根據用戶所期望的GC停頓時間(可以用JVM參數 -XX:MaxGCPauseMillis指定)來制定回收計劃
'已記憶集合RememberedSets:', 存儲著其他分區中的對象對本分區對象的引用,每個分區有且只有一個RSet。用于提高GC效率。 YGC時,GC root主要是兩類:棧空間和老年代分區到新生代分區的引用關系。所以記錄老年代分區對新生代分區的引用 Mixed GC時,由于僅回收部分老年代分區,老年代分區之間的引用關系也將被使用。所以記錄老年代分區之間的引用 因此,我們僅需要記錄兩種引用關系:老年代分區引用新生代分區,老年代分區之間的引用。 因為每次GC都會掃描所有young區對象,所以RSet只有在掃描old引用young,old引用old時會被使用。'卡表,Card Table:'Java堆劃分為相等大小的一個個區域,這個小的區域(一般size在128-512字節)被當做Card,而Card Table維護著所有的Card。Card Table的結構是一個字節數組,Card Table用單字節的信息映射著一個Card。當Card中存儲了對象時,稱為這個Card被臟化了(dirty card)。 對于一些熱點Card會存放到Hot card cache。同Card Table一樣,Hot card cache也是全局的結構。
Collect Set(CSet)是指,在Evacuation階段,由G1垃圾回收器選擇的待回收的Region集合。G1垃圾回收器的軟實時的特性就是通過CSet的選擇來實現的。對應于算法的兩種模式fully-young generational mode和partially-young mode,CSet的選擇可以分成兩種: 在fully-young generational mode下:顧名思義,該模式下CSet將只包含young的Region。G1將調整young的Region的數量來匹配軟實時的目標; 在partially-young mode下:該模式會選擇所有的young region,并且選擇一部分的old region。old region的選擇將依據在Marking cycle phase中對存活對象的計數。G1選擇存活對象最少的Region進行回收。
Marking bitmap是一種數據結構,其中的每一個bit代表的是一個可用于分配給對象的起始地址 bitmap 其中addrN代表的是一個對象的起始地址。綠色的塊代表的是在該起始地址處的對象是存活對象,而其余白色的塊則代表了垃圾對象。 G1使用了兩個bitmap,一個叫做previous bitmap,另外一個叫做next bitmap。previous bitmap記錄的是上一次的標記階段完成之后的構造的bitmap;next bitmap則是當前正在標記階段正在構造的bitmap。在當前標記階段結束之后,當前標記的next bitmap就變成了下一次標記階段的previous bitmap。TAMS(top at mark start)變量,是一對用于區分在標記階段新分配對象的變量,分別被稱為previous TAMS和next TAMS。在previous TAMS和next TAMS之間的對象則是本次標記階段時候新分配的對象。 previous TMAS 和 next TAMS 白色region代表的是空閑空間,綠色region代表是存活對象,橙色region代表的在此次標記階段新分配的對象。注意的是,在橙色區域的對象,并不能確保它們都事實上是存活的。
組成
GC信息保存在指針中。 每個對象有一個64位指針,這64位被分為18位:預留給以后使用1位:Finalizable標識,此位與并發引用處理有關,它表示這個對象只能通過finalizer才能訪問1位:Remapped標識,設置此位的值后,對象未指向relocation set中(relocation set表示需要GC的Region集合)1位:Marked1標識1位:Marked0標識,和上面的Marked1都是標記對象用于輔助GC42位:對象的地址(所以它可以支持2^42=4T內存)
優勢:
一旦某個Region的存活對象被移走之后,這個Region立即就能夠被釋放和重用掉,而不必等待整個堆中所有指向該Region的引用都被修正后才能清理,這使得理論上只要還有一個空閑Region,ZGC就能完成收集。 顏色指針可以大幅減少在垃圾收集過程中內存屏障的使用數量,ZGC只使用了讀屏障。 顏色指針具備強大的擴展性,它可以作為一種可擴展的存儲結構用來記錄更多與對象標記、重定位過程相關的數據,以便日后進一步提高性能。
