溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Prometheus-operator的介紹和配置方法”,在日常操作中,相信很多人在Prometheus-operator的介紹和配置方法問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Prometheus-operator的介紹和配置方法”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
隨著云原生概念盛行,對于容器、服務、節點以及集群的監控變得越來越重要。Prometheus 作為 Kubernetes 監控的事實標準,有著強大的功能和良好的生態。但是它不支持分布式,不支持數據導入、導出,不支持通過 API 修改監控目標和報警規則,所以在使用它時,通常需要寫腳本和代碼來簡化操作。Prometheus Operator 為監控 Kubernetes service、deployment 和 Prometheus 實例的管理提供了簡單的定義,簡化在 Kubernetes 上部署、管理和運行 Prometheus 和 Alertmanager 集群。
Prometheus Operator (后面都簡稱 Operater) 提供如下功能:
創建/銷毀:在 Kubernetes namespace 中更加容易地啟動一個 Prometheues 實例,一個特定應用程序或者團隊可以更容易使用 Operator。
便捷配置:通過 Kubernetes 資源配置 Prometheus 的基本信息,比如版本、存儲、副本集等。
通過標簽標記目標服務: 基于常見的 Kubernetes label 查詢自動生成監控目標配置;不需要學習 Prometheus 特定的配置語言。
對于版本高于 0.18.0 的 Prometheus Operator 要求 Kubernetes 集群版本高于 1.8.0。如果你才開始使用 Prometheus Operator,推薦你使用最新版。
如果你使用的舊版本的 Kubernetes 和 Prometheus Operator 還在運行,推薦先升級 Kubernetes,再升級 Prometheus Operator。
使用 helm 安裝 Prometheus Operator。使用 helm 安裝后,會在 Kubernetes 集群中創建、配置和管理 Prometheus 集群,chart 中包含多種組件:
prometheus-operator
prometheus
alertmanager
node-exporter
kube-state-metrics
grafana
收集 Kubernetes 內部組件指標的監控服務
kube-apiserver
kube-scheduler
kube-controller-manager
etcd
kube-dns/coredns
kube-proxy
安裝一個版本名為 my-release 的 chart:
helm install --name my-release stable/prometheus-operator
這會在集群中安裝一個默認配置的 prometheus-operator。這份配置文件列出了安裝過程中可以配置的選項。
默認會安裝 Prometheus Operator, Alertmanager, Grafana。并且會抓取集群的基本信息。
卸載 my-release 部署:
helm delete my-release
這個命令會刪除與這個 chart 相關的所有 Kubernetes 組件。
這個 chart 創建的 CRDs 不會被默認刪除,需要手動刪除:
kubectl delete crd prometheuses.monitoring.coreos.com kubectl delete crd prometheusrules.monitoring.coreos.com kubectl delete crd servicemonitors.monitoring.coreos.com kubectl delete crd podmonitors.monitoring.coreos.com kubectl delete crd alertmanagers.monitoring.coreos.com
Prometheus Operator 架構圖如下:
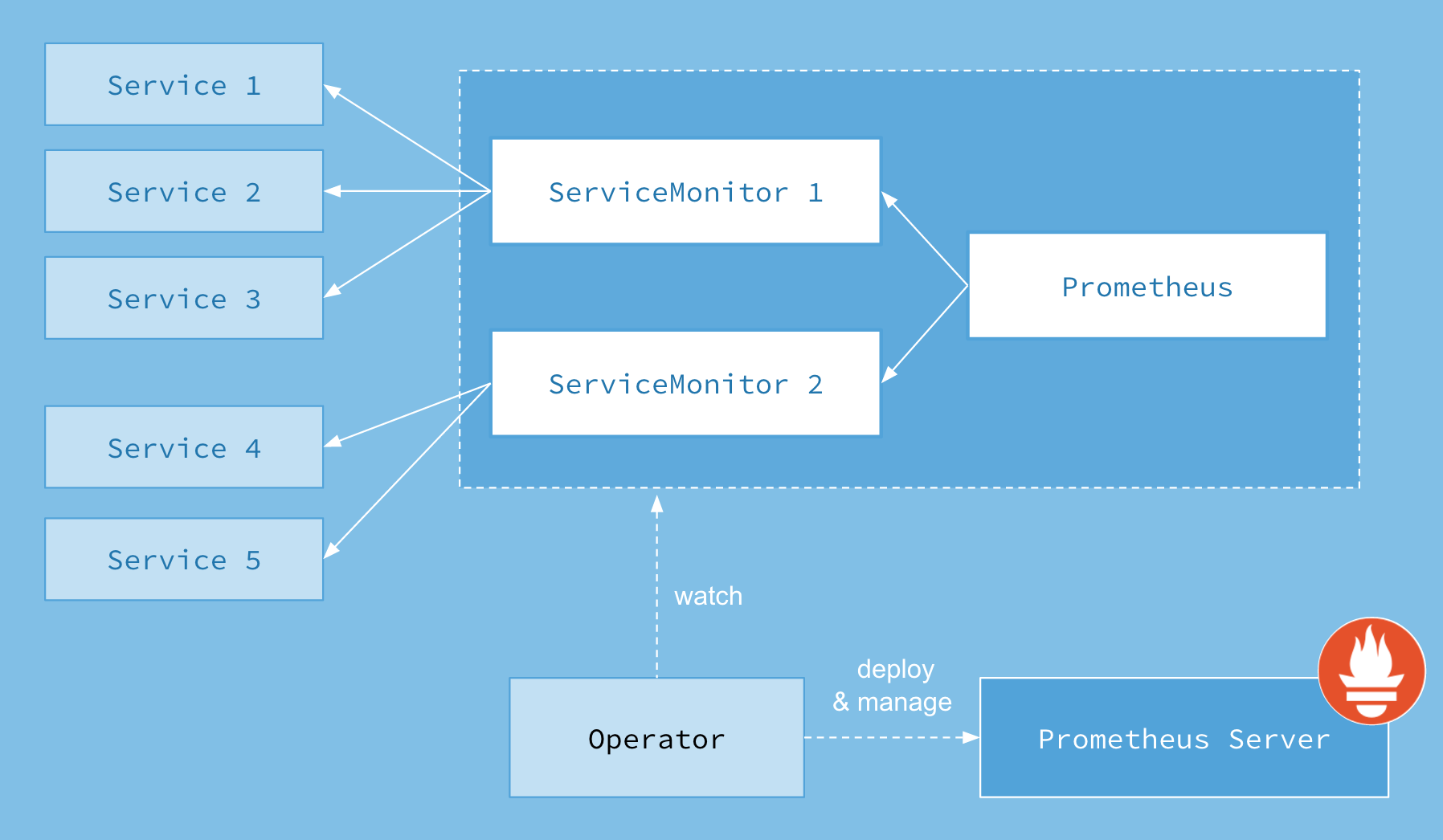
上面架構圖中,各組件以不同的方式運行在 Kubernetes 集群中:
Operator: 根據自定義資源(Custom Resource Definition / CRDs)來部署和管理 Prometheus Server,同時監控這些自定義資源事件的變化來做相應的處理,是整個系統的控制中心。
