溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Hive SQL如何調優”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Hive SQL如何調優”這篇文章吧。
之前大家在網上總能看到hive調優中一定有這么一條,要避免使用distinct去重,代替法是group by。但是 是不是所有的情況下都是如此呢?看下面這個案例
select count(1) from(
select s_age
from student_tb_orc
group by s_age
) b
這里為了從學生表中統計年齡的枚舉值個數,但是為什么不用下面的這種distinct呢?
select count(distinct s_age)
from student_tb_orc
我們一般都會想數據量大了第一種能夠避免reduce端的數據傾斜,但事實上,不論數據量大小,都是下面的簡潔SQL效率更高。
「該作者跑的結果為47s 和 28s。」
這是為什么呢?
所以,「上面第一種SQL的寫法有點過度優化」。讓我們繼續看一下他們的執行流程圖:
第一種SQL執行流程圖如下: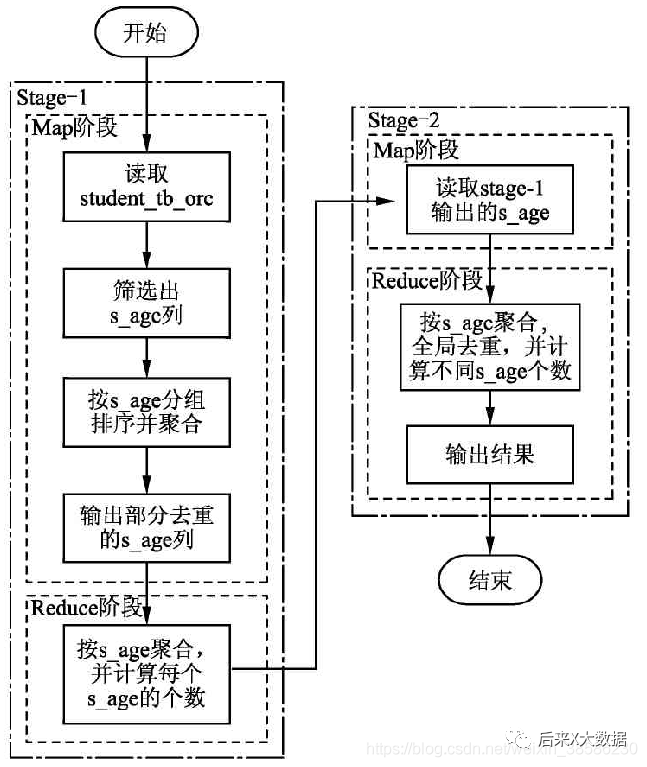 第二種SQL的執行流程圖如下:
第二種SQL的執行流程圖如下: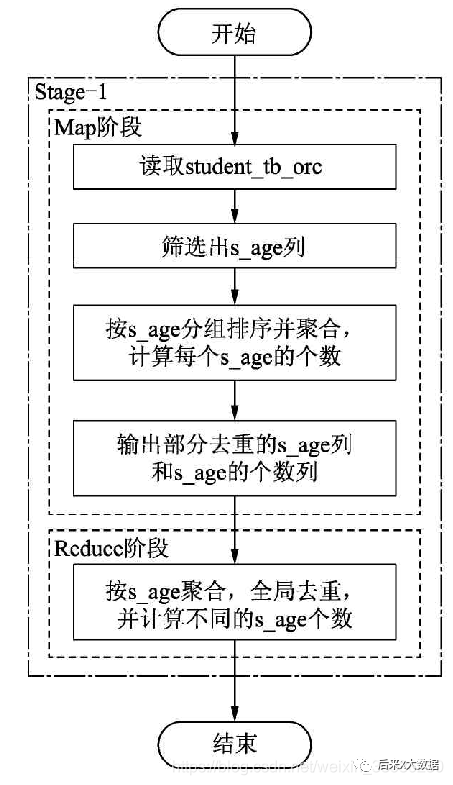 所以這2個SQL執行流程的對比圖如下:
所以這2個SQL執行流程的對比圖如下:
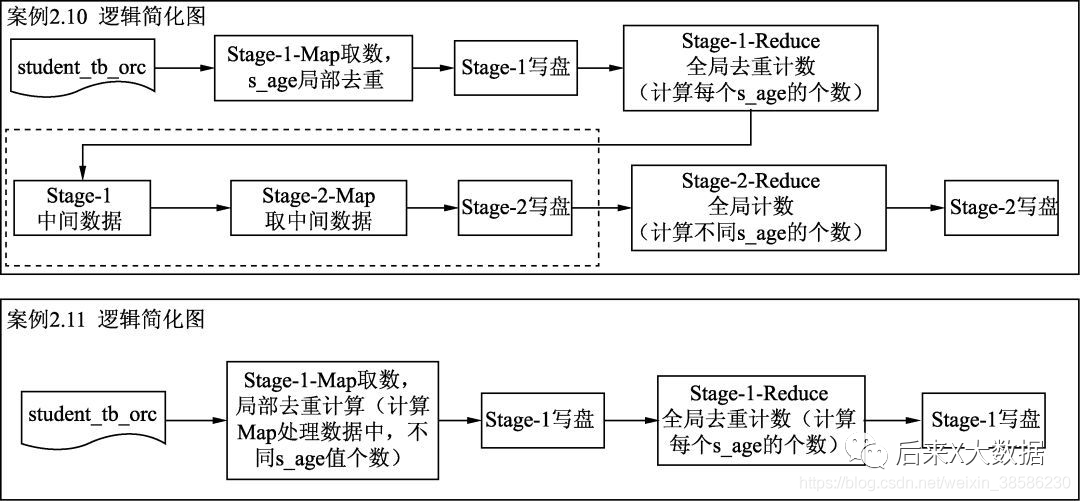 這兩個SQL執行出來的時間差主要集中在數據傳輸和中間任務的創建下,就是上圖的虛線框部分,因此通過distinct關鍵字比子查詢的方式效率更高。
這兩個SQL執行出來的時間差主要集中在數據傳輸和中間任務的創建下,就是上圖的虛線框部分,因此通過distinct關鍵字比子查詢的方式效率更高。
當然如果這里「采用Spark 引擎,就直接省去了Map1落盤和Reduce再去讀取中間數據的時間」,二者的運行時間差可能更短。但是從SQL同等復雜程度下,簡潔更優的角度來說,還是distinct更優。
「那么什么情況下第一種寫法的SQL會比第二種寫法的SQL效率更高呢?」
在有數據傾斜的情況下,第一種寫法的SQL方式更優。
當數據大到一定的量級時,第一種寫法的SQL有兩個作業,可以把處理邏輯分散到兩個階段中,即第一個階段先處理一部分數據,縮小數據量,第二個階段在已經縮小的數據集上繼續處理。