1使用top命令查看cpu占用資源較高的PID2、通過jps 找到當前用戶下的java程序PID(jps -l 能夠打印出所有的應用的PID)3、使用 pidstat -p4、找到cpu占用較高的線程TID5、將TID轉換為十六進制的表示方式6、通過jstack -l(使用jstack 輸出當前PID的線程dunp信息)7、 查找 TID對應的線程(輸出的線程id為十六進制),找到對應的代碼
JIT是一種提高程序運行效率的方法。通常,程序有兩種運行方式:靜態編譯與動態解釋。靜態編譯的程序在執行前全部被翻譯為機器碼,而動態解釋執行的則是一句一句邊運行邊翻譯。
逃逸分析是指在某個方法之內創建的對象,除了在方法體之內被引用之外,還在方法體之外被其它變量引用到;這樣帶來的后果是在該方法執行完畢之后,該方法中創建的對象將無法被GC回收,由于其被其它變量引用。正常的方法調用中,方法體中創建的對象將在執行完畢之后,將回收其中創建的對象;故由于無法回收,即成為逃逸。
1、環形數組結構: 為了避免垃圾回收,采用數組而非鏈表。同時,數組對處理器的緩存機制更加友好(CPU加載空間局部性原則)。2、元素位置定位: 數組長度2^n,通過位運算,加快定位的速度。下標采取遞增的形式。不用擔心index溢出的問題。index是long類型,即使100萬QPS的處理速度,也需要30萬年才能用完。3、無鎖設計: 每個生產者或者消費者線程,會先申請可以操作的元素在數組中的位置,申請到之后,直接在該位置寫入或者讀取數據
框架使用RingBuffer來作為隊列的數據結構,RingBuffer就是一個可自定義大小的環形數組。除數組外還有一個序列號(sequence),用以指向下一個可用的元素,供生產者與消費者使用
1、RingBuffer——Disruptor底層數據結構實現,核心類,是線程間交換數據的中轉地;2、Sequencer——序號管理器,生產同步的實現者,負責消費者/生產者各自序號、序號柵欄的管理和協調,Sequencer有單生產者,多生產者兩種不同的模式,里面實現了各種同步的算法;3、Sequence——序號,聲明一個序號,用于跟蹤ringbuffer中任務的變化和消費者的消費情況,disruptor里面大部分的并發代碼都是通過對Sequence的值同步修改實現的,而非鎖,這是disruptor高性能的一個主要原因;4、SequenceBarrier——序號柵欄,管理和協調生產者的游標序號和各個消費者的序號,確保生產者不會覆蓋消費者未來得及處理的消息,確保存在依賴的消費者之間能夠按照正確的順序處理, Sequence Barrier是由Sequencer創建的,并被Processor持有;5、EventProcessor——事件處理器,監聽RingBuffer的事件,并消費可用事件,從RingBuffer讀取的事件會交由實際的生產者實現類來消費;它會一直偵聽下一個可用的號,直到該序號對應的事件已經準備好。6、EventHandler——業務處理器,是實際消費者的接口,完成具體的業務邏輯實現,第三方實現該接口;代表著消費者。7、Producer——生產者接口,第三方線程充當該角色,producer向RingBuffer寫入事件。8、Wait Strategy:Wait Strategy決定了一個消費者怎么等待生產者將事件(Event)放入Disruptor中。
1、BlockingWaitStrategy Disruptor的默認策略是BlockingWaitStrategy。在BlockingWaitStrategy內部是使用鎖和condition來控制線程的喚醒。BlockingWaitStrategy是最低效的策略,但其對CPU的消耗最小并且在各種不同部署環境中能提供更加一致的性能表現。2、SleepingWaitStrategy SleepingWaitStrategy 的性能表現跟 BlockingWaitStrategy 差不多,對 CPU 的消耗也類似,但其對生產者線程的影響最小,通過使用LockSupport.parkNanos(1)來實現循環等待。一般來說Linux系統會暫停一個線程約60μs,這樣做的好處是,生產線程不需要采取任何其他行動就可以增加適當的計數器,也不需要花費時間信號通知條件變量。但是,在生產者線程和使用者線程之間移動事件的平均延遲會更高。它在不需要低延遲并且對生產線程的影響較小的情況最好。一個常見的用例是異步日志記錄。3、YieldingWaitStrategy YieldingWaitStrategy是可以使用在低延遲系統的策略之一。YieldingWaitStrategy將自旋以等待序列增加到適當的值。在循環體內,將調用Thread.yield(),以允許其他排隊的線程運行。在要求極高性能且事件處理線數小于 CPU 邏輯核心數的場景中,推薦使用此策略;例如,CPU開啟超線程的特性。4、BusySpinWaitStrategy 性能最好,適合用于低延遲的系統。在要求極高性能且事件處理線程數小于CPU邏輯核心數的場景中,推薦使用此策略;例如,CPU開啟超線程的特性。