Prometheus:聲明 Prometheus deployment 期望的狀態,Operator 確保這個 deployment 運行時一直與定義保持一致。
Prometheus Server: Operator 根據自定義資源 Prometheus 類型中定義的內容而部署的 Prometheus Server 集群,這些自定義資源可以看作是用來管理 Prometheus Server 集群的 StatefulSets 資源。
ServiceMonitor:聲明指定監控的服務,描述了一組被 Prometheus 監控的目標列表。該資源通過 Labels 來選取對應的 Service Endpoint,讓 Prometheus Server 通過選取的 Service 來獲取 Metrics 信息。
Service:簡單的說就是 Prometheus 監控的對象。
Alertmanager:定義 AlertManager deployment 期望的狀態,Operator 確保這個 deployment 運行時一直與定義保持一致。
Prometheus Operater 定義了如下的四類自定義資源:
Prometheus
ServiceMonitor
Alertmanager
PrometheusRule
Prometheus 自定義資源(CRD)聲明了在 Kubernetes 集群中運行的 Prometheus 的期望設置。包含了副本數量,持久化存儲,以及 Prometheus 實例發送警告到的 Alertmanagers等配置選項。
每一個 Prometheus 資源,Operator 都會在相同 namespace 下部署成一個正確配置的 StatefulSet,Prometheus 的 Pod 都會掛載一個名為 <prometheus-name> 的 Secret,里面包含了 Prometheus 的配置。Operator 根據包含的 ServiceMonitor 生成配置,并且更新含有配置的 Secret。無論是對 ServiceMonitors 或者 Prometheus 的修改,都會持續不斷的被按照前面的步驟更新。
一個樣例配置如下:
kind: Prometheus
metadata: # 略
spec:
alerting:
alertmanagers:
- name: prometheus-prometheus-oper-alertmanager # 定義該 Prometheus 對接的 Alertmanager 集群的名字, 在 default 這個 namespace 中
namespace: default
pathPrefix: /
port: web
baseImage: quay.io/prometheus/prometheus
replicas: 2 # 定義該 Proemtheus “集群”有兩個副本,說是集群,其實 Prometheus 自身不帶集群功能,這里只是起兩個完全一樣的 Prometheus 來避免單點故障
ruleSelector: # 定義這個 Prometheus 需要使用帶有 prometheus=k8s 且 role=alert-rules 標簽的 PrometheusRule
matchLabels:
prometheus: k8s
role: alert-rules
serviceMonitorNamespaceSelector: {} # 定義這些 Prometheus 在哪些 namespace 里尋找 ServiceMonitor
serviceMonitorSelector: # 定義這個 Prometheus 需要使用帶有 k8s-app=node-exporter 標簽的 ServiceMonitor,不聲明則會全部選中
matchLabels:
k8s-app: node-exporter
version: v2.10.0Prometheus 配置
ServiceMonitor 自定義資源(CRD)能夠聲明如何監控一組動態服務的定義。它使用標簽選擇定義一組需要被監控的服務。這樣就允許組織引入如何暴露 metrics 的規定,只要符合這些規定新服務就會被發現列入監控,而不需要重新配置系統。
要想使用 Prometheus Operator 監控 Kubernetes 集群中的應用,Endpoints 對象必須存在。Endpoints 對象本質是一個 IP 地址列表。通常,Endpoints 對象由 Service 構建。Service 對象通過對象選擇器發現 Pod 并將它們添加到 Endpoints 對象中。
一個 Service 可以公開一個或多個服務端口,通常情況下,這些端口由指向一個 Pod 的多個 Endpoints 支持。這也反映在各自的 Endpoints 對象中。
Prometheus Operator 引入 ServiceMonitor 對象,它發現 Endpoints 對象并配置 Prometheus 去監控這些 Pods。