而第二種寫法的SQL,經過Map階段處理的數據還非常多時,所有的數據卻都需要交給一個Reduce節點去處理,就好比千軍萬馬過獨木橋一樣,不僅無法利用到分布式集群的優勢,還要浪費大量時間在等待,而這個等待的時間遠比第一種寫法的SQL多個MapReduce所延長的流程導致額外花費的時間還多。
「但是,如前面所說,在Hive 3.0中即使遇到數據傾斜,第二種寫法的SQL將hive.optimize.countdistinct設置為true,則整個寫法也能達到第一種寫法的SQL的效果。」
我嘗試在自己的集群上跑同樣的SQL,用Spark 引擎,可能因為數據量小的原因,相差不大,都是4s左右。
需求:從學生表中找到每個年齡段最晚出生和最早出生的人的生日日期,寫入一個表中;
于是SQL如下:
INSERT into table student_stat partition(tp)
select
s_age,
min(s_birth) stat,
'min' tp
from student_tb_txt
group by s_age
union all
select
s_age,
max(s_birth) stat,
'max' tp
from student_tb_txt
group by s_age;
但是這個SQL其實是5個job對應了4個MR任務,效率是比較低的。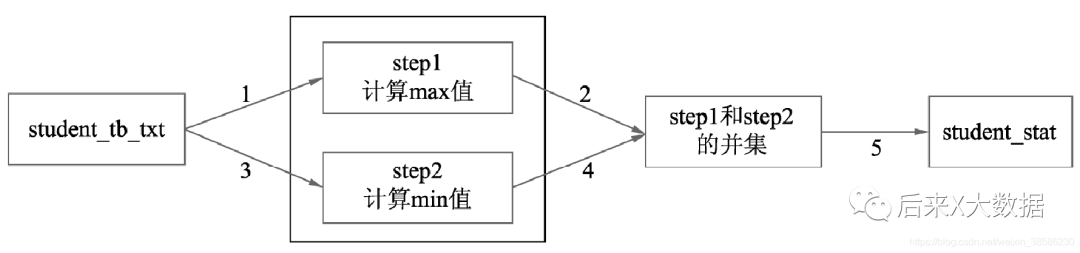 那怎么優化呢?那能不能只讀一次表,就能都計算出最小值和最大值,然后依次寫入最后的結果表,不需要中間并集。看如下SQL
那怎么優化呢?那能不能只讀一次表,就能都計算出最小值和最大值,然后依次寫入最后的結果表,不需要中間并集。看如下SQL
from student_tb_txt
INSERT into table student_stat partition(tp)
select s_age,min(s_birth) stat,'min' tp
group by s_age
insert into table student_stat partition(tp)
select s_age,max(s_birth) stat,'max’ tp
group by s_age;
「這種也叫做multi-table-insert語法,多路輸出」 在如上的SQL執行時,其實也啟動了1個Job ,所以效率的提升還是非常顯著的。
在如上的SQL執行時,其實也啟動了1個Job ,所以效率的提升還是非常顯著的。
以上是“Hive SQL如何調優”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





