溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
??HBASE是bigTable,(源代碼是Java編寫)的開源版本,是Apache Hadoop的數據庫,是建立在hdfs之上,被設計用來提供高可靠性,高性能、列存儲、可伸縮、多版本,的Nosql的分布式數據存儲系統,實現對大型數據的實時,隨機的讀寫請求。更是彌補了hive不能低延遲、以及行級別的增刪改的缺點。
?? HBASE依賴于hdfs做底層的數據存儲
?? HBASE依賴于MapReduce做數據計算
?? HBASE依賴于zookeeper做服務協調
?- 面向列,可以實現一個近實時的查詢的一個分布式的數據庫。
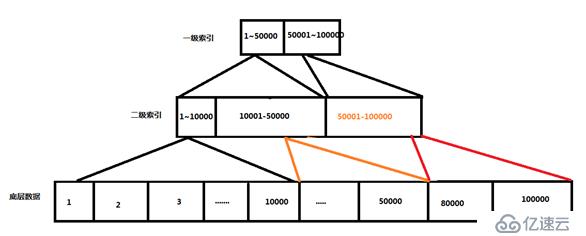
?- 索引,hbase的rowkey都是按照字典排序的
?- 查詢,查詢機制是通過索引+布隆過濾器實現
?- 它介于nosql和RDBMS之間,僅能通過主鍵和主鍵的range(范圍)來檢索數據。
?- hbase查詢數據功能很簡單,依然是以key-value數據庫,不支持join等復雜操作
?- 不支持復雜的事務,只支持行級事務(可通過 hive 支持來實現多表 join 等復雜操作)
?- 主要用來存儲結構化和半結構化的松散數據。
?- 無模式,每行都有一個可排序的主鍵和多個任意的列,列可以根據需要動態的增加,同一張表中不同的行可以有截然不同的列。
?- 大,一個表可以是10億行,上百萬列
?- 面向列,面向列(族)的存儲和權限控制,列(簇)獨立檢索。(提升查詢的性能)
?- 稀疏,對于空(null)的列,并不占用空間,因此,表可以設計非常稀疏
?- 無嚴格模式,每行都有一個可排序的主鍵和任意多的列,列可以根據需要動態的增加,同一張表中不同的行可以有截然不同的列。(讀寫的時候,都會做格式校驗)
??hbase以表結構的形式存儲數據。表由行和列組成,列劃分為若干個列簇。
??查詢數據的流程:
?????????表---rowkey---列簇----列---時間戳
??Rowkey:按照字典排序
??列簇:包含一組列,列在插入數據時指定,列簇在建表的時候指定
??列:一個列簇中會有多個列,并且可以不同
??時間戳:每一個列的值可以存儲多個版本的值,版本號就是時間戳,按照時間由近到遠排序。
特點:
??- RDBMS完全可以抽象成為一張二維表,表由行和列組成,有行和列確定一個唯一的值
??- HBASE本質是key-value數據庫,key是行鍵rowkey,value是所有的真實key-value的集合
??- HBASE也可以抽象成為一個四維表,四維分別由行健 RowKey,列簇 Column Family,列 Column 和時間戳 Timestamp 組成。
??- 一張HBASE的所有列劃分為若干個列簇
??- 每一個region的每一個列簇又是一個store,在hdfs的表現就是一個文件夾。
行鍵(rowkey):
??與Nosql數據庫一樣,rowkey是用于檢索記錄的主鍵,rowkey 行鍵可以是任意字符串(最大長度是 64KB,實際應用中長度一般為 10-100bytes),最好是16。在 HBase 內部,rowkey 保存為字節數組,HBase 會對表中的數據按照 rowkey 排序 (字典順序)
??訪問HBASE table中的行。只有三種方式:
???- 通過單個rowkey訪問
???- 通過rowkey的range(范圍)
???- 全表掃描
列簇:
??HBASE表中的每一個列,都歸屬于某個列簇。列簇是表的Schema 的一部分(而列不是),必須 在使用表之前定義好,而且定義好了之后就不能更改。列名都是以列簇為前綴,訪問控制、磁盤和內存的使用統計等都是在列簇層面進行的。
??注意:列簇越多,在取一行數據時所要參與 IO、搜尋的文件就越多,所以,如果沒有必要,不要 設置太多的列簇(最好就一個列簇)。
時間戳:
??在HBASE中通過rowkey 和 columns 確定的為一個存儲單元稱為 cell。每一個cell都保存著同一份數據的多個版本。版本通過時間戳來索引。時間戳的類型是 64 位整型。時間戳可以由 hbase(在數據寫入時自動)賦值,此時時間戳是精確到毫秒的當前系統時間。每個 cell 中,不同版本的數據按照時間倒序排序,即最新的數據排在最前面。
??為了避免數據存在過多版本造成的管理負擔,HBASE提供了兩種數據版本的回收方式:
???- 保存數據的最后n個版本(個數)
???-保存最近一段是時間內的版本(設置數據的生命周期 TTL)
單元格:
??在HBASE中通過rowkey 和 columns 確定的為一個存儲單元稱為 cell。由{rowkey,column(=<family>+< column>),version}組成一個cellCell中的數據是沒有類型的,全是字節碼形式存儲。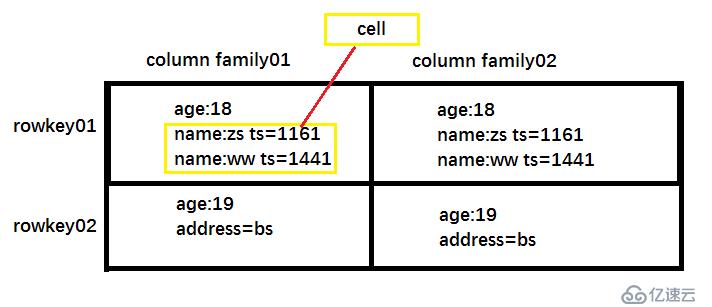
相同點:
??- HBASE和hive都是架構在hadoop之上,用hdfs做底層的數據存儲。用MapReduce做數據計算。
不同點:
??- hive是建立在hadoop之上的,為了減低Mapreduce編程的復雜度,而hbase是為了彌補hadoop對實時操作的缺陷
??- Hive的表示純邏輯表,因為hive本身并不能做數據存儲和計算,而是完全依賴于hadoop,hbaseHBASE是物理表,提供了一張超大的內存 Hash 表來存儲索引,方便查詢。
??- Hive是數據倉庫,需要全表掃描,就用hive,hive是文件存儲,HBase 是數據庫,需要索引訪問,則用 HBase,因為 HBase 是面向列的 NoSQL 數據庫
??- Hive 不支持單行記錄操作,數據處理依靠 MapReduce,操作延時高;HBase 支持單行記錄的 CRUD,并且是實時處理,效率比 Hive 高得多
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





