溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹TensorFlow 中的指標列與嵌入列如何理解,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
一般地,機器學習、深度學習 feed 進來的數據要求為數值型。如果某列取值為字符型,需要做數值轉換,今天就來總結下 TensorFlow 中的指標列和嵌入列。
指標列 ( indicator column ) 是指取值僅一個為 1,其他都為 0 的向量,它是稀疏的; 嵌入列 (embedding column) ,取值介于0和1之間,它是稠密的。
指標列,采取 one-hot 編碼方法,有多少類輸入就會得到一個多少維的向量。如果輸入類別為 4 類,那么可以編碼為如下,0,1,2,3 類分別編碼為4維的向量。
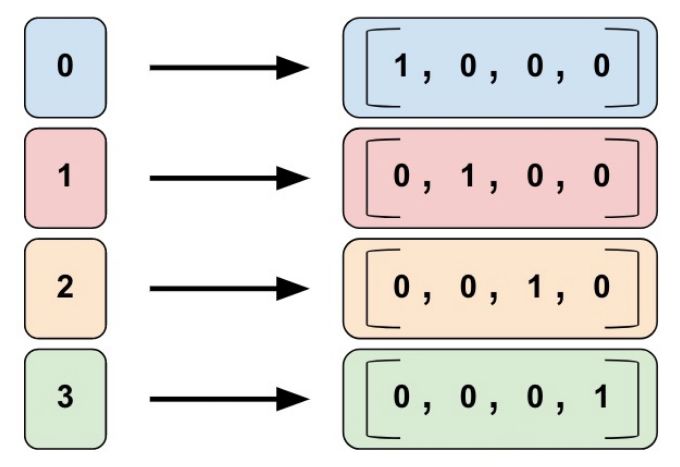
TensorFlow 中通過調用 tf.feature_column.indicator_column 創建指標列
categorical_column = ...
indicator_column = tf.feature_column.indicator_column(categorical_column)
但是,假設我們有一千萬個可能的類別,或者可能有十億個,而不是只有四個。出于多種原因,隨著類別數量的增加,使用指標列來訓練神經網絡變得不可行。
如何解決類別數量激增導致的指標列不可行問題?
使用嵌入列來克服這一限制,嵌入列并非將數據表示為很多維度的獨熱矢量,而是將數據表示為低維度普通矢量,其中每個單元格可以包含任意數字,而不僅僅是 0 或 1。通過使每個單元格能夠包含更豐富的數字,嵌入列包含的單元格數量遠遠少于指標列。
每個嵌入向量的維度是怎么確定的呢?嵌入矢量中的值如何神奇地得到分配呢?
1、設定詞匯表單詞個數為 1 萬。如果選用指標列,則每個單詞的取值為 1 萬維,采取嵌入列,每個單詞的維度僅為 10,這相比 one-hot 編碼絕對是低維度了,維度取值一般經驗公式是單詞個數的4次方根。
2、初始時,將隨機數字放入嵌入向量中,分配值在訓練期間進行,嵌入矢量從訓練數據中學習了類別之間的新關系。
TensorFlow 中通過調用 tf.feature_column.embedding_column 創建嵌入列,
categorical_column = ...
embedding_column = tf.feature_column.embedding_column(
categorical_column=categorical_column, dimension=dimension)
最后,以一個展示指標列和嵌入列的區別實例作為結尾,
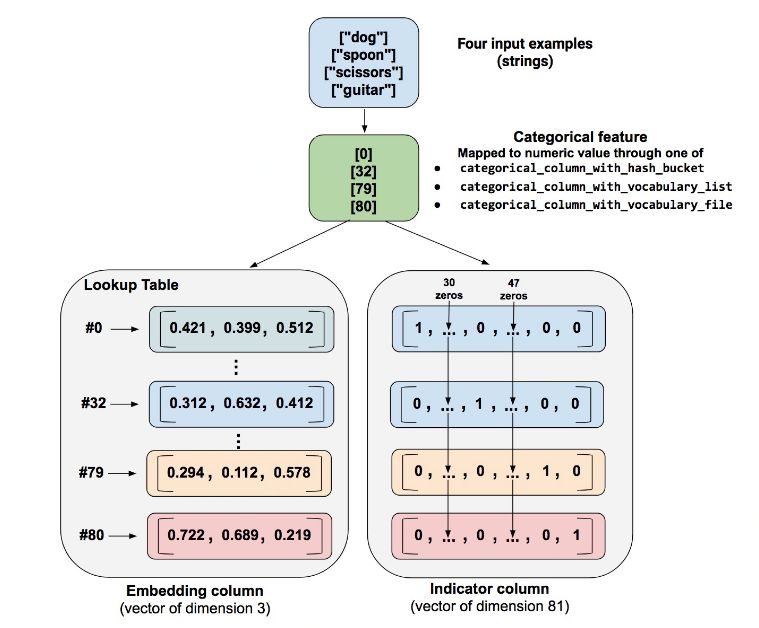
關于TensorFlow 中的指標列與嵌入列如何理解就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