單線程寫數據的流程: 1、申請寫入m個元素; 2、若是有m個元素可以入,則返回最大的序列號。這兒主要判斷是否會覆蓋未讀的元素; 3、若是返回的正確,則生產者開始寫入元素。
1. 啟動ApplicationContext 兩個重要的子類: AnnotationConfigApplicationContext(用的最多) ClassPathXmlApplicationContext2. 初始化AnnotationBeanDefinitionReader a.讀取spring內部的初始的 beanFactoryPostProcess 和 其他的幾種 beanPostProcess(AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry)) 1. AnnotationAwareOrderComparator:解析@Order進行排序 2. ContextAnnotationAutowireCandidateResolver 3. ConfigurationClassPostProcessor:解析加了@Configuration、@ComponentScan、@ComponentScans、@Import等注解(最重要的類) 4. AutowiredAnnotationBeanPostProcessor:解析@Autowired5. RequiredAnnotationBeanPostProcessor:解析@Required6. CommonAnnotationBeanPostProcessor:負責解析@Resource、@WebServiceRef、@EJB7. EventListenerMethodProcessor:找到@EventListener8. DefaultEventListenerFactory:解析@EventListener b. 在ConfigurationClassPostProcessor類中有主要是為了解析加了@Configuration、@ComponentScan、@ComponentScans、@Import等注解,在這里面他有一個細節,就是加了@Configuration里面,他會把當前類標注成full類,就會產生一個aop的動態代理去加載當前類,沒有的話就把當前類標注成lite類,也就是普通類處理。3. 初始化ClassPathBeanDefinitionScanner a. 程序員能夠在外部調用doScan(), 或者 繼承該類可以重寫scan規則用來動態掃描注解,需要注冊到容器。 b. spring內部是自己重新new 新的對象來掃描。4. 執行register()方法,一般來說就是注冊我們的配置類 a. 先把此實體類型轉換為一個BeanDefinition5. 執行refresh(),先初始化比如BeanFactory這類基礎的容器。 a. 執行invokeBeanFactoryPostProcessors(),主要的作用是掃描包和parse (類->beanDefinition)1. 執行BeanFactoryPostProcessor的子接口BeanDefinitionRegistryPostProcessor方法postProcessBeanDefinitionRegistry(BeanDefinitionRegistry register) 作用:主要是掃描包找到合格的類,解析類 i. 先執行程序員通過 context.add的 ii. 再執行spring內部的和程序員通過注解注冊的 并且特殊的比如 實現了PriorityOrdered,Order iii. 最后再執行其他的 BeanDefinitionRegistryPostProcessor 2. 再執行BeanFactoryPostProcessor接口 方法postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory)**作用:1. 和子接口一樣 掃描包找到合格的類,解析類 2. 為@Configuration的類做代理 i. 先執行子接口中的方法 ii. 再執行程序員通過 context.add添加的 iii. 再執行spring內部和程序員通過注解注冊的 并且特殊的比如 PriorityOrdered,Order iv. 最后執行其他的 BeanFactoryPostProcessor 他們在spring中唯一的實現類是ConfigurationClassPostProcessor 將類變成beanDefinition的流程:1. 從BeanDefinitionRegistry中獲取所有的bd2. 判斷是否該bd是否被解析過,主要根據bd中是否有full或者lite屬性。3. 