溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
介紹: hdfs是主從架構,所有為了實時的得知dataNode是否存活,必須建立心跳機制,在整個hdfs運行過程中,dataNode會定時的向nameNode發送心跳報告已告知nameNode自己的狀態。
心跳內容:
- 報告自己的存活狀態,每次匯報之后都會更新維護的計數信息
- 向nameNode匯報自己的存儲的block列表信息
心跳報告周期:
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value> //單位秒
</property> nameNode判斷一個dataNode宕機的基準:連續10次接收不到dataNode的心跳信息,和2次的檢查時間。
檢查時間:表示在nameNode在接收不到dataNode的心跳時,此時會向dataNode主動發送檢查
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value> //單位毫秒
</property>計算公式:2dfs.namenode.heartbeat.recheck-interval+10dfs.heartbeat.interval=310+3002=630s=10.5min
介紹:hdfs在啟動的時候,首先會進入的安全模式中,當達到規定的要求時,會退出安全模式。在安全模式中,不能執行任何修改元數據信息的操作。
hdfs的元數據的介紹(三個部分):
- 抽象目錄樹
- 數據與塊的對應關系(文件被切分成多少個塊)
- block塊存放的位置信息
hdfs元數據的存儲位置:
- 內存:內存中存儲了一份完整的元數據信息(抽象目錄樹、數據與塊的對應關系、block塊存放的位置信息)
- 硬盤:抽象目錄樹、數據與塊的對應關系
注意:其中內存中的元數據的block塊存放的位置信息,是通過dataNode向nameNode匯報心跳時獲取的,硬盤中的元數據,是因為內存中的元數據在機器宕機時就自動消失,所以需要將內存中的元數據持久化到硬盤
而硬盤中的元數據只有抽象目錄樹、數據與塊的對應關系,沒有block塊存放的位置信息
nameNode在啟動的所作的操作:
集群的啟動順序:nameNode---》dataNode---》secondaryNameNode
將硬盤中的元數據信息加載內存,如果是第一次啟動集群,此時會在本地生成一個fsimage鏡像文件,接收dataNode匯報的心跳,將匯報中的block的位置信息,加載到內存。當然就在此時hdfs會進入安全模式。
退出安全模式的條件:
- 如果在集群啟動時dfs.namenode.safemode.min.datanodes(啟動的dataNode個數)為0時,并且,數據塊的最小副本數dfs.namenode.replication.min為1時,此時會退出安全模式,也就是說,集群達到了最小副本數,并且能運行的datanode節點也達到了要求,此時退出安全模式
- 啟動的dataNode個數為0時,并且所有的數據塊的存貨率達到0.999f時,集群退出安全模式(副本數達到要求)
<property>
<name>dfs.namenode.safemode.threshold-pct</name>
<value>0.999f</value>
</property>手動退出或者進入安全模式
hdfs dfsadmin -safemode enter 進入
hdfs dfsadmin -safemode leave 退出
hdfs dfsadmin -safemode get 查看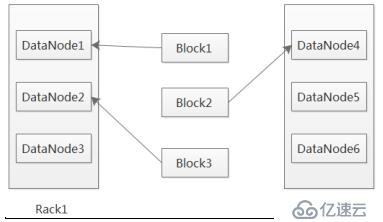
第一個副本,放置在離客戶端最近的那個機架的任意節點,如果客戶端是本機,那就存放在本機(保證有一個副本數),第二個副本,放置在跟第一個副本不同機架的任意節點上,第三個副本,放置在跟第二個副本相同機架的不同節點上。
修改副本的方法:
1. 修改配置文件:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>2. 命令設置: hadoop fs -setrep 2 -R dir
hdfs的負載均衡:表示每一個dataNode存儲的數據與其硬件相匹配,即占用率相當
,如何手動調整負載均衡:
- 集群自動調整負載均衡的帶寬:(默認為1M)
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>1048576</value> //1M
</property>- 告訴集群進行負載均衡:start-balancer.sh -t 10% 表示節點最大占用率與節點的最小的占用率之間的差值當超過10%時,此時集群不會立刻進行負載均衡,會在集群不忙的時候進行。
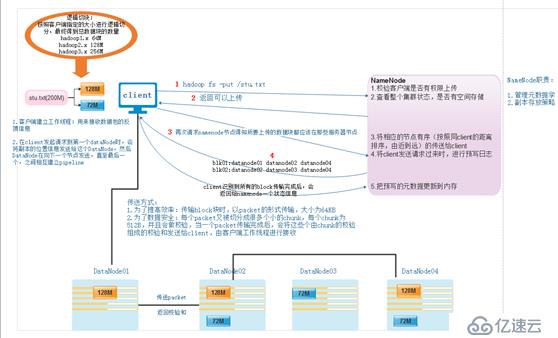
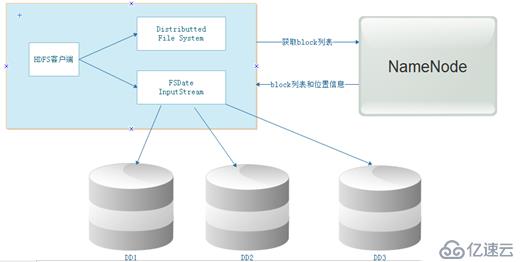
這是在分布式的基礎上,secondaryNamenode對元數據的合并: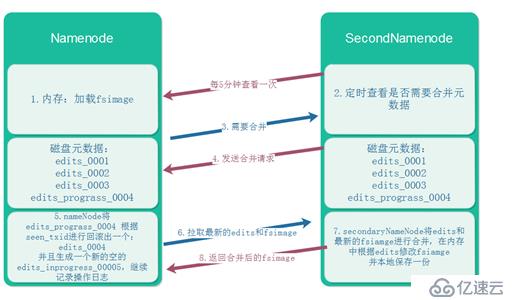
合并時機:
A:間隔多長時間合并一次
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value> //單位秒
</property>B:操作日志記錄超過多少條合并一次
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
</property>免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