ServiceMonitorSpec 的 endpoints 部分用于配置需要收集 metrics 的 Endpoints 的端口和其他參數。在一些用例中會直接監控不在服務 endpoints 中的 pods 的端口。因此,在 endpoints 部分指定 endpoint 時,請嚴格使用,不要混淆。
注意:endpoints(小寫)是 ServiceMonitor CRD 中的一個字段,而 Endpoints(大寫)是 Kubernetes 資源類型。
ServiceMonitor 和發現的目標可能來自任何 namespace。這對于跨 namespace 的監控十分重要,比如 meta-monitoring。使用 PrometheusSpec 下 ServiceMonitorNamespaceSelector, 通過各自 Prometheus server 限制 ServiceMonitors 作用 namespece。使用 ServiceMonitorSpec 下的 namespaceSelector 可以現在允許發現 Endpoints 對象的命名空間。要發現所有命名空間下的目標,namespaceSelector 必須為空。
spec: namespaceSelector: any: true
一個樣例配置如下:
kind: ServiceMonitor metadata: labels: k8s-app: node-exporter # 這個 ServiceMonitor 對象帶有 k8s-app=node-exporter 標簽,因此會被 Prometheus 選中 name: node-exporter namespace: default spec: selector: matchLabels: # 定義需要監控的 Endpoints,帶有 app=node-exporter 且 k8s-app=node-exporter標簽的 Endpoints 會被選中 app: node-exporter k8s-app: node-exporter endpoints: - bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token interval: 30s # 定義這些 Endpoints 需要每 30 秒抓取一次 targetPort: 9100 # 定義這些 Endpoints 的指標端口為 9100 scheme: https jobLabel: k8s-app
ServiceMonitor 配置
Alertmanager 自定義資源(CRD)聲明在 Kubernetes 集群中運行的 Alertmanager 的期望設置。它也提供了配置副本集和持久化存儲的選項。
每一個 Alertmanager 資源,Operator 都會在相同 namespace 下部署成一個正確配置的 StatefulSet。Alertmanager pods 配置掛載一個名為 <alertmanager-name> 的 Secret, 使用 alertmanager.yaml key 對作為配置文件。
當有兩個或更多配置的副本時,Operator 可以高可用性模式運行Alertmanager實例。
一個樣例配置如下:
kind: Alertmanager # 一個 Alertmanager 對象 metadata: name: prometheus-prometheus-oper-alertmanager spec: baseImage: quay.io/prometheus/alertmanager replicas: 3 # 定義該 Alertmanager 集群的節點數為 3 version: v0.17.0
Alertmanager 配置
PrometheusRule CRD 聲明一個或多個 Prometheus 實例需要的 Prometheus rule。
Alerts 和 recording rules 可以保存并應用為 yaml 文件,可以被動態加載而不需要重啟。
一個樣例配置如下:
kind: PrometheusRule
metadata:
labels: # 定義該 PrometheusRule 的 label, 顯然它會被 Prometheus 選中
prometheus: k8s
role: alert-rules
name: prometheus-k8s-rules
spec:
groups:
- name: k8s.rules
rules: # 定義了一組規則,其中只有一條報警規則,用來報警 kubelet 是不是掛了
- alert: KubeletDown
annotations:
message: Kubelet has disappeared from Prometheus target discovery.