將未解的bd去,循環解析bd a. 先處理內部類 b. 處理@PropertrySource 環境配置 c. 處理@ComponentScan 解析帶有ComponentScan,會調用ClassPathBeanDefinitionScanner,根據包路徑,和匹配規則掃描出合格類。 d. 處理@Import i. 先處理 ImportSelect,執行selectImports(), 事務的初始化和aop的代理類型,是否傳遞代理 就是在這里做的。 ii. 然后處理 ImportBeanDefinitionRegistrar接口,會放到該bd的一個Map中,循環map統一去執行實現方法registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry); iii. 最后處理普通的類,同樣會遞歸去解析該bd e. 處理@ImportResourcef. 處理@Bean g.處理接口bd4. 然后將所有的合格的類,轉換成bd,注冊到beanDefinitionRegistry。 b. 然后會注冊beanPostProcessor,國際化等等,不是很重要 c. 比較重要的,也是將bd變成bean的方法 finishBeanFactoryInitialization(),實例化非延遲的單例(循環依賴) d. 一般來說首先getBeanDefinition之前,都要合并bd。 1)第一次getSingleton,從單例池拿是否存在,單例的第一次一般是不存在,并且會判斷是否在正在創建bean的set集合中。 singletonObjects 一級緩存,完整的bean singletonFactories 二級緩存,存的是代理bean工廠 earlySingletonObjects 三級緩存,一般是是半成品的bean a. 如果存在,直接返回 b. 如果不存在,并且不在正在創建bean的set集合中,直接返回null c. 如果不存在,并且在正在創建bean的set集合中。從三級緩存拿。 i. 存在,直接三級緩存拿。 ii. 不存在,通過二級緩存,代理的bean工廠拿,獲得該bean,然后將得到bean放到三級緩存中,移出二級緩存。(原因是生產bean工廠周期比較長的。)2)第二次getSingleton a. 首先將beanName放到正在創建bean的set集合中,表示正在創建該bean b. 然后會調用二級緩存去獲取bean,lambda延遲機制,就會調用表達式中,也就是createBean,這時候是正在獲取代理bean工廠會走一個完整的bean 的生命周期。 c. 然后從bean工廠獲取bean。 1. 構造函數:第一次 BeanPostProcessor,是否需要代理bean。如果代理bean直接返回,不會走下面的流程。 2. 第二次BeanPostProcessor,推斷構造函數 a. 首先推斷構造函數數組 i. 沒提供構造函數=========設置構造函數數組為null ii. 一個默認的構造函數======設置構造函數數組為null iii. 一個不是默認的構造函數===設置構造函數數組為該構造函數 iv. 一個構造方法并且加了@Autowired====設置構造函數數組為該構造函數 v. 多個模糊構造函數========設置構造函數數組為null vi. 多個構造函數,有唯一加了@Autowired==設置構造函數數組為該構造函數 vii. 多個構造函數,多個@Autowired(required為false)===設置構造函數數組為多個@Autowired viii. 提供多個構造函數,多個@Autowired(required為true)=== 拋異常 b. 如果推斷構造數組不為null 或者,自動注入類型為構造函數,或者設置了構造函數的屬性(xml方式)等,還有一種傳參數金來 i. 推斷構造函數, 1. 只有個構造函數,最終被確定的構造函數,2. 有多個構造函數 a. 優先修飾符最開放的,public>protected>Default>private b. 修飾符一樣找屬性最多的 ii. 推斷參數, 1. 首先找出所有候選的參數類型,實例化屬性 2. 然后類型是接口,那么判斷是否開啟寬松構造 a. 未開啟報錯。 b. 開啟了,判斷子類的差值(spring有個算法),默認差值是-1024。 c. 差值低的為該參數,一樣的丟到模糊集合中,隨機取出。 c. 構造函數數組為null,直接通過無參實例化構造函數。 3. 第三次BeanPostProcessor ,緩存了注入元素的信息 injectionMetadataCache: key: beanName或者類名 value:為解析出的屬性(包括方法)集合 InjectionMetadata。 InjectionMetadata:可以存放method 和 屬性。