溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
?? YARN 是一個資源調度平臺,負責為運算程序提供服務器運算資源,相當于一個分布式的操作系統平臺,而 MapReduce 等運算程序則相當于運行于操作系統之上的應用程序。
?? - JobTracker是集群的事務的集中處理,存在單點故障
?? - JobTracker需要完成得任務太多,既要維護job的狀態又要維護job的task的狀態,造成資源消耗過多
?? - 在 TaskTracker 端,用Map/Reduce Task作為資源的表示過于簡單,沒有考慮到CPU。內存,等資源情況,將兩個需要大消耗量的Task調度到一起,很容易出現OOM。
?? - 把資源強制劃分為 Map/Reduce Slot,當只有 MapTask 時,TeduceSlot 不能用;當只有 ReduceTask 時,MapSlot 不能用,容易造成資源利用不足。
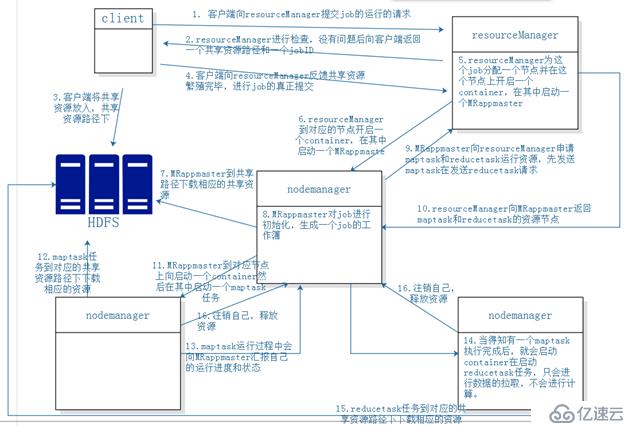
??MRv2 最基本的想法是將原 JobTracker 主要的資源管理和 Job 調度/監視功能分開作為兩個單獨的守護進程。有一個全局的ResourceManager(RM)和每個 Application 有一個ApplicationMaster(AM),Application 相當于 MapReduce Job 或者 DAG jobs。ResourceManager和 NodeManager(NM)組成了基本的數據計算框架。ResourceManager 協調集群的資源利用,任何 Client 或者運行著的 applicatitonMaster 想要運行 Job 或者 Task 都得向 RM 申請一定的資源。ApplicatonMaster 是一個框架特殊的庫,對于 MapReduce 框架而言有它自己的 AM 實現,
用戶也可以實現自己的 AM,在運行的時候,AM 會與 NM 一起來啟動和監視 Tasks。
ResourceManager:ResoueceMananer是基于應用程序對集群資源的需求進行調度的yarn集群的主控制節點,負責協調和管理整個集群,相應用戶提交的不同的類型的應用程序,解析、調度、監控等工作。ResourceManager會為每一個application啟動一個MRappmaster,并且MRappmaster分散在各個nodemanager上。
ResourceManager只要有兩個部分組成:
??- 應用程序管理器(ApplicationsManager, ASM): 管理和監控所有的應用程序的MRappmaster,啟動應用程序的MRappmaster,以及MRappmaster失敗重啟
??- 調度器(Scheduler):底層是一個隊列,負責應用程序的執行時間和順序
???? - FIFO(先進先出的隊列):先提交的任務先執行 后提交的后執行 內部只維護一個隊列
???? - Fair 公平調度器:所有的計算任務進行資源的平分,全局中如果只有一個job那么當前的job占用所有的資源
???? - Capacity(計算能力調度器):可以根據實際的job任務的大小,進行資源的配置
NodeManager:Nodemanager是yarn集群中正真資源的提供者,也是真正執行應用程序的容器的提供者,監控應用程序的資源情況(cpu、網絡、IO、內存)。并通過心跳向集群的主節點ResourceManager 進行匯報以及更新自己的健康狀況。同時也會監督container的生命周期管理,監控每個container的資源情況
MRAppMaster:為當前的job的mapTask和reduceTask向ResourceManager 申請資源、監控當前job的mapTask和reduceTask的運行狀況和進度、為失敗的MapTask和reduceTask重啟、負責對mapTask和reduceTask的資源回收。
Container :Container 是一個容器,一個抽象的邏輯資源單位。容器是由ResourceManager Scheduler 服務動態分配的資源構成的,它包括該節點上的一定量的cpu、網絡、IO、內存,MapReduce 程序的所有 Task 都是在一個容器里執行完成的。
hadoop 1.x: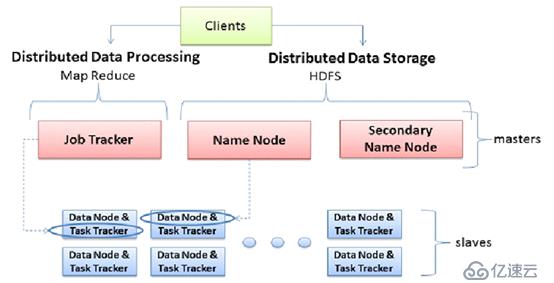

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