expr: |
absent(up{job="kubelet"} == 1)
for: 15m
labels:
severity: criticalPrometheusRule 配置
它們之間的關系如下圖:
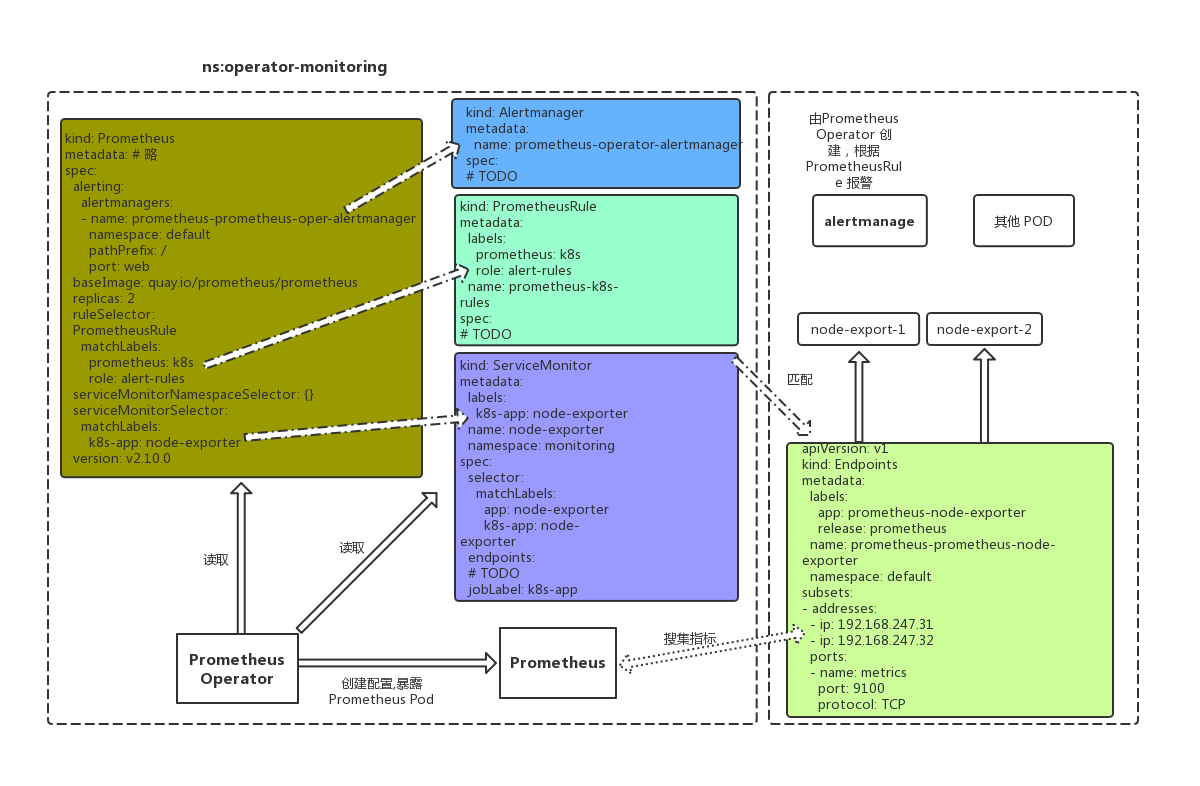
Prometheus Operator 中所有的 API 對象都是 CRD 中定義好的 Schema,API Server會校驗。當開發者使用 ConfigMap 保存配置沒有任何校驗,配置文件寫錯時,自表現為功能不可用,問題排查復雜。在 Prometheus Operator 中,所有在 Prometheus 對象、ServiceMonitor 對象、PrometheusRule 對象中的配置都是有 Schema 校驗的,校驗失敗 apply 直接出錯,這就大大降低了配置異常的風險。
Prometheus Operator 借助 K8S 將 Prometheus 服務平臺化。有了 Prometheus 和 AlertManager 這樣的 API 對象,非常簡單、快速的可以在 K8S 集群中創建和管理 Prometheus 服務和 AlertManager 服務,以應對不同業務部門,不同領域的監控需求。
ServiceMonitor 和 PrometheusRule 解決了 Prometheus 配置難維護問題,開發者不再需要去專門學習 Prometheus 的配置文件,不再需要通過 CI 和 k8s ConfigMap 等手段把配置文件更新到 Pod 內再觸發 webhook 熱更新,只需要修改這兩個對象資源就可以了。
到此,關于“Prometheus-operator的介紹和配置方法”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