類中有字段判斷是否是屬性 isField。 checkedInitMethods: 存放 @PostConstruct 。 checkedDestroyMethods:存放 @PreDestroy。 a. AutowiredAnnotationBeanPostProcessor 主要解析加了 @Autowired 和 @Value 方法和屬性。 b. CommonAnnotationBeanPostProcessor 主要解析加了 @Resource屬性。 c. InitDestroyAnnotationBeanPostProcessor 主要解析加了 @PostConstruct 和 @PreDestroy方法 d. 還有很多 4. 第四次 BeanPostProcessor,生產代理工廠,作用是可以解決循環依賴 a. 先判斷是否允許循環依賴,可通過api修改屬性,或者直接改源代碼。 b. 然后判斷當前bean是否是正在創建的bean c. 調用populateBean 主要作用,注入屬性。 5. 第五次BeanPostProcessor,控制是否需要屬性注入,目前沒什么作用。 再注入緩存的屬性之前,先通過 自動注入模型 a. byType byName,找到setter,注入。體現了@Autowired不是自動注入,而是手動注入。6. 第六次 BeanPostProcessor ,完成注解的屬性填充** **@Autowired @Resource** a. 注入之前還是會再找一下是否有其他需要注入的屬性和方法。 b. 屬性的調用屬性注入方法,函數調用函數的注入方法。 i. 通過屬性的類型,從BeanDefinitionMap中找屬性名稱(接口則找找這個接口的子類), ii. 然后判斷我們當前需要注入的屬性是不是這幾個類型,得到候選的類型。 iii. 當有多個類型,再通過屬性名稱去推斷出唯一候選的屬性名。如果找到多個候選的屬性名,拋異常。 iv. 只有唯一的屬性名,通過類名去獲取類型。 v. 最終通過找到唯一匹配的beanName和類型去注入。當沒有找到匹配的名稱和類型,就會拋異常。 c. 在注入的時候,有循環依賴的時候,會去先去實例化該屬性。 7. 第七次BeanPostProcessor ,處理實現各種aware接口的重寫方法 + 生命周期回調 執行@PostConstruct方法 執行 實現InitializingBean接口的,重寫方法,和 xml 中的 init-method="xxx"方法。 8. 第八次BeanPostProcessor ,做aop代理 a. 判斷是否需要做代理 i. 找出所有的候選切面,比如 加了 @Aspect的類 , 事務的切面 ii. 做匹配邏輯,比如根據切面的連接點表達式 或者 類中方法是否加了@Transaction去 判斷當前類是否匹配出,合適的切面集合。 iii. 然后對匹配出的切面集合,做排序。 iv. 能匹配上說明就做代理 b. 哪種代理(默認用JDK動態代理) i. 當代理工廠設置ProxyTargetClass為 true,則為CGLIB代理。 ii. 當目標對象為類,則也用為CGLIB代理。 iii. 只有proxyTarget為 false,并且為目標對象為接口,則用JDK動態代理 c. 執行代理invokeHandler(這里主要是JDK的代理,invoke方法) i. 首先會進行普通方法的判斷比如hashcode eques等等,沒有就給代理類創建。不是很重要 ii. 然后判斷是否需要將代理傳遞下去,就是綁定到 ThreadLocal中(在事務中,這個特別的重要) iii. 獲取執行鏈,也就是這個目標對象的通知集合。(也就是所有過濾器鏈,實現了MethodIntercept。) iv. 執行過濾器執行鏈,類似于火炬傳遞。(事務的methodInterceptor也在這里會被調用) 1. 判斷通知是否執行完,沒有執行完去,按順序執行通知。 2. 依次調用對應的通知,最終都會去回調到proceed()方法。 3. 最終執行完代理方法,就會調用本身的方法。比較特殊的是around是在通知里,執行被代理的目標方法。
源碼底層的實現是動態代理 動態代理有cglib和jdk實現1、JDK動態代理通過反射機制實現: 通過實現InvocationHandlet接口創建自己的調用處理器; 通過為Proxy類指定ClassLoader對象和一組interface來創建動態代理; 通過反射機制獲取動態代理類的構造函數,其唯一參數類型就是調用處理器接口類型; 通過構造函數創建動態代理類實例,構造時調用處理器對象作為參數參入; JDK動態代理是面向接口的代理模式,如果被代理目標沒有接口那么Spring也無能為力,Spring通過Java的反射機制生產被代理接口的新的匿名實現類,重寫了其中AOP的增強方法。 2、CGLib動態代理: CGLib是一個強大、高性能的Code生產類庫,可以實現運行期動態擴展java類,Spring在運行期間通過 CGlib繼承要被動態代理的類,重寫父類的方法,實現AOP面向切面編程,底層是ASM實現 3、兩者對比: JDK動態代理是面向接口的。 CGLib動態代理是通過字節碼底層繼承要代理類來實現(被代理類不能被final關鍵字所修飾,)。 4、使用注意: 如果要被代理的對象是個實現類,那么Spring會使用JDK動態代理來完成操作(Spirng默認采用JDK動態代理實現機制); 如果要被代理的對象不是個實現類,那么Spring會強制使用CGLib來實現動態代理
