溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹One Hot編碼指的是什么,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
當你在玩ML模型的時候,你會在任何地方遇到這個“One hot encoding”的術語。
當你在玩ML模型的時候,你會在任何地方遇到這個“One hot encoding”術語。你可以看到一個one hot編碼器的sklearn文檔,其中說“使用one-hot也就是one-of- k模式編碼分類整數特征”。不是很清楚,對吧?或者至少不適合我。讓我們看看one hot編碼到底是什么。
One hot編碼方法是將分類變量轉換成一種形式,這種形式可以提供給ML算法,以便更好地進行預測。
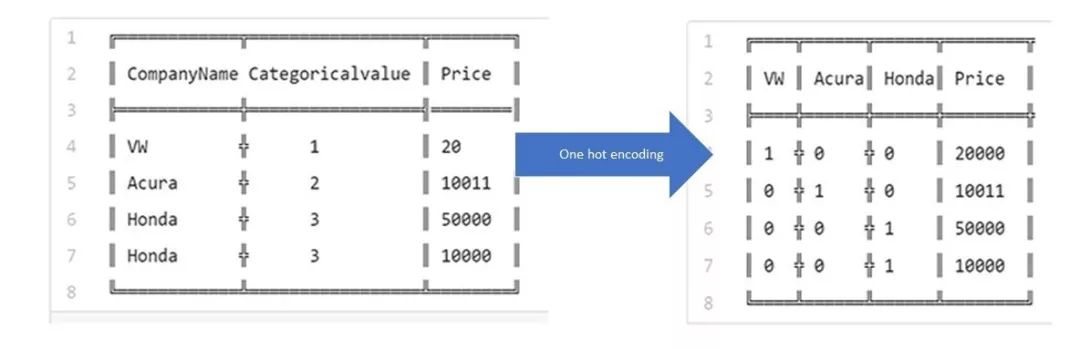
假設數據集如下:
╔════════════╦═════════════════╦════════╗
║ CompanyName Categoricalvalue ║ Price ║
╠════════════╬═════════════════╣════════║
║ VW ╬ 1 ║ 20000 ║
║ Acura ╬ 2 ║ 10011 ║
║ Honda ╬ 3 ║ 50000 ║
║ Honda ╬ 3 ║ 10000 ║
╚════════════╩═════════════════╩════════╝分類值表示數據集中條目的數值。例如:如果數據集中有另一家公司,它的分類值應該是4。隨著惟一條目數量的增加,分類值也相應地增加。
上表只是一種表示。實際上,分類值從0開始一直到N-1個類別。
你可能已經知道,可以使用sklearn的LabelEncoder完成分類值分配。
現在讓我們回到one hot編碼:假設我們按照sklearn文檔中給出的說明來進行one hot編碼,然后進行一些清理,最后得到以下結果:
╔════╦══════╦══════╦════════╦
║ VW ║ Acura║ Honda║ Price ║
╠════╬══════╬══════╬════════╬
║ 1 ╬ 0 ╬ 0 ║ 20000 ║
║ 0 ╬ 1 ╬ 0 ║ 10011 ║
║ 0 ╬ 0 ╬ 1 ║ 50000 ║
║ 0 ╬ 0 ╬ 1 ║ 10000 ║
╚════╩══════╩══════╩════════╝在我們進一步討論之前,你能想到一個原因嗎?為什么僅僅使用標簽編碼給模型訓練是不夠的?為什么需要one hot編碼?
標簽編碼的問題是,它假定類別值越高,類別越好。“等等,什么! ?”
讓我解釋一下:這種組織形式的前提是基于類比的值,VW > Acura > Honda。假設你的模型內部計算平均值,那么我們得到,1+3 = 4/2 =2。這意味著:VW 和Honda的平均水平是 Acura。這絕對是個災難。這個模型的預測會有很多誤差。
這就是為什么我們使用one hot編碼器來執行類別的“二值化”,并將其作為一個特征來訓練模型。
另一個例子:假設你有一個“flower”特征,它可以接受“daffodil”、“lily”和“rose”的值。一個one hot編碼將“flower”特征轉換為三個特征,“is_daffodil”、“is_lily”和“is_rose”,它們都是二進制的。
見下圖:
關于One Hot編碼指的是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