1)前端控制器DispatcherServlet 由框架提供作用:接收請求,處理響應結果 2)處理器映射器HandlerMapping由框架提供 作用:根據請求URL,找到對應的Handler 3)處理器適配器HandlerAdapter由框架提供 作用:調用處理器(Handler|Controller)的方法 4)處理器Handler又名Controller,后端處理器 作用:接收用戶請求數據,調用業務方法處理請求 5)視圖解析器ViewResolver由框架提供 作用:視圖解析,把邏輯視圖名稱解析成真正的物理視圖 支持多種視圖技術:JSTLView,FreeMarker... 6)視圖View,程序員開發 作用:將數據展現給用戶
1、@SpringBootApplication=>2、@EnableAutoConfiguration=>3、@Import(AutoConfigurationImportSelector.class)=>調用getCandidateConfigurations()方法,里面有個讀取Meta-info/spring.factories
1.編寫一個帶有@Configuration注解的類,如果按條件加載可以加上@ConditionalOnClass或@ConditionalOnBean注解2.在classpath下創建META-INF/spring.factories文件,并在spring.factories中添加 org.springframework.boot.autoconfigure.EnableAutoConfiguretion =上面定義類的全類名
RabbitMQ提供transaction和confirm模式來確保生產者不丟消息; transaction機制就是說:發送消息前,開啟事務(channel.txSelect()),然后發送消息,如果發送過程中出現什么異常,事務就會回滾(channel.txRollback()),如果發送成功則提交事務(channel.txCommit())。然而,這種方式有個缺點:吞吐量下降; confirm模式用的居多:一旦channel進入confirm模式,所有在該信道上發布的消息都將會被指派一個唯一的ID(從1開始),一旦消息被投遞到所有匹配的隊列之后; rabbitMQ就會發送一個ACK給生產者(包含消息的唯一ID),這就使得生產者知道消息已經正確到達目的隊列了; 如果rabbitMQ沒能處理該消息,則會發送一個Nack消息給你,你可以進行重試操作。
處理消息隊列丟數據的情況,一般是開啟持久化磁盤的配置。 這個持久化配置可以和confirm機制配合使用,你可以在消息持久化磁盤后,再給生產者發送一個Ack信號。 這樣,如果消息持久化磁盤之前,rabbitMQ陣亡了,那么生產者收不到Ack信號,生產者會自動重發。 那么如何持久化呢?1. 將queue的持久化標識durable設置為true,則代表是一個持久的隊列2. 發送消息的時候將deliveryMode=2這樣設置以后,即使rabbitMQ掛了,重啟后也能恢復數據
消費者在收到消息之后,處理消息之前,會自動回復RabbitMQ已收到消息; 如果這時處理消息失敗,就會丟失該消息; 解決方案:處理消息成功后,手動回復確認消息。(手動ACK)
保證消息的唯一性,就算是多次傳輸,不要讓消息的多次消費帶來影響;保證消息等冪性=》redis,數據庫自增
同一個queue里面消息是有序的,保證消息發送到同一個queue就好了。 單線程消費保證消息的順序性;對消息進行編號,消費者處理消息是根據編號處理消息;
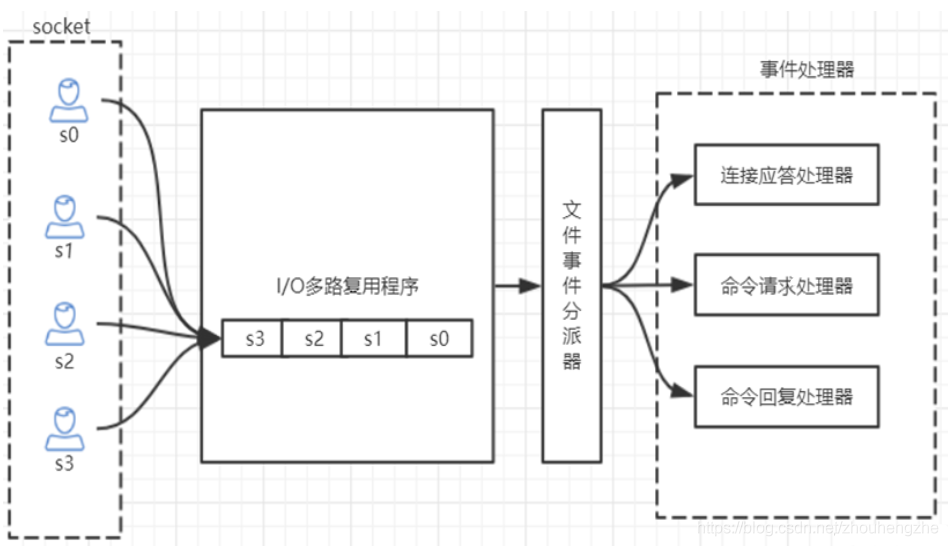
Redis的IO多路復用:redis利用epoll來實現IO多路復用,將連接信息和事件放到隊列中,依次放到 文件事件分派器,事件分派器將事件分發給事件處理器。
1、底層: 是SDS實現,其編碼方式有int,raw,embstr,主要存在于redisObject的ptr屬性中 a. 默認是int,正式類型是longb. 當字符串大于32字節的字符串值,設置為raw c.當 字符串保存的小于等于32字節,設置為embstr 總結: 在Redis中,存儲long、double類型的浮點數是先轉換為字符串再進行存儲的。 raw與embstr編碼效果是相同的,不同在于內存分配與釋放,raw兩次,embstr一次。 embstr內存塊連續,能更好的利用緩存在來的優勢int編碼和embstr編碼如果做追加字符串等操作,滿足條件下會被轉換為raw編碼;embstr編碼的對象是只讀的,一旦修改會先轉碼到raw。2、應用場景 a. 單值緩存 b. 分布式鎖 c. 計數器 d. Web集群session共享 e. 分布式系統全局序列號 f. 對象緩存
1、底層: List是一個有序(按加入的時序排序)的數據結構,Redis采用quicklist(雙端鏈表) 和 ziplist 作為List的底層實現2、應用場景 a.Stack(棧) = LPUSH + LPOP b. Queue(隊列)= LPUSH + RPOP c. Blocking MQ(阻塞隊列)= LPUSH + BRPOP d. 微博和微信公號消息流 e. 微博消息和微信公號消息
1、底層: Hash 數據結構底層實現為一個字典( dict ),也是RedisBb用來存儲K-V的數據結構,當數據量比較小,或者單個元素比較小時,底層用ziplist存儲,數據大小和元素數量閾值可以通過如下參數設置2、應用場景: a. 對象緩存 b. 電商購物車 c. 購物車操作(添加商品,增加數量,商品總數,刪除商品,獲取購物車所有商品)
1、底層: Set為無序的,自動去重的集合數據類型,Set數據結構底層實現為一個value為null的字典( dict ),當數據可以用整形表示時,Set集合將被編碼為intset數據結構。兩個條件任意滿足時Set將用hashtable存儲數據。 a. 元素個數大于 set-max-intset-entries ,b. 元素無法用整形表示 set-max-intset-entries 512 // intset 能存儲的最大元素個數,超過則用hashtable編碼2、應用場景: a. 微信抽獎小程序 b. 微信微博點贊,收藏,標簽 c. 集合操作實現微博微信關注模型 d. 集合操作實現電商商品篩選
1、底層: Sort Set 為有序的,自動去重的集合數據類型,ZSet 數據結構底層實現為 字典(dict) + 跳表(skiplist) ,當數據比較少時,用ziplist編碼結構存儲 zset-max-ziplist-entries 128 // 元素個數超過128 ,將用skiplist編碼 zset-max-ziplist-value 64 // 單個元素大小超過 64 byte, 將用 skiplist編碼2、應用場景: a. 點擊新聞 b. 展示當日排行前十 c. 七日搜索榜單計算 d. 展示七日排行前十
1、底層: 空間填充曲線,也就是經緯度換編碼,二分取右為1地球緯度區間是[-90,90], 如某緯度是39.92324,可以通過下面算法來進行維度編碼:1)區間[-90,90]進行二分為[-90,0),[0,90],稱為左右區間,可以確定39.92324屬于右區間[0,90],給標記為12)接著將區間[0,90]進行二分為 [0,45),[45,90],可以確定39.92324屬于左區間 [0,45),給標記為03)遞歸上述過程39.92324總是屬于某個區間[a,b]。隨著每次迭代區間[a,b]總在縮小,并越來越逼近39.9281674)如果給定的緯度(39.92324)屬于左區間,則記錄0,如果屬于右區間則記錄1,這樣隨著算法的進行會 產生一個序列1011 1000 1100 0111 1001,序列的長度跟給定的區間劃分次數有關。2、應用場景: 搖一搖 附近位置
底層是取n個hash,做位運算
7.2.8、HyperLogLog(基數統計):統計用戶訪問量
RDB:快照,bgsave異步創建dump.rdb文件,底層是fork+cow實現。 AOF:追加,底層是先寫入緩存中,然后每隔一段時間會fsync到磁盤,也是fork一個子進程 運行:默認加載rdb文件,如果同時啟用了RDB 和 AOF 方式,AOF 優先,啟動時只加載 AOF 文件恢復數據,若開啟混合持久化方式則會創建一個文件,上面是rdb,下面是aof的數據,啟動加載這個文件
1、如果Redis被當做緩存使用,使用一致性哈希實現動態擴容縮容。2、如果Redis被當做一個持久化存儲使用,必須使用固定的keys-to-nodes映射關系,節點的數量一旦確定不能變化。否則的話(即Redis節點需要動態變化的情況),必須使用可以在運行時進行數據再平衡的一套系統,而當前只有Redis集群可以做到這樣
a) 針對設置了過期時間的key做處理: 1、volatile-ttl:在篩選時,會針對設置了過期時間的鍵值對,根據過期時間的先后進行刪除,越早過期的越先被刪除。 2、volatile-random:就像它的名稱一樣,在設置了過期時間的鍵值對中,進行隨機刪除。 3、volatile-lru:會使用 LRU 算法篩選設置了過期時間的鍵值對刪除。 4、volatile-lfu:會使用 LFU 算法篩選設置了過期時間的鍵值對刪除。 b) 針對所有的key做處理: 5、allkeys-random:從所有鍵值對中隨機選擇并刪除數據。 6、allkeys-lru:使用 LRU 算法在所有數據中進行篩選刪除。 7、allkeys-lfu:使用 LFU 算法在所有數據中進行篩選刪除。 c) 不處理:8、noeviction:不會剔除任何數據,拒絕所有寫入操作并返回客戶端錯誤信息"(error)OOM command not allowed when used memory",此時Redis只響應讀操作。
1、被動刪除:當讀/寫一個已經過期的key時,會觸發惰性刪除策略,直接刪除掉這個過期key2、主動刪除:由于惰性刪除策略無法保證冷數據被及時刪掉,所以Redis會定期主動淘汰一批已過期的key3、當前已用內存超過maxmemory限定時,觸發主動清理策略4、LRU 算法(Least Recently Used,最近最少使用):淘汰很久沒被訪問過的數據,以最近一次訪問時間作為參考。5、LFU 算法(Least Frequently Used,最不經常使用):淘汰最近一段時間被訪問次數最少的數據,以次數作為參考
由于大批量緩存在同一時間失效可能導致大量請求同時穿透緩存直達數據庫,可能會造成數據庫瞬間壓力過大甚至掛掉
1、在批量增加緩存時將這一批數據的緩存過期時間設置為一個時間段內的不同時間。2、分布式鎖
緩存雪崩指的是緩存層支撐不住或宕掉后, 流量會像奔逃的野牛一樣, 打向后端存儲層。由于緩存層承載著大量請求, 有效地保護了存儲層, 但是如果緩存層由于某些原因不能提供服務(比如超大并發過來,緩存層支撐不住,或者由于緩存設計不好,類似大量請求訪問bigkey,導致緩存能支撐的并發急劇下降), 于是大量請求都會打到存儲層, 存儲層的調用量會暴增, 造成存儲層也會級聯宕機的情況。
1) 保證緩存層服務高可用性,比如使用Redis Sentinel或Redis Cluster。2) 依賴隔離組件為后端限流熔斷并降級。比如使用Sentinel或Hystrix限流降級組件。 比如服務降級,我們可以針對不同的數據采取不同的處理方式。當業務應用訪問的是非核心數據(例如電商商品屬性,用戶信息等)時,暫時停止從緩存中查詢這些數據,而是直接返回預定義的默認降級信息、空值或是錯誤提示信息;當業務應用訪問的是核心數據(例如電商商品庫存)時,仍然允許查詢緩存,如果緩存缺失,也可以繼續通過數據庫讀取。3) 提前演練。 在項目上線前, 演練緩存層宕掉后, 應用以及后端的負載情況以及可能出現的問題, 在此基礎上做一些預案設定。
緩存穿透是指查詢一個根本不存在的數據, 緩存層和存儲層都不會命中, 通常出于容錯的考慮, 如果從存儲層查不到數據則不寫入緩存層。 緩存穿透將導致不存在的數據每次請求都要到存儲層去查詢, 失去了緩存保護后端存儲的意義。 造成緩存穿透的基本原因有兩個: 第一, 自身業務代碼或者數據出現問題。 第二, 一些惡意攻擊、 爬蟲等造成大量空命中。
1、緩存空對象2、布隆過濾器(redission里面有個getBloomFilter()方法實現,==布隆過濾器不能刪除數據,如果要刪除得重新初始化數據==)
開發人員使用“緩存+過期時間”的策略既可以加速數據讀寫, 又保證數據的定期更新, 這種模式基本能夠滿足絕大部分需求。 但是有兩個問題如果同時出現, 可能就會對應用造成致命的危害: 當前key是一個熱點key(例如一個熱門的娛樂新聞),并發量非常大。 重建緩存不能在短時間完成, 可能是一個復雜計算, 例如復雜的SQL、 多次IO、 多個依賴等。 在緩存失效的瞬間, 有大量線程來重建緩存, 造成后端負載加大, 甚至可能會讓應用崩潰。 要解決這個問題主要就是要避免大量線程同時重建緩存。
互斥鎖(也就是所謂的分布式鎖)
1、可以通過加讀寫鎖保證并發讀寫或寫寫的時候按順序排好隊,讀讀的時候相當于無鎖。2、可以用阿里開源的canal通過監聽數據庫的binlog日志及時的去修改緩存,但是引入了新的中間件,增加了系統的復雜度。3、先刪緩存,再寫數據庫 (1)timer異步淘汰(本文沒有細講,本質就是起個線程專門異步二次淘汰緩存) (2)總線異步淘汰 (3)讀binlog異步淘汰//blog.csdn.net/zhouhengzhe?t=1
到此,關于“JVM+Redis+SpringBoot的面試題有哪些”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。